谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。
传统的数据转换过程一般采用Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。现在,以火山引擎ByteHouse为例的云原生数据仓库,凭借其强大的计算能力、可扩展性,开始全面支持Extract-Load-Transform (ELT)的能力,从而使用户免于维护多套异构系统。具体而言,用户可以将数据导入后,通过自定义的SQL语句,在ByteHouse内部进行数据转换,而无需依赖独立的ETL系统及资源。
火山引擎ByteHouse是一款基于开源ClickHouse推出的云原生数据仓库,本篇文章将介绍ByteHouse团队如何在ClickHouse的基础上,构建并优化ELT能力,具体包括四部分:ByteHouse在字节的应用、ByteHouse团队做ELT的初衷、ELT in ByteHouse实现方案、未来规划。
ByteHouse 在字节的应用
关于 ByteHouse
ByteHouse 的发展
从2017年开始,字节内部的整体数据量不断上涨,为了支撑实时分析的业务,字节内部开始了对各种数据库的选型。经过多次实验,在实时分析版块,字节内部决定开始试水ClickHouse。
2018年到2019年,字节内部的ClickHouse业务从单一业务,逐步发展到了多个不同业务,适用到更多的场景,包括BI 分析、A/B测试、模型预估等。
在上述这些业务场景的不断实践之下,研发团队基于原生ClickHouse做了大量的优化,同时又开发了非常多的特性。
2020年, ByteHouse正式在字节跳动内部立项,2021年通过火山引擎对外服务。
截止2022年3月,ByteHouse在字节内部总节点数达到18000个,而单一集群的最大规模是2400个节点。
ByteHouse 产品
在火山引擎官网的产品页中,我们可以搜到ByteHouse产品(如下图):
ByteHouse产品可以分为两个形态:
企业版:PaaS模式、全托管、租户专属资源。 数仓版:SaaS模式,在这个模式中,使用者可以免运维。用户通过控制台建表、导数据以及使用查询功能。
在数据量较小、使用较为简单的情况下,用户可以先试用企业版本,如果之后集群规模变大、运维压力较大,亦或是扩展能力要求变高,那么就可以转用到纯算分离、运维能力更强的CDW上来,也就是我们刚刚提及的数仓版。
应用场景
数据洞察
数据洞察是支持千亿级别数据自助分析的一站式数据分析及协作平台,包括数据导入以及整合查询分析,最终以数据门户、数字大屏、管理驾驶舱的可视化形态呈现给业务用户,为一个比较典型的场景。
增长分析
用户行为分析,即多场景决策的数据分析平台。而在增长分析当中,分为了以下三个内容:
1. 数据采集:采集用户行为、经营分析以及平台的数据,全埋点与可视化圈选,广告及其他触点数据接入。
2. 数据分析:
1. 行为分析:包括一个行为的单点事件、路径分析以及热图等
1. 用户分析:对用户的客户群体、用户画像以及用户的具体查询等
1. 内容分析:包括抖音视频、电商商品等
3. 智能应用:对于一些异常的检测与诊断、资源位归因以及推送运营与广告策略的应用。
一站式指标分析平台
以懂车帝为例,懂车帝主要给用户提供真实、专业汽车的内容分享和高效的选车服务,同时基于营销需求,他们会根据用户增长的模型以及销售方法论,收集用户在端内的操作行为,进行后台的查询分析。
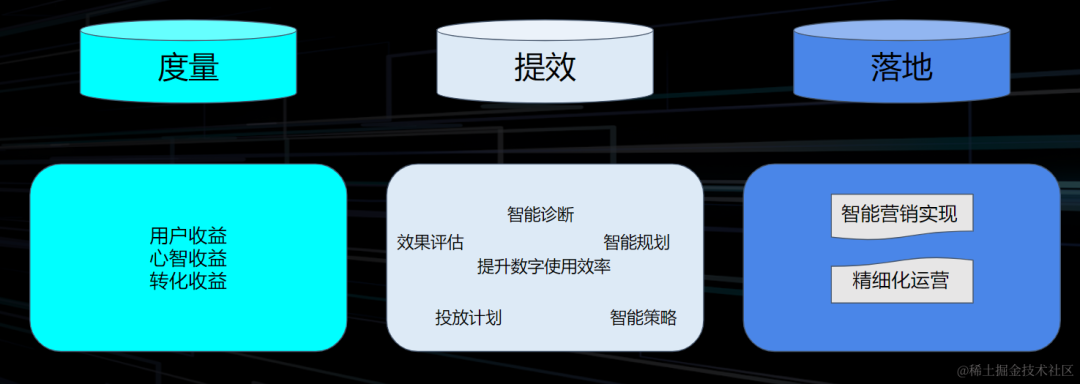
而这种查询分析底层对接了ByteHouse的大数据引擎,最后实现秒级甚至是亚秒级分析的决策。整个过程包括智能诊断、智能规划以及策略到投放效果评估闭环,最终实现智能营销和精细化运营。
ETL 场景
ELT 与 ETL 的区别
