
IntroductionOver the span of the previous two blog posts in the series, I showed why the m 2023-10-26 19:0:0 Author: blog.nviso.eu(查看原文) 阅读量:46 收藏
Introduction
Over the span of the previous two blog posts in the series, I showed why the majority of Cobalt Strike (CS) BOFs are incompatible with Brute Ratel C4 (BRC4) and what you can do about it. I also presented CS2BR itself: it’s a tool that makes patching BOFs to be compatible with BRC4 a breeze. However, we also found some limitations to CS2BR’s current approach.
In this (final?) post in this series, we’ll take a look at one of CS2BR’s shortcomings: its reliance on source-code for patching. We’ll see how this can be resolved and – spoiler alert – why we couldn’t (yet!) but decided to pull the plug on it. That’s right: this blog post won’t present a fancy new solution but the challenges you’ll encounter when you go down this rabbit hole.

This post will get a bit more technical than its predecessors. Don’t worry though, I’ll try my best not to get lost in itty-bitty details. So feel free to grab a coffee and prepare for a journey into the wonderful world of object files, how you can mess with them, and what I did to them.
I. Underlying motivation
When I finished work on CS2BR’s source code patching, I realized that there were two major issues with it that caused me headaches and that I wasn’t happy with:
- Input arguments: Supplying BOFs with input arguments in BRC4 isn’t straightforward and requires you to figure out the number and format of arguments, feed them into a standalone Python script, and pass the output into BRC4.
- Source code: In order to make BOFs compatible with BRC4 in the first place, CS2BR patches a compatibility layer (and some extras) into a BOF’s source code. You’ll then need to recompile the BOF in order to use it in BRC4.
While the first issue is just somewhat awkward, the second one can be a real showstopper in some cases:
- Third party BOFs: There are proprietary, commercial BOFs out there that you might like to use in BRC4, but can’t because they’re incompatible. Since you usually don’t have access to their source code, you can’t use CS2BR to patch them.
- Compilation: Usually BOFs come with limited features and thus don’t require crazy compilation environments. Well, if they do, CS2BR’s source code patching can interfere with that and potentially screw up your compilation configuration. You’d then need to get into the depths of makefiles, build scripts and Visual Studio project configurations to troubleshoot.
So