2023-10-3 10:38:16 Author: isc.sans.edu(查看原文) 阅读量:11 收藏
LLMs have become very popular recently. I've been running them on my home PC for the past few months in basic scenarios to help out. I like the idea of using them to help with forensics and Incident response, but I also want to avoid sending the data to the public LLMs, so running them locally or in a private cloud is a good option.
I use a 3080 GPU with 10GB of VRAM, which seems best for running the 13 Billion model (1). The three models I'm using for this test are Llama-2-13B-chat-GPTQ , vicuna-13b-v1.3.0-GPTQ, and Starcoderplus-Guanaco-GPT4-15B-V1.0-GPTQ. I've downloaded this model from huggingface.co/ if you want to play along at home.
Llama2 is the latest Facebook general model. Vicuna is a "Fine Tuned" Llama one model that is supposed to be more efficient and use less RAM. StarCoder is trained on 80+ coding languages and might do better on more technical explanations.
There are a bunch of tutorials to get these up and running, but I'm using oobabooga_windows to get all of this quickly. The best solution if you are going to play with many of these is running docker w/ Nvidia pass-through support.
When thinking about how to use this, the first thing that comes to mind is supplementing knowledge for responders. The second is speeding up technical tasks, and the third is speeding up report writing. These are the three use cases we are going to test.
Limitations
The most significant limitation is the age of the data these models are trained on. Most models are around a year old, so the latest attacks will not be searchable directly. LLMS can be outright wrong often, too. And the smaller the model it's trained on, the more facts will be wrong.
Test Scenarios
1.SQL injection
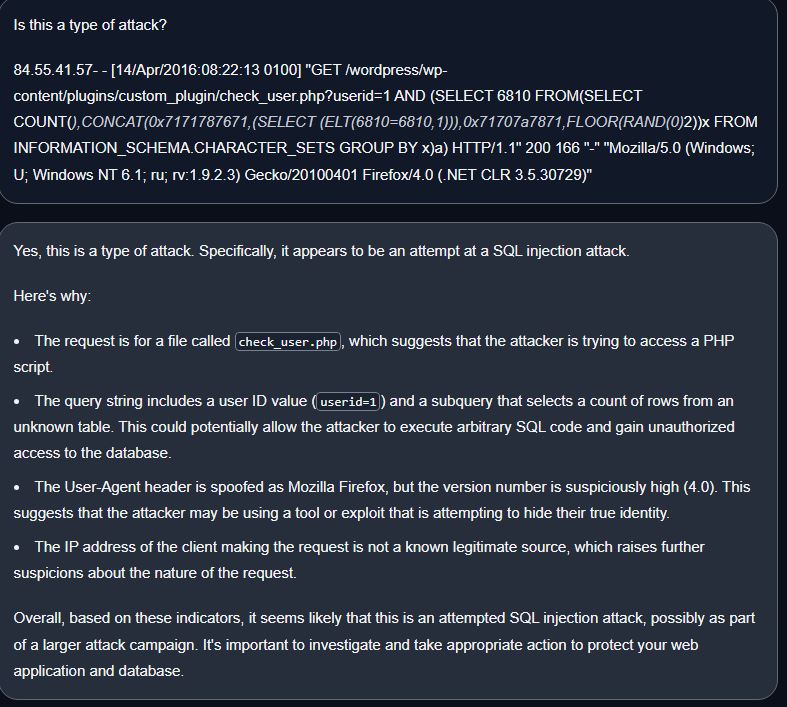
Is this a type of attack?
84.55.41.57- - [14/Apr/2016:08:22:13 0100] "GET /wordpress/wp-content/plugins/custom_plugin/check_user.php?userid=1 AND (SELECT 6810 FROM(SELECT COUNT(*),CONCAT(0x7171787671,(SELECT (ELT(6810=6810,1))),0x71707a7871,FLOOR(RAND(0)*2))x FROM INFORMATION_SCHEMA.CHARACTER_SETS GROUP BY x)a) HTTP/1.1" 200 166 "-" "Mozilla/5.0 (Windows; U; Windows NT 6.1; ru; rv:1.9.2.3) Gecko/20100401 Firefox/4.0 (.NET CLR 3.5.30729)"
2. All the Apache logs from this blog (2)
Is there anything unusual in this Apache log for a wordpress server?
