

Too Long; Didn't Read
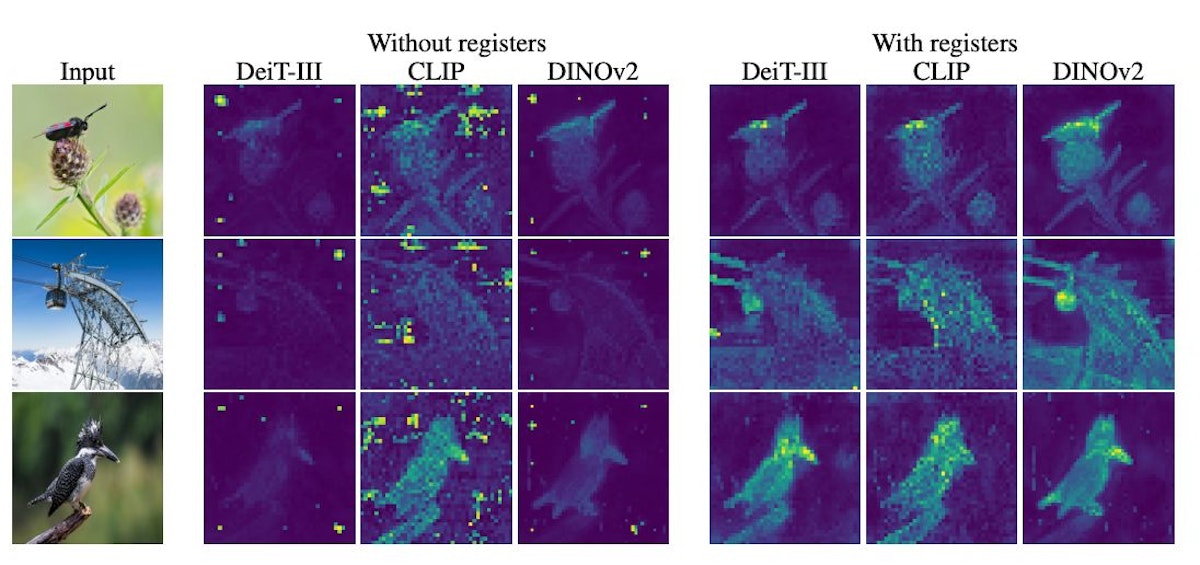
Vision Transformers (ViTs) have gained popularity for image-related tasks but exhibit strange behavior: focusing on unimportant background patches instead of the main subjects in images. Researchers found that a small fraction of patch tokens with abnormally high L2 norms cause these spikes in attention. They hypothesize that ViTs recycle low-information patches to store global image information, leading to this behavior. To fix it, they propose adding "register" tokens to provide dedicated storage, resulting in smoother attention maps, better performance, and improved object discovery abilities. This study highlights the need for ongoing research into model artifacts to advance transformer capabilities.



RELATED STORIES





L O A D I N G
. . . comments & more!