C’è massima allerta in rete per una nuova vulnerabilità zero-day ribattezzata “Rapid Reset” nel protocollo HTTP/2 che è stata sfruttata per lanciare il più grande attacco DDoS di sempre con 398 milioni di richieste al secondo.
A dare l’allarme con un comunicato congiunto, lo scorso 10 ottobre 2023, sono stati Cloudflare, Google e Amazon Web Services (AWS).
La vulnerabilità che ha consentito di mettere a punto la nuova tecnica di attacco è stata tracciata come CVE-2023-44487 e ha consentito di abusare (a quanto pare, dallo scorso mese di agosto) della funzionalità di cancellazione del flusso di HTTP/2 per inviare e annullare continuamente richieste di connessione, provocando il rapido sovraccarico dei server/applicazioni di destinazione e causando uno stato di DoS (Denial of Service).
Per “risalire alle origini” della vulnerabilità CVE-2023-44487 è utile comprendere come funziona il protocollo HTTP.
Cos’è e come funziona il protocollo HTTP
HTTP è il protocollo applicativo che alimenta il Web. La sintassi HTTP è comune a tutte le versioni dei browser: l’architettura generale, la terminologia e gli aspetti del protocollo come messaggi di richiesta e risposta, metodi, codici di stato, campi di intestazione e direttive, payload dei messaggi e molto altro.
Basta incidenti in università: scopri il tuo nuovo sistema di controllo accessi
Ogni versione HTTP definisce come la semantica viene trasformata in un formato fruibile per lo scambio su Internet. Ad esempio, se un client deve serializzare un messaggio di richiesta in dati binari e inviarlo, il server lo analizzerà in un messaggio che potrà elaborare.
HTTP/1.1 utilizza una forma testuale di serializzazione. I messaggi di richiesta e risposta vengono scambiati come un flusso di caratteri ASCII, inviati su un livello di trasporto affidabile come TCP, utilizzando il seguente formato (dove CRLF significa ritorno a capo e avanzamento riga).

Ad esempio, una semplice richiesta GET per la risorsa https://blog.cloudflare.com apparirebbe così:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
e la risposta sarebbe simile a:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Questo formato di scambio racchiude i messaggi in transito, il che significa che è possibile utilizzare una singola connessione TCP per scambiarsi più richieste e risposte con il server. Tuttavia, il formato richiede che ciascun messaggio venga inviato per intero.
Inoltre, per correlare correttamente le richieste con le risposte, è necessario un ordinamento rigoroso: ciò significa che i messaggi devono essere scambiati in serie, e non possono essere sottoposti a multiplexing. Un esempio di due richieste GET, una per https://blog.cloudflare.com e l’altra per https://blog.cloudflare.com/page/2/:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLFGET /page/2/ HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
e le relative risposte:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>CRLFHTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Le pagine Web ci forniscono interazioni HTTP assai più complicate rispetto a questi esempi giocattolo.
Quando visitiamo il blog Cloudflare, ad esempio, il nostro browser carica più script, stili e risorse multimediali.
Se visitiamo la prima pagina utilizzando lo standard HTTP/1.1 ma decidiamo di passare rapidamente alla pagina 2, il nostro browser può scegliere tra due opzioni: attendere tutte le risposte in coda per la pagina che non desideriamo più prima ancora che la pagina 2 venga caricata, oppure annullare le richieste in corso chiudendo la connessione TCP e aprendo una nuova connessione.
Nessuno di questi approcci è molto pratico. I browser tendono ad aggirare queste limitazioni gestendo un pool di connessioni TCP (fino a 6 per host) e implementando una complessa logica di invio di richieste sul pool.
È qui che entra in ballo il protocollo HTTP/2, ossia il successore di HTTP/1.1
HTTP/2, il nuovo protocollo del Web
HTTP/2 risolve molti dei limiti strutturali di HTTP/1.1. Ogni messaggio HTTP viene serializzato in un set di frame HTTP/2 contenente tipo, lunghezza, flag, identificatore di flusso (ID) e payload. L’ID del flusso chiarisce quali byte sulla rete si applicano a quale messaggio, consentendo una gestione sicura del multiplexing e della concorrenza. I flussi sono bidirezionali. I client inviano frame, e i server rispondono con frame utilizzando lo stesso ID.
Utilizzando HTTP/2, una richiesta GET per https://blog.cloudflare.com verrebbe scambiata attraverso lo stream ID 1, con il client che invia un frame HEADERS, e il server che risponde a sua volta con un frame HEADERS seguito da uno o più frame DATA.
Le richieste del client utilizzano sempre ID di flusso con numeri dispari, quindi, le richieste successive utilizzeranno sempre l’ID di flusso 3, 5 e così via. Le risposte possono essere fornite in qualsiasi ordine, mentre i frame provenienti da flussi diversi possono essere interlacciati.

