7 月初埃隆马斯克带领的 X 曾屏蔽谷歌搜索爬虫抓取内容,这导致谷歌搜索无法在用户搜索 X 用户名时展示最新的推文摘要,不过后面 X 对谷歌解封了。
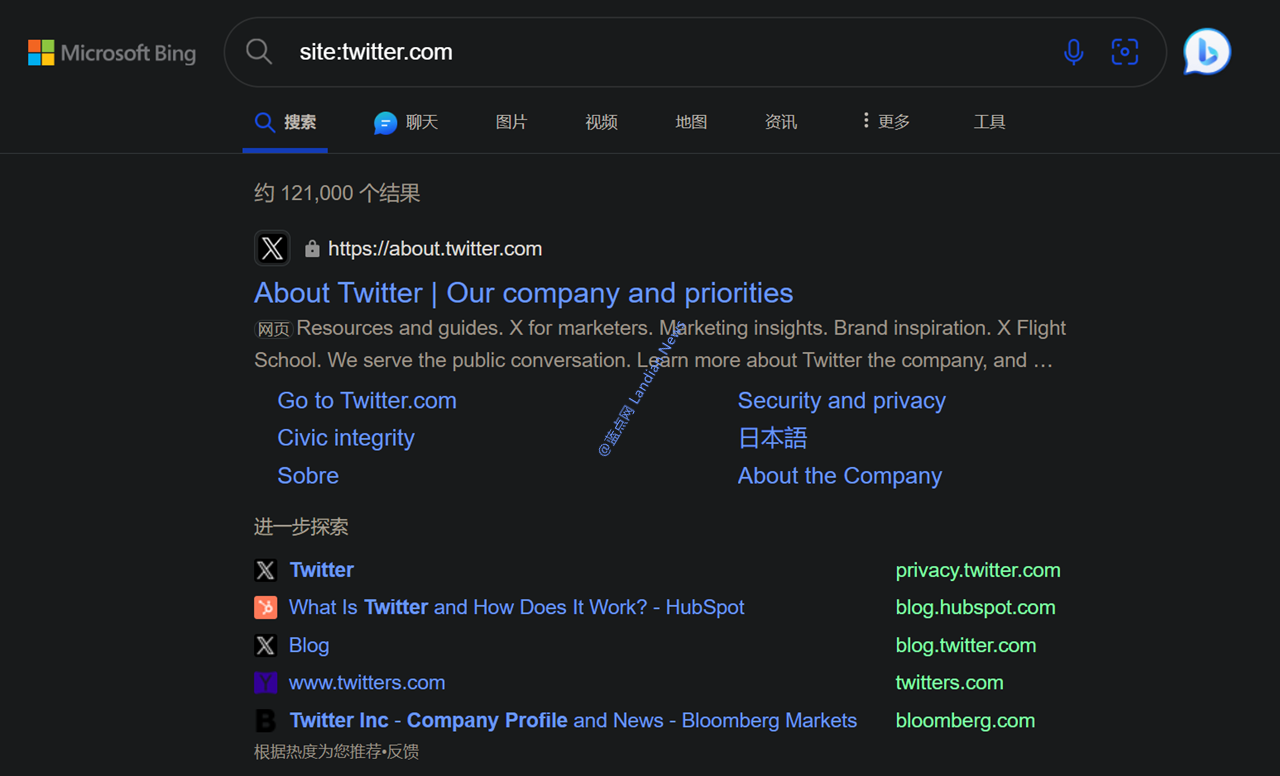
但其他搜索引擎就没那么幸运了,如果使用 site:twitter.com 指令在必应搜索上查询的话,你会发现必应收录的 X 内容只有 12.1 万条,而谷歌搜索则是 4.22 亿条。
发生了什么?原因是 X 屏蔽了除谷歌搜索以外的所有搜索引擎爬虫,至于原因嘛也很简单,埃隆马斯克不想 X 的数据被其他人抓取拿去训练 AI,所有屏蔽了诸如 Bingbot、MSNbot、Yandex 等搜索引擎爬虫。

那谷歌为什么是例外的呢?估计马斯克都要骂街了,因为之前有传闻称杰克多西时代的推特与谷歌达成了相关协议,允许谷歌抓取内容,目前这一协议尚未到期。
蓝点网通过互联网档案馆排查发现,X 是在 2023 年 7 月 24 日执行屏蔽操作的,更新后的 robots.txt 文件仅允许 Googlebot 抓取内容,其他所有爬虫均被封禁。
所以现在诸如必应搜索上的推特内容极少也就是这个原因,后面估计索引数量会进一步降低,如果谷歌的协议到期了估计内容也都会消失。
不过 robots.txt 毕竟只是君子协定 (这不是法律规定,之前某大数字被某度起诉抓取某度百科内容时,就辩称这是 robots.txt 只是行业管理而非法律规定),所以仍然有各种来路不明的爬虫试图抓取推特上的内容拿去卖数据。
对于这种情况埃隆马斯克也早有准备,在协议规定未经同意获取内容属于违反协议的行为,马斯克对这些未经同意的抓取行为直接起诉。
附 X robots.txt 的最新内容:
# Google Search Engine Robot # ========================== User-agent: Googlebot Allow: /?_escaped_fragment_ Allow: /*?lang= Allow: /hashtag/*?src= Allow: /search?q=%23 Allow: /i/api/ Disallow: /search/realtime Disallow: /search/users Disallow: /search/*/grid Allow: /*?ref_src= Allow: /*?src= Disallow: /*? Disallow: /*/followers Disallow: /*/following Disallow: /account/deactivated Disallow: /settings/deactivated # 下面的指令代表禁止搜索爬虫抓取内容 # ======================================================== User-agent: * Disallow: /
版权声明:感谢您的阅读,除非文中已注明来源网站名称或链接,否则均为蓝点网原创内容。转载时请务必注明:来源于蓝点网、标注作者及本文完整链接,谢谢理解。