随着大数据处理需求的不断增加,更低成本的存储和更统一的分析视角变得愈发重要。数据仓库作为企业核心决策支持系统,如何接入外部数据存储已经是一个技术选型必须考虑的问题。也出于同样的考虑,ByConity 0.2.0 中发布了一系列对接外部存储的能力,初步实现对 Hive 外表及数据湖格式的接入。
支持 Hive 外表
随着企业数据决策的要求越来越高,Hive 数据仓库已成为了许多组织的首选工具之一。通过在查询场景中结合 Hive, ByConity 可以提供更全面的企业决策支持和打造更完整的数据管理模式。因此从 0.2.0 版本开始,ByConity 可以通过建立外表的形式访问 Hive 数据。
原理和使用
ByConity 主要的表引擎为 CnchMergeTree。在连接外部存储时,需要基于不同的外表引擎。比如创建 Hive 外表时,需要通过 CnchHive 引擎读取 Parquet 以及 ORC 格式的 Hive 数据。
CREATE TABLE tpcds_100g_parquet_s3.call_center
ENGINE = CnchHive('thrift://localhost:9083', 'tpcds', 'call_center')
SETTINGS region = '', endpoint = 'http://localhost:9000',
ak_id = 'aws_access_key', ak_secret = 'aws_secret_key', vw_default = 'vw_default'
通过指定 HiveMetastore uri,Hive database 以及 Hive table。ByConity 会获取并解析 Hive table 元数据,自动推断表的结构(列名,类型,分区)。查询时 server 通过 List 远端文件系统,来获取需要读取的文件,之后 server 下发文件给 workers,worker 负责从远端文件系统读取数据,整体的执行流程与 CnchMergeTree 基本一致。
通过配置 disk_cache,worker 端可以把远端的文件存入本地磁盘缓存来加速下一次读取的速度。
性能优化
此外,CnchHive 还实现了一些重要的性能优化手段以达到与 Presto/Trino 同水平的外表性能:
支持分区剪枝和分片级别剪枝
分区剪枝和分片级别剪枝是 Hive 的性能优化技术。分区剪枝允许 Hive 在查询时仅扫描与查询条件相关的分区,而不是全表扫描,从而大大减少查询的执行时间。对于一些文件格式,例如 Parquet,可以通过读取文件中每个 row group 的 minmax value,对 row groups 进行裁剪,进一步减少读取的数据量。
Hive 统计信息集成 优化器
CnchHive 引入了统计信息集成优化器,它可以根据数据的统计信息自动选择最佳的执行计划。这使得查询的执行更加智能和高效,同时减少了手动调整查询计划的工作量。统计信息集成优化器可以在 benchmark 中显著提高查询性能。
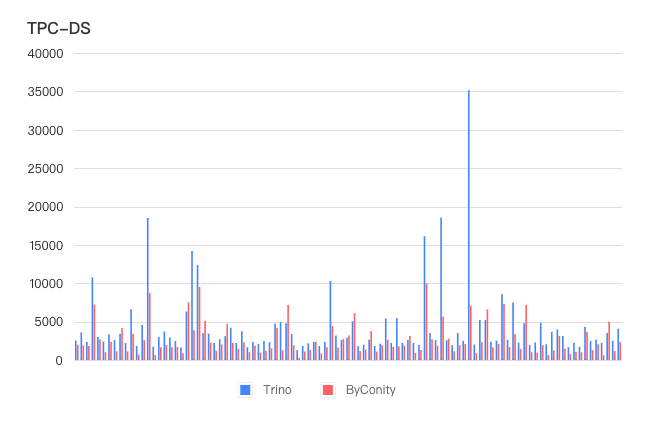
Benchmark ( ByConity vs Trino )
TPC-DS(Transaction Processing Performance Council Decision Support)是一个标准化的决策支持基准,用于评估数据仓库系统的性能。ByConity 0.2.0 发布的 CnchHive 引擎通过优化查询执行计划,不仅能完整跑通 TPC-DS 基准测试,同时在性能方面表现出色。
测试信息:
部署模式:Kubernetes 部署,基于 AWS EC2 r5.12large 机型
物理资源规模:4 Worker(48cpu, 256Gb mem)
测试使用的参数:
enable_optimizer : 开启优化器 dialect_type ANSI: 使用标准 Ansi SQL s3_use_read_ahead: 关闭 S3 的 ReadAhead 功能 remote_read_min_bytes_for_seek: 两个读之间如果间隔小于 1MB, 不会 seek disk_cache_mode=SKIP_DISK_CACHE 关闭 worker 的本地磁盘缓存,模拟纯冷读场景 parquet_parallel_read=1 使用 parquet 的 parallel read enable_optimizer_fallback=0 优化器执行失败直接返回报错,用于测试场景 exchange_enable_multipath_reciever=0 执行层的参数优化 图例补充:纵坐标单位 毫秒,横坐标单位 TPC-DS 查询语句标号;
支持 Hudi 外表
Hudi 主要概念
从实际的业务场景出发,对于数据湖数据的需求可以先分为两大类:读偏好和写偏好;所以 Apache Hudi 提供了两种类型的表:
Copy On Write 表:简称 COW,这类 Hudi 表使用列文件格式(例如 Parquet)存储数据,如果有数据更新,则会重写整个 Parquet 文件,适合读偏好的操作; Merge On Read 表:简称 MOR,这类 Hudi 表使用列文件格式(例如 Parquet)和行文件格式(例如 Avro)共同存储数据。一般 MOR 表是用列存存储历史数据,行存存储增量和有更新的数据。数据更新时,先写入行存文件中,然后进行压缩,根据可配置的策略以同步或异步方式生成列式存储文件,适合写偏好的操作;
对于这两种不同类型的表和场景,Hudi 提供了不同的查询方式:
| 类型 | 查询场景 | 表类型 |
|---|---|---|
| Snapshot Queries快照查询 | 查询最新 COMMIT 的快照数据,即全部的数据; | COW & MOR |
| Incremental Queries增量查询 | 查询给定 COMMIT 之后的最新数据,即查询指定时间范围内的新增或修改的数据; | COW & MOR |
| Read Optimized Queries读取优化查询 | 只能查询到给定 COMMIT 之前所限定范围的最新数据,即仅查询 MOR 表中的列存数据; | 仅 MOR |
补充说明:Read Optimized Queries 是对 MOR 表类型快照查询的优化,通过牺牲查询数据的时效性,来减少在线合并日志数据产生的查询延迟。
原理和使用
原理概述
ByConity 实现了对 COW 表的进行快照查询。在开启 JNI Reader 后可以支持 MoR 表的读取。Hudi 支持同步 HiveMetastore,因此 ByConity 可以通过 HiveMetastore 感知 Hudi 表。
普通 CoW 表可以直接使用 CnchHive 引擎进行查询。
CREATE TABLE hudi_table
ENGINE = CnchHive('thrift://localhost:9083', 'hudi', 'trips_cow')
开启 JNI Reader 后,ByConity 可以通过 CnchHudi 表引擎来读取 Hudi CoW 以及 MoR 表。
CREATE TABLE hudi_table
ENGINE = CnchHudi('thrift://localhost:9083', 'hudi', 'trips_cow')
对于 Hudi MoR 表,ByConity 引入 JNI 模块来调用 Hudi Java Client 读取数据。Java 读取的数据会写入内存中的 arrow table,并且通过 Arrow C Data Interface 实现内存数据在 Java 与 C++之间的交换 , C++把 arrow table 转换成 Block 的数据进行后续的数据处理。
通过 Hudi Docker 快速上手
https://hudi.apache.org/docs/docker_demo/ 配置 Hudi 的 docker 环境后,确保 ByConity 集群连接 hivemetastore 后,可在 ByConity 中进行建 Hudi 外表及查询操作。
CREATE TABLE hudi.stock_ticks_mor_rt
ENGINE = CnchHudi('thrift://hivemetastore:9083', 'default', 'stock_ticks_mor_rt')-- MOR 查询
SELECT
symbol,
max(ts)
FROM stock_ticks_mor_rt
GROUP BY symbol
HAVING symbol = 'GOOG';
┌─symbol─┬─max(ts)─────────────┐
│ GOOG │ 2018-08-31 10:59:00 │
└────────┴─────────────────────┘
Multi-Catalog
透明的 Catalog 设计
Multi-Catalog 设计的目的是为了更方便地连接到多个外部数据目录,以增强 ByConity 的数据湖分析和外表查询功能。在数据架构设计上,核心的数据对象依然只有数据库和表。将 Catalog 信息在处理的时候嵌入到数据库名字中, 根据不同的数据库的命名模式来实现对应的处理。此类设计可以透明的兼容之前已经创建的库表元数据,仅就新增的外部数据目录进行更新。
比如,创建 Hive 的 catalog 后,如果 query 的表名中带了 hive 的 catalog 名字,就会走 external catalog 相关的逻辑,从 Hive Metastore 中获取库表相关信息。查询方式如下所示。
select * from hive_s3.tpcds.call_center
Multi-Catalog 便捷性
多 Catalog 的设计允许用户在同一个 Hive 实例中同时连接多个不同的存储和元数据服务,而不必为每个存储创建单独的 Hive 实例。这简化了数据管理和查询的复杂性,使组织能够更好地管理和利用其多样化的数据资源。目前已经支持的外部 Catalog 有:Hive,Apache Hudi,AWS Glue。
用户可以使用创建一个基于 Hive 和 S3 存储的 Catalog
create external catalog hive_s3
properties
type='hive',
hive.metastore.uri = 'thrift://localhost:9083',
aws.s3.region= 'aws_s3_region',
aws.s3.endpoint = 'http://localhost:9000',
aws.s3.access_key = 'aws_access_key',
aws.s3.secret_key = 'aws_secret_key'
然后使用三段式的命名来直接访问 Hive 外表
select * from hive_s3.tpcds.call_center;
也可以使用 query 来查看 external catalog 相关的信息
show create external catalog hive_s3; // display information releated to hive_s3
show databases from hive_s3; // show databases in hive_s3
show tables from hive_s3.tpcds; // show tables in tpcds database in hive.
show create external catalog hive_s3;
show databases from hive_s3;
show tables from hive_s3.tpcds;
未来规划
因为越来越多的数据需求时需要整合不同的数据存储,ByConity 会持续丰富对接数据湖和外部存储的能力,增强与上下游工具的集成。2023 年路线图可以查看 Github 上的讨论:https://github.com/ByConity/ByConity/issues/26。同时我们也会重点考虑先投入以下内容:对接 Iceberg,DeltaLake 等更多数据湖格式;引入 Native reader 提高 Parquet 文件读取效率;优化文件分配策略,使得每个 worker 的 workload 更加均匀等。
欢迎加入社区,与我们共建
ByConity 项目 GitHub 地址:
https://github.com/ByConity
用户手册:
https://byconity.github.io/zh-cn/docs/introduction/background-and-technical-architecture
扫码添加小助手
如有侵权请联系:admin#unsafe.sh