由于流量红利逐渐消退,越来越多的广告企业和从业者开始探索精细化营销的新路径,取代以往的全流量、粗放式的广告轰炸。精细化营销意味着要在数以亿计的人群中优选出那些最具潜力的目标受众,这无疑对提供基础引擎支持的数据仓库能力,提出了极大的技术挑战。
本篇内容将聚焦字节跳动OLAP引擎技术和落地经验,以字节跳动内部场景为例,具体拆解广告业务的实现逻辑和业务效果。
广告精准投放场景
广告投放过程一般包含数据收集->数据整合->人群圈选->广告投放->反馈分析等关键流程,人群圈选是广告精准投放的关键步骤,它帮助确定广告目标受众,辅助投放平台根据不同受众和广告目标优化投放策略,提升广告收益;
人群预估
人群预估主要是根据一定的圈选条件,确认命中的用户数目。在广告精准投放过程中,广告主需要知道当前选定的人群组合中大概会有多少人,用于辅助判断投放情况进而确定投放预算,通常要求计算时间不能超过 5 秒。
广告投放
广告精准投放过程中遇到的问题与痛点:
1. 数据预估: 广告主需要对选定的人群组合进行预估,以便判断投放情况并确定投放预算。但人群包数据量多,基数大。平台的用户数上亿,仅抖音的 DAU 就几亿,抖音、头条对应的人群包在亿级别,早期的预估版本采用ElasticSearch,但由于数据过于庞大,只能采用1/10抽样存储,导致10%的误差,业务难以接受。
2. 查询性能: 广告主可以设定一个非常复杂的圈选条件,导致计算复杂(单次计算可能包含几百上千个人群包),Hive和ES等方案在处理大数据量时,查询速度会变得非常慢,如果需要查询某个广告主的所有用户,需要扫描整个用户库,而这个过程可能需要几分钟甚至几个小时,无法满足实时性要求。
3. 存储空间大: Hive和ES等方案需要额外的索引结构,导致存储空间变大,从而增加了存储成本。例如,如果需要对用户属性进行索引,就需要额外的存储空间来存储索引数据。
4. 不支持高并发: Hive和ES等方案在处理高并发请求时,容易出现性能问题,无法支持高效的广告投放。例如,如果同时有多个广告主需要查询用户信息,就可能会出现查询阻塞或响应延迟等问题。
5. 数据查询效率: 采用ClickHouse支持预估,但随着数据量的增长,ClickHouse在当前存储引擎的支持下也难以保证查询时间。这导致了数据查询效率的问题,影响了用户体验。
ByteHouse BitEngine方案
方案简介
新查询引擎
基于高性能、分布式特点,ClickHouse可以满足大规模数据的分析和查询需求,因此研发团队以开源ClickHouse为基础,研发出火山引擎云原生数据仓库ByteHouse,并在其中定制一套处理模型——BitEngine,用于解决集合的交并补计算在实时分析场景中的性能提升问题。
针对广告人群预估业务开发的新查询引擎,基于ByteHouse提供的MergeTree Family系列引擎,添加了新的bitmap64类型和一系列的相关聚合函数。BitEngine提供的bitmap64类型适合存储和计算大量的用户ID之间的关系;在广告人群预估业务中,bitmap64类型用于存储人群包数据,然后将人群包之间的交并补计算转化为bitmap之间的交并补,从而达到远超普通查询的性能指标。
实现步骤
创建一个bitmap64类型,可以将用户ID直接存储在bitmap中,提供一系列交并补的聚合计算,并且还希望可以充分利用多核CPU的并行计算能力,由此我们设计了BitEngine。示例如下
CREATE TABLE cdp.tag_uids_map (
tags String,
uids BitMap64 BitEngineEncode
)ENGINE = HaMergeTree('/clickhouse/xxxx/{shard}', '{replica}')
ORDER BY tag
tag_uids_map存储格式如下
| tag | uids |
|---|---|
| A | {10001,20001,30001,40001,50001,60001,70001,80001,90001} |
| B | {10001,20001,20002,20003,20004,20005,20006,20007,20008} |
要查询 A&B 的结果 SQL 为
SELECT bitmapCount('A&B') FROM tag_uids_map
BitEngine实现逻辑
核心思想
对数据做分区划分和编码,保证每个区间的数据之间不存在交集,然后使用roaring bitmap保存数据; 计算时每个分区的数据可以独立的做聚合计算,充分利用机器的并行能力,每个分区内部的聚合计算就是多个bitmap之间的交并补,利用roaring bitmap高效的交并补计算降低CPU和内存的使用; 通过字典将编码的结果反解回来,数据编码是为了让数据的分布尽可能稠密,roaring bitmap在存储和计算的时候就可以获得更好的性能。
业务应用
业务关键要素
人群包:广告主自定义规则计算出来的人群数据,标签是dmp团队根据市场需求定义的人群数据。 标签ID:每天定时根据产出规则更新一次,人群ID是自增的,每天根据广告主需求进行新建计算。
统一编码
为了对标签数据和人群数据的uid统一编码,编码服务先将标签数据中的uid和人群数据中的uid提取出来进行统一编码,将全量uid均匀hash到一万个桶中,桶编号为i[0<=i<=9999],uid在每个桶内由1开始顺序编码,每个桶的范围为i*2^40 - (i+1)*2^40。 uid数据每天都在增加,因此需要支持增量编码, 编码服务每天会先获取增量uid,hash后顺序放置到每个桶中。
数据存储
完成编码后,会先把字典数据统一写入hive表中,便于字典的各种使用场景。 在数据经过分区和编码之后,ClickHouse可以以多种数据导入格式将数据以bitmap64类型存入磁盘。
数据计算
BitEngine如何充分利用计算机的并行能力完成每个分区多个bitmap之间的交并补计算?