Il multiplexing del flusso e la concorrenza sono funzionalità innovative di HTTP/2: consentono un utilizzo più efficiente di una singola connessione TCP.
HTTP/2 ottimizza il recupero delle risorse soprattutto se abbinato all’utilizzo delle priorità, d’altro canto, semplificare ai client l’avvio di grandi quantità di lavoro parallelo può aumentare la domanda di picco di risorse del server rispetto a HTTP/1.1, e questo è un palese vettore per attacchi informatici di tipo DoS (Denial-of-Service).
A tal fine, per fornire alcune contromisure strutturali a scenari DoS, HTTP/2 implementa la proprietà di Massimi numero di Stream attivi simultaneamente: il parametro SETTINGS_MAX_CONCURRENT_STREAMS, infatti, consente a un server di comunicare il proprio limite massimo di richieste attivabili simultaneamente.
Ad esempio, se il server indica un limite di 100, in qualsiasi momento potranno essere attive solo 100 richieste. Se un client tenta di aprire una richiesta quando il limite è già stato raggiunto, dovrà essere rifiutata dal server comunicando il frame RST_STREAM. Il rifiuto della richiesta non influisce sulle altre richieste in coda.
Ad alto livello, in maniera semplicistica è così come hai letto. Approfondiamo ora la cosa su un piano più tecnico, ma soprattutto realistico.
HTTP/2: come funzionano le richieste ai server/applicazioni di destinazione
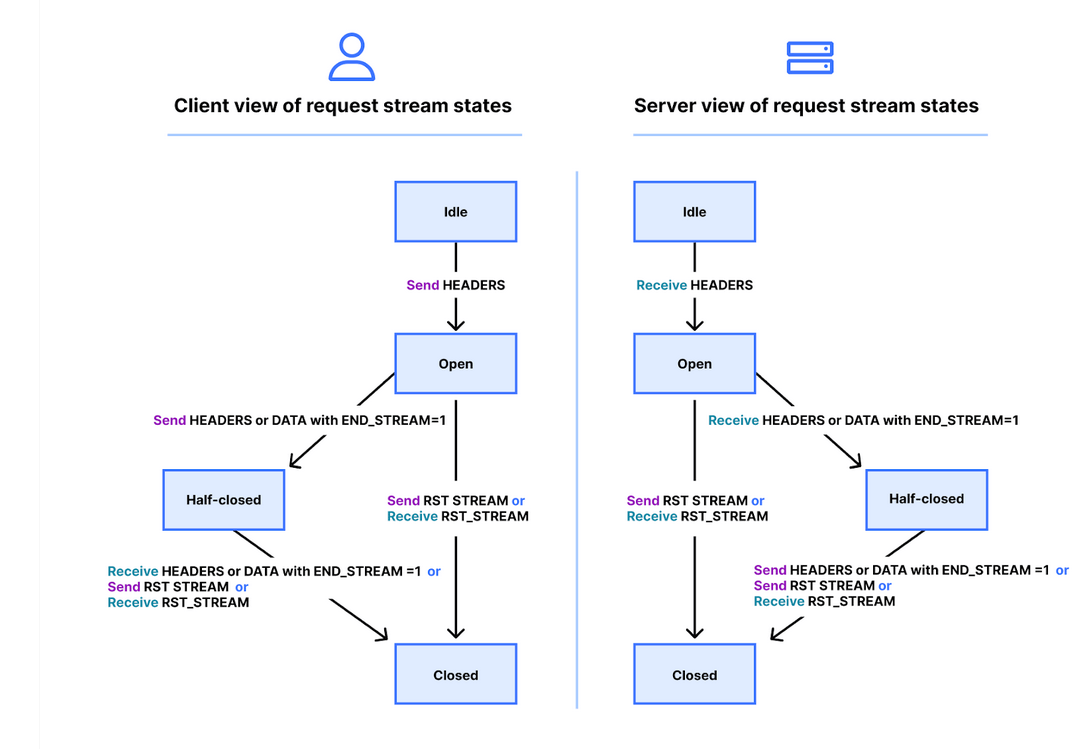
I flussi hanno un ciclo di vita e di seguito è riportato un diagramma della macchina a stati della loro gestione in HTTP/2.