ETL是用来描述将资料从来源端经过抽取、转置、加载至目的端(数据仓库)的过程。Transform通常描述在数据仓库中的前置数据加工过程。 ELT专注于将最小处理的数据加载到数据仓库中,而把大部分的转换操作留给分析阶段。相比起ETL,它不需要过多的数据建模,而给分析者提供更灵活的选项。ELT已经成为当今大数据的处理常态,它对数据仓库也提出了很多新的要求。
下面表述上会有一些两个词语混用的场景,大家不必过分关注区别。
典型场景
一站式报表
传统大数据解决的方案有两大难点:慢和难。分别体现在传统大数据方案在及时性上达不到要求以及传统数仓ETL对人员要求高、定位难和链路复杂。
但是ByteHouse可以轻松的解决上述问题:将hive数据直接导入到ByteHouse,形成大宽表,后续所有处理都在ByteHouse进行。
现有挑战
资源重复
典型的数据链路如下:我们将行为数据、日志、点击流等通过MQ/Kafka/Flink将其接入存储系统当中,存储系统又可分为域内的HDFS和云上的OSS&S3这种远程储存系统,然后进行一系列的数仓的ETL操作,提供给OLAP系统完成分析查询。
但有些业务需要从上述的存储中做一个分支,因此会在数据分析的某一阶段,从整体链路中将数据导出,做一些不同于主链路的ETL操作,会出现两份数据存储。其次在这过程中也会出现两套不同的ETL逻辑。
当数据量变大,计算冗余以及存储冗余所带来的成本压力也会愈发变大,同时,存储空间的膨胀也会让弹性扩容变得不便利。
复杂场景
从OLAP场景扩展出去,随着数据量的增长和业务复杂度的提升,ClickHouse渐渐不能满足要求,体现在以下几点:
业务变复杂后,单纯大宽表不能满足业务需求。 数据量逐渐增多,提高性能的同时,需要进行一些数仓转换操作
在ByteHouse上去做复杂查询或ELT任务,可以扩展ClickHouse的能力,增强它的可用性、稳定性以及性能,同时还支持不同类型的混合负载。
业界解决思路
在业界中,为了解决以上问题,有以下几类流派:
数据预计算流派:如Kylin等。如果Hadoop系统中出报表较慢或聚合能力较差,可以去做一个数据的预计算,提前将配的指标的cube或一些视图算好。实际SQL查询时,可以直接用里面的cube或视图做替换,之后直接返回。 流批一体 派:如Flink、Risingwave。在数据流进时,针对一些需要出报表或者需要做大屏的数据直接内存中做聚合。聚合完成后,将结果写入HBase或MySQL中再去取数据,将数据取出后作展示。Flink还会去直接暴露中间状态的接口,即queryable state,让用户更好的使用状态数据。但是最后还会与批计算的结果完成对数,如果不一致,需要进行回查操作,整个过程考验运维/开发同学的功力。 湖仓 一体&HxxP:将数据湖与数据仓库结合起来。
ELT in ByteHouse
整体流程
ELT任务对系统的要求:
整体易扩展:导入和转换通常需要大量的资源,系统需要通过水平扩展的方式来满足数据量的快速增长。 可靠性和容错能力:大量的job能有序调度;出现task偶然失败(OOM)、container失败时,能够拉起重试;能处理一定的数据倾斜 效率&性能:有效利用多核多机并发能力;数据快速导入;内存使用有效(内存管理);CPU优化(向量化、codegen) 生态& 可观测性:可对接多种工具;任务状态感知;任务进度感知;失败日志查询;有一定可视化能力
ByteHouse针对ELT任务的要求,以及当前场景遇到的困难,做了如下特性和改进。
存储服务化
方案:
ETL后先储存为Parquet 通过存储服务化对外提供查询服务 Parque转Part文件 删掉Parquet文件 统一通过Part提供服务
val df = spark.read.format("CnchPart")
.options(Map("table" -> "cnch_db.c1")).load()
val spark = SparkSession.builder()
.appName("CNCH-Reader")
.config("spark.sql.extensions", "CnchAutoConvertExtension")
.enableHiveSupport() .getOrCreate()
val df = spark.sql("select * from cnch_db.c1")
收益:
ETL简化为一套逻辑,节省运维成本 文件统一存储为Part,占用空间与Parquet大体相同。整体存储减少1/2。
stage by stage schedule
整体介绍
当前ClickHouse的sql执行过程:
第一阶段,Coordinator 收到分布式表查询后将请求转换为对 local 表查询发送给每个 shard 节点。 第二阶段,Coordinator 收到各个节点的结果后汇聚起来处理后返回给客户端。 ClickHouse将Join操作中的右表转换为子查询,带来如下几个问题:
复杂的query有多个子查询,转换复杂度高 join表较大时容易造成worker节点的OOM 聚合阶段在Cooridnator,压力大,容易成为瓶颈
不同于ClickHouse,我们在ByteHouse中实现了对复杂查询的执行优化。通过对执行计划的切分,将之前的两阶段执行模型转换为分阶段执行。在逻辑计划阶段,根据算子类型插入exchange算子。执行阶段根据exchange算子将整个执行计划进行DAG切分,并且分stage进行调度。stage之间的exchange算子负责完成数据传输和交换。
关键点:
exchange节点插入 切分stage stage scheduler segment executer exchange manager
这里重点来讲一下exchange的视线。上图可以看到,最顶层的是query plan。下面转换成物理计划的时候,我们会根据不同的数据分布的要求转换成不同的算子。source层是接收数据的节点,基本都是统一的,叫做ExchangeSource。Sink则有不同的实现,BroadcastSink、Local、PartitionSink等,他们是作为map task的一部分去运行的。如果是跨节点的数据操作,我们在底层使用统一的brpc流式数据传输,如果是本地,则使用内存队列来实现。针对不同的点,我们进行了非常细致的优化。
数据传输层
进程内通过内存队列,无序列化,zero copy 进程间使用brpc stream rpc,保序、连接复用、状态码传输、压缩等 算子层
批量发送 线程复用,减少线程数量
带来的收益
Cooridnator更稳定、更高效
聚合等算子拆分到worker节点执行 Cooridnator节点只需要聚合最终结果 Worker OOM减少
进行了stage切分,每个stage的计算相对简单 增加了exchange算子,减少内存压力 网络连接更加稳定、高效
exchange算子有效传输 复用连接池
adaptive scheduler
这是在稳定性方面所做的特性。在OLAP场景中可能会发现部分数据不全或数据查询超时等,原因是每个计算节点是所有的query共用的,这样一旦有一个节点较慢就会导致整个query的执行受到影响。
计算节点共用存在的问题:
scan 节点负载和 workload 相关,做不到完全平均 各 plan segment 所需资源差异大
这就导致worker节点之间的负载严重不均衡。负载较重的worker节点就会影响query整体的进程。
解决措施:
建立 worker 健康度机制。Server 端建立worker 健康度管理类,可以快速获取worker group 的健康度信息。包括cpu、内存、运行query数量等信息。 自适应调度。每个sql 根据 worker 健康度动态的进行worker 选择以及计算节点并发度控制
query queue
我们的集群也会出现满载情况,即所有的worker都是不健康的或者满载/超载的,就会用查询队列来进行优化。
我们直接在server端做了一个manager。每次查询的时候manager会去check集群的资源,并且持有一个锁。如果资源不够用,则等待资源释放后去唤醒这个锁。这就避免了Server端不限制的下发计算任务,导致worker节点超载,然后崩掉的情况。
当前实现相对简单。server是多实例,每个server实例中都有queue,所持有的是一个局部视角,缺乏全局的资源视角。除此之外,每个queue中的查询状态没有持久化,只是简单的缓存在内存中。
后续,我们会增加server之间的协调,在一个全局的视角上对查询并发做限制。也会对server实例中query做持久化,增加一些failover的场景支持。
async execution
ELT任务的一个典型特征就是相对即时分析,他们的运行时间会相对较长。一般为分钟级,甚至到达小时级。目前ClickHouse的客户端查询都采用阻塞的方式进行返回。这样就造成了客户端长期处于等待的情况,而在这个等待过程中还需要保持和服务端的连接。在不稳定的网络情况下,客户端和服务端的连接会断开,从而导致服务端的任务失败。
为了减少这种不必要的失败,以及减少客户端为了维持连接的增加的复杂度。我们开发了异步执行的功能,它的实现如下:
用户指定异步执行。用户可以通过settings enable_async_query = 1的方式进行per query的指定。也可以通过set enable_async_query = 1的方式进行session级别的指定。 如果是异步query,则将其放到后台线程池中运行 静默io。当异步query执行时,则需要切断它和客户端的交互逻辑,比如输出日志等。
针对query的初始化还是在session的同步线程中进行。一旦完成初始化,则将query状态写入到metastore,并向客户端返回async query id。客户端可以用这个id查询query的状态。async query id返回后,则表示完成此次查询的交互。这种模式下,如果语句是select,那么后续结果则无法回传给客户端。这种情况下我们推荐用户使用async query + select...into outfile的组合来满足需求。
未来规划
针对ELT混合负载,目前只是牛刀小试。后续的版本中我们会持续补齐规划中的能力,包括但不限于以下:
导入优化
spark part writer转换到域内执行,提高性能 细粒度导入任务的事务处理 细粒度导入任务事务锁优化
故障恢复能力
算子spill
sort、agg、join社区已有部分能力,我们在同步的同时,会针对性的做性能优化和bug修复。也会探索一些自动化spill的可能。 exchange增加spill能力 recoverability
算子执行恢复。ELT任务运行时长较长时,中间task的偶发失败会导致整个query失败。整体重试的话会造成时长的浪费。task原地失败重试可以避免环境原因导致的偶发失败。 stage重试。当节点失败时,可以进行stage级别的重试 队列作业状态保存 remote shuffle service:当前业界开源的shuffle service通常为Spark定制,没有通用的客户端,比如c++客户端。需要一起适配。
资源
计算资源可指定:用户可指定query需要的计算资源。 计算资源预估/预占:可动态预估query需要的计算资源,并通过预占的方式进行调配。 动态申请资源:当前worker均为常驻进程/节点。动态申请资源可以提高利用率。 更细粒度的资源隔离:通过worker group或者进程级别的隔离,减少各query之间相互影响
生态
支持更多ETL编排、调度工具
dbt、AirFlow已支持 Kettle、Dolphin、SeaTunnel陆续支持中... 数据湖格式对接
Hudi、Iceberg external table reader JNI reader to accelerate
如有侵权请联系:admin#unsafe.sh