存在问题:
假设存在四个bitmap,分别为a,b,c,d;则(a | c) & (b | d)不一定等于(a & b) | (c & d)。
人群包
人群包A = [10001, 20001,30001,40001,50001],人群包B = [10001, 20001,20002,20003,20004]
期望结果
通过BitEngine计算A&B = [10001, 20001]
设计方案
人群包按照一定的规则划分为多个区间,任意两个区间之间的人群包没有交集 一个计算线程只读取同一个区间的人群包进行计算,得到一个中间结果 最终的中间结果只需要简单的进行bitmap or计算即可
对于这个设计,BitEngine需要保证数据的读取和计算是严格按照区间进行。BitEngine在数据读取时会为每一个文件构建一个读任务,由一个线程调度模块完成整个任务的调度和读取,这个线程调度模块的调度原则是:
不同分区的文件不会交叉读取(ClickHouse的文件读取粒度小于文件粒度,会存在多个线程先后读一个文件的情况,一个分区也可能由多个文件组成),即一个线程只会读A_1,B_1,不会在这之间读取A_2或者B_2。 一个分区读取完成后,可以立即触发聚合计算,执行bitmap之间的计算逻辑,获得中间结果。即A_1,B_1 读取完成后,可以立即计算A_1 & B_1。 线程计算完中间结果后,可以继续读其他文件
BitEngine完成所有中间结果的计算后,会按照结果的输出要求做一次数据合并:
如果需要计算的结果是bitmap的基数的时候,BitEngine直接将各个中间结果的基数相加 如果计算结果需要的是bitmap,BitEngine直接将所有的bitmap合并起来,这里合并指的是bitmap or计算
业务效果
广告业务效果
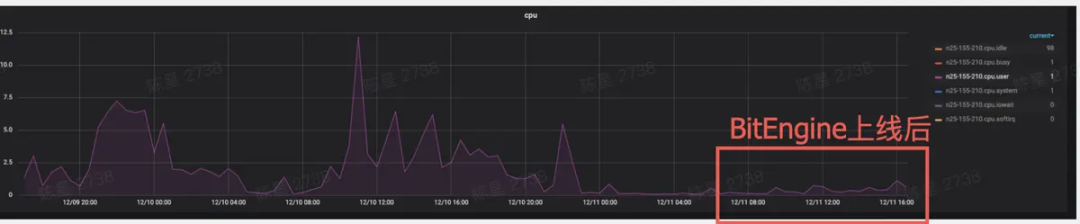
数据存储空间缩小了 3 倍+ 导入时间缩小了 3 倍+ 查询 avg/pct99/max 都下降明显,pct99 从 5 s 降低到 2 s CPU 使用下降明显,PageCache 节省 100 G+ 查询误差从10% 下降到 0%
BitEngine上线前后查询耗时监控
BitEngine上线后CPU负载对比
PageCache 使用情况(lower is better)
案例总结
BitEngine上线使用后,经过大量调优,在广告人群预估业务上取得了良好收益。目前,BitEngine已经集成在火山引擎云原生数据仓库ByteHouse中对外输出。火山引擎ByteHouse主要为用户提供极速分析体验,能够支撑实时数据分析和海量数据离线分析,具备便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,目前已经与中国地震台网中心、海王集团、莉莉丝游戏、极客邦科技等诸多行业企业达成合作,深度助力各个行业数字化转型。未来,BitEngine将继续增强功能以支撑广告业务场景,包括:引擎集成数据编码,使编码对用户透明;提供细粒度的缓存以缓存部分重复表达式的计算结果;优化表达式解析等。
如有侵权请联系:admin#unsafe.sh