Client e server gestiscono le proprie visualizzazioni dello stato di uno stream. I frame HEADERS, DATA e RST_STREAM attivano transizioni quando vengono inviati o ricevuti. Sebbene le visualizzazioni dello stato dello stream siano indipendenti, sono sincronizzate.
I frame HEADERS e DATA includono un flag END_STREAM che, se impostato sul valore 1 (true), potrà provocare una transizione di stato.
Analizziamolo con un esempio di richiesta GET priva di contenuto del messaggio. Il client invia la richiesta come frame HEADERS con il flag END_STREAM impostato su 1. Il client innanzitutto effettua la transizione dello stream dallo stato inattivo allo stato aperto, quindi passa immediatamente allo stato semichiuso.
Lo stato semichiuso del client significa che non può più inviare HEADERS o DATA, ma solo frame WINDOW_UPDATE, PRIORITY o RST_STREAM. Può comunque ricevere qualsiasi frame.
Una volta che il server riceve e analizza il frame HEADERS, varierà lo stato del flusso da inattivo ad aperto, e quindi semichiuso, in modo che corrisponda a quello del client. Lo stato semichiuso del server significa che potrà inviare qualsiasi frame ma ricevere solo frame WINDOW_UPDATE, PRIORITY o RST_STREAM.
La risposta al GET contiene il contenuto del messaggio, quindi il server invierà dapprima HEADERS con il flag END_STREAM impostato su 0, successivamente DATA con il flag END_STREAM impostato su 1. Il frame DATA attiva la transizione dello stream da semichiuso a chiuso sul server. Quando il client lo riceve, passa anch’esso a chiuso. Una volta chiuso uno stream, non è possibile inviare o ricevere frame.
Riapplicando questo ciclo di vita al contesto della concorrenza, il protocollo HTTP/2 afferma che:
Gli stream che si trovano nello stato “aperto” o in uno degli stati “semichiuso” vengono conteggiati nel numero massimo di stream che un endpoint può aprire. Gli stream in uno qualsiasi di questi tre stati vengono conteggiati ai fini del limite dichiarato nell’impostazione SETTINGS_MAX_CONCURRENT_STREAMS.
In teoria, il limite di concorrenza è utile. Tuttavia, ci sono fattori pratici che ne ostacolano l’efficacia, di cui parlerò più avanti.
L’annullamento delle richiesteda parte del client: in cosa consiste
In precedenza, ho scritto dell’annullamento delle richieste in coda da parte del cliente, e infatti HTTP/2 lo supporta in modo più efficiente di HTTP/1.1. Invece di dover interrompere l’intera connessione, un client può inviare un frame RST_STREAM per un singolo stream. Ciò indica al server di interrompere l’elaborazione della richiesta e di interrompere la risposta, liberando risorse del server ed evitando sprechi di larghezza di banda.
Consideriamo ora il nostro precedente esempio di tre richieste. Questa volta il client annulla la richiesta sul primo stream dopo che tutte le intestazioni sono state inviate. Il server analizza il frame RST_STREAM prima che sia pronto a fornire la risposta, e quindi risponde solo ai flussi 3 e 5:

La cancellazione delle richieste è una funzionalità fondamentale. Ad esempio, quando si scorre una pagina Web con più immagini, un browser Web può decidere di non caricare le immagini che non rientrano nell’area visibile, il che significa che le immagini che vi entrano potranno essere caricate più velocemente. HTTP/2 rende questa gestione più efficiente rispetto a HTTP/1.1
Un flusso di richieste che viene annullato passa rapidamente attraverso il ciclo di vita degli stream. Le intestazioni del client con il flag END_STREAM impostato su 1 fanno variare lo stato da inattivo ad aperto, a semichiuso, quindi, RST_STREAM provocherà una transizione immediata da semichiuso a chiuso.

Ricorda che solo gli stream che si trovano nello stato aperto o semichiuso contribuiscono al limite dichiarato nell’impostazione SETTINGS_MAX_CONCURRENT_STREAMS: quando un client annulla uno stream, ottiene immediatamente la possibilità di aprire un altro stream al suo posto, e può inviare immediatamente un’altra richiesta. Questo è il punto cruciale di ciò che fa funzionare la vulnerabilità CVE-2023-44487 ribattezzata HTTP/2 Rapid Reset.
Vulnerabilità HTTP/2 Rapid Reset: come funziona
Con HTTP/2 è infatti possibile abusare della cancellazione delle richieste reimpostando rapidamente un numero illimitato di stream. Quando un server HTTP/2 è in grado di elaborare i frame RST_STREAM inviati dal client e di eliminare lo stato con sufficiente rapidità, tali ripristini rapidi non causano problemi.
Viceversa, lo scenario tipico in cui iniziano le rogne è quello in cui si verifica un ritardo nel riordino, oppure un ritardo di qualunque tipo: in questa situazione, infatti, il client potrebbe elaborare appositamente così tante richieste da provocare un accumulo di stream, con conseguente consumo eccessivo di risorse lato server.
La più diffusa architettura di sicurezza informatica per HTTP consiste nell’eseguire un proxy HTTP/2 o un bilanciatore di carico (load balancer) davanti ad altri componenti: quando arriva una richiesta del client, viene rapidamente evasa e il lavoro effettivo viene passato altrove come attività asincrona.
Ciò consente al proxy di gestire il traffico client in modo molto più veloce. Tuttavia, questa separazione dalle “preoccupazioni applicative” può rendere difficile ai proxy il compito di riordinare i lavori in corso. Pertanto, queste architetture hanno maggiori probabilità di riscontrare problemi derivanti da ripristini rapidi.
Quando i reverse proxy elaborano il traffico client HTTP/2 in entrata, copiano i dati dal socket della connessione in un buffer, ed elaborano i dati memorizzati nel buffer in base all’ordine di arrivo. Una volta che la richiesta viene letta (HEADERS e frame DATA) viene inviata a un servizio upstream.
Quando verranno letti i frame RST_STREAM, lo stato locale della richiesta verrà eliminato e all’upstream verrà notificato che la richiesta è stata annullata.
Questo processo viene ripetuto fino all’esaurimento dell’intero buffer, tuttavia, si può abusare di questa logica: quando un client malevolo iniziasse a inviare un’enorme catena di richieste e reset all’inizio di una connessione, il server leggerebbe avidamente tutte le richieste saturandosi al punto tale da non essere in grado di elaborare alcuna nuova richiesta in arrivo.
È fondamentale sottolineare che l’impostazione MAX_CONCURRENT_STREAMS da sola non è in grado di mitigare questa condizione, il client infatti potrebbe forgiare le richieste per creare tassi di richiesta elevati indipendentemente dal valore indicato dal server nell’impostazione.
Un esempio di sfruttamento della vulnerabilità HTTP/2 Rapid Reset
Ecco un esempio di questa vulnerabilità riprodotta utilizzando un client PoC che tenta di effettuare un totale di 1.000 richieste: un ricercatore dell’azienda CloudFlare si è avvalso di un web server standard, in ascolto sulla porta 443 in un ambiente di test. Il traffico è stato analizzato utilizzando Wireshark, e per chiarezza è stato filtrato per mostrare il solo traffico HTTP/2. È possibile scaricare il relativo file .pcap da qui per analizzarlo anche tu con un qualunque packets analyzer.

Non è immediato da individuare poiché ci sono molti fotogrammi. Possiamo, tuttavia, ottenere un breve riepilogo tramite la voce di menu Statistiche > HTTP2 (nella versione italiana) di Wireshark:

Il primo frame di questa evidenza, nel pacchetto 14, è il frame SETTINGS del server, che annuncia che il massimo numero di stream gestibili simultaneamente è pari a 100.

Nel pacchetto 15, il client invia alcuni frame di controllo e successivamente inizia ad effettuare richieste che vengono rapidamente ripristinate. Il primo frame HEADERS è lungo 26 byte, tutti i successivi HEADERS solo 9 byte.
Questa differenza nelle dimensioni è dovuta a una tecnologia di compressione chiamata HPACK. In totale, il pacchetto 15 contiene 525 richieste, arrivando fino allo stream 1051.

È interessante notare che RST_STREAM per lo stream 1051 non entra nel pacchetto numero 15, viceversa, nel pacchetto 16 è possibile notare che il server risponde con il codice HTTP 404. Nel pacchetto 17 il client invia RST_STREAM, prima di passare all’invio delle restanti 475 richieste.
Sebbene il server annunci 100 stream simultanei, entrambi i pacchetti inviati dal client hanno inviato molti più stream HEADERS. Il client non doveva attendere il traffico di ritorno dal server, era limitato solo dalla dimensione dei pacchetti che poteva inviare: in questa evidenza non c’è traccia di alcun frame RST_STREAM da parte del server, a indicare che il server ha ignorato la violazione del valore che era definito in MAX_CONCURRENT_STREAMS.
Come mitigare la vulnerabilità HTTP/2 Rapid Reset
Alla luce di questa pesante vulnerabilità HTTP/2 Rapid Reset in grado di consentire la saturazione di un servizio HTTP (usato non solo da applicativi gestionali basati su web, ma potenzialmente anche da sistemi di autenticazione a centralini VoIP, da sistemi IoT, da piattaforme di management centralizzate e quant’altro) attraverso attacchi DoS, il suggerimento (almeno fino a quando i vendor coinvolti non rilasceranno delle patch ufficiali e a loro i volta i sistemisti non aggiorneranno prontamente i sistemi in produzione) è quello di contattare il proprio fornitore (o il proprio distributore, nel caso ci si sia rivolti a intermediari) per verificare insieme al supporto tecnico se i propri bilanciatori e i propri webserver siano effettivamente al momento in grado di gestire un attacco che sfrutti CVE-2023-44487.
Viceversa, nel caso in cui l’infrastruttura di rete o sistemistica venga gestita senza intermediari e si è alla ricerca di consulenza in merito ad analisi e contromisure per la vulnerabilità CVE-2023-44487 HTTP/2 Rapid Reset, è possibile inviare un’e-mail all’indirizzo [email protected].
Migliora efficienza e affidabilità dell'intralogistica con l'automazione del magazzino
@RIPRODUZIONE RISERVATA