3.Windows malware sanario
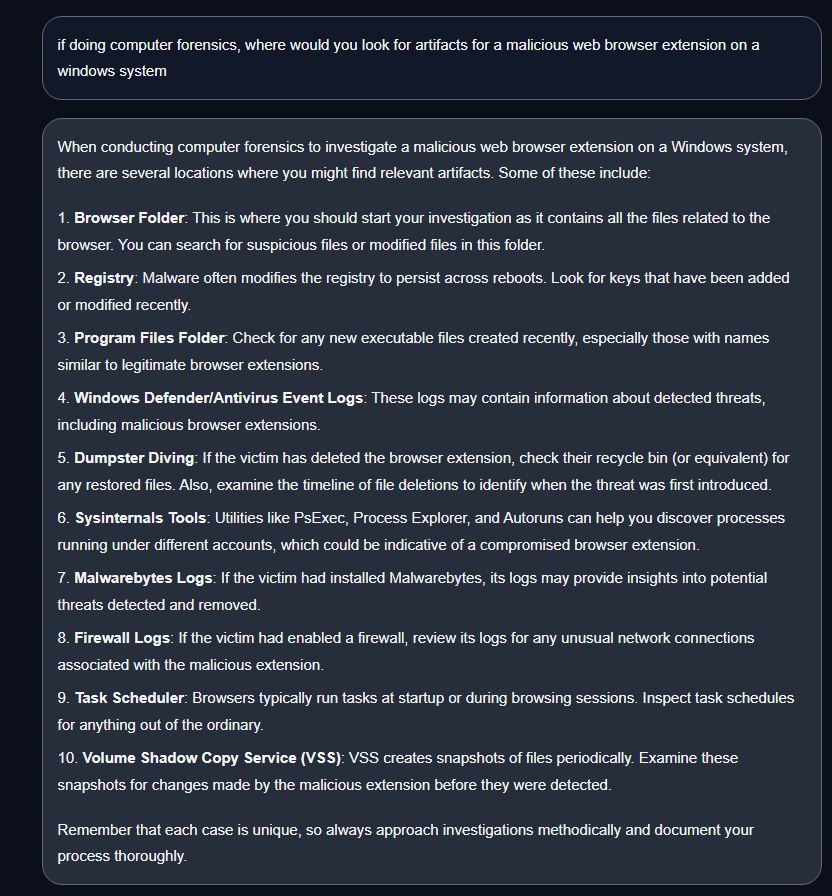
A. If doing computer forensics, where would you look for artifacts for a malicious web browser extension on a Windows system?
B. What is CVE-2021-44228. How do you detect attacks? How do you defend against it?
C. What should be the parent process of firefox.exe on Windows?
4. Write a report.
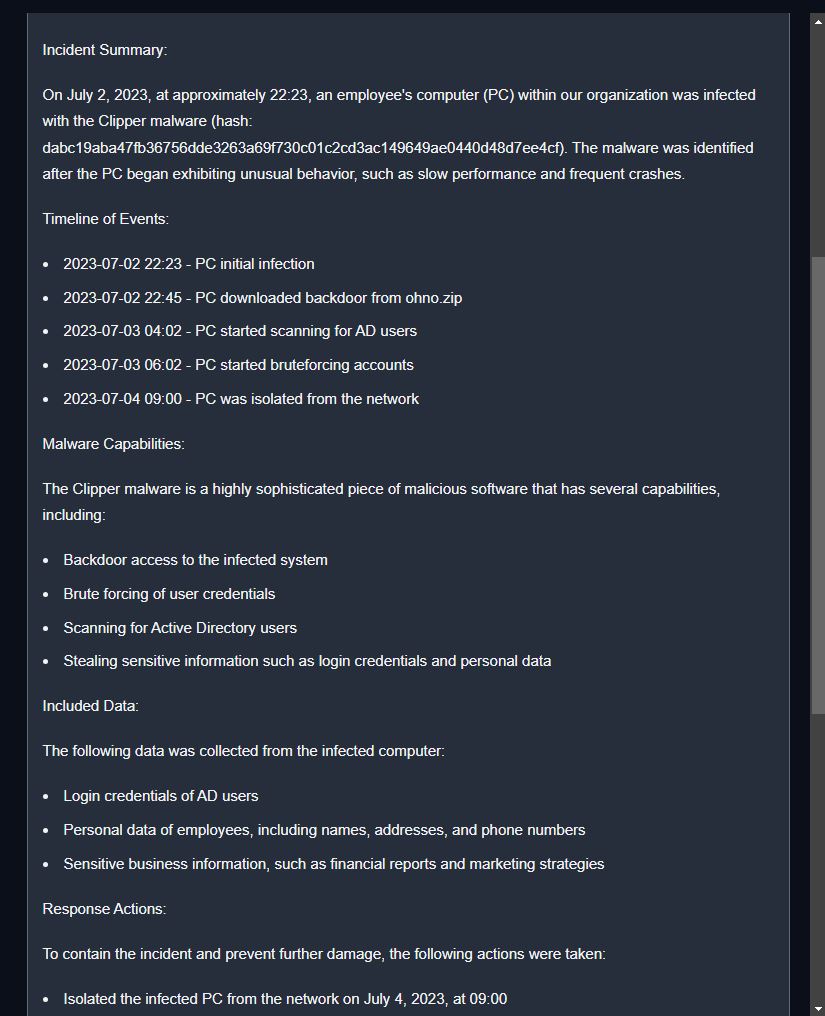
Write an incident response report about an infected computer with clipper malware. Include a summary of the malware capabilities and the included data below.
Malware hash: dabc19aba47fb36756dde3263a69f730c01c2cd3ac149649ae0440d48d7ee4cf
Timeline of events:
2023-07-02 22:23- PC initial infection
2023-07-02 22:45- PC downloaded backdoor from ohno.zip
2023-07-03 04:02- Pc started scanning for AD users
2023-07-03 06:02- PC started brute-forcing accounts
2023-07-04 09:00- PC was isolated from the network
Results
1. SQL Injection:
LLAMA2- Said SQL injection and gave reasons. (B)
Vicuna- SQL injection and gave reasons (B)
Star- SQL injection and explanation (B)
LLAMA 2 Answer.
2.Apache logs:
LLAMA2- Was wrong but broke down the logs (C-)
Vicuna-Broke down logs but wrong (C-)
Star-Correctly identified what was accessed. (B-)
Star Response.
3A.Malicious browser extension:
LLama2-Gave registry keys, but not all correct or useful (C)
Vicuna-Very Bad (F)
Star-Bad(F)
Vicuna Response.
3B.CVE-2021-44228:
LLAMA2: Completely wrong on all levels. Said it was SSL vul. (F)
Vicuna Completely wrong (F)
Star:Correct except detection (B)
Vicuna Response.

3C.Parent Process:
LLama2-Was incorrect said csrss.exe (F)
Vicuna- Completely wrong (F)
Star-very wrong (F)
Malware report:
LLAMA2: The report was ok, but it would need a lot of changes. (C-)
Vicuna- The report was ok, but would need a lot of changes. (C-)
Star-Report made up many facts (D-)
LLama 2 response.
Total Tally
LLama2-B,C-,F,F,C-
Vicuna-B,C-,F,F,C-
Star-B,B-,F,B,F,D-
Overall, these small models did poorly on this test. They do a good job on everyday language tasks, like giving text from an article and summarizing it or helping with proofreading. A specific version of Star is just for Python, which also works well. As expected for small models, the more specific they are trained, the better the results. I want to work on training one for incident response and forensics in the coming months.
Anyone else doing testing with local or private LLMS? Leave a comment.
(1)https://www.hardware-corner.net/guides/computer-to-run-llama-ai-model/
(2) https://www.acunetix.com/blog/articles/using-logs-to-investigate-a-web-application-attack/
--
Tom Webb
如有侵权请联系:admin#unsafe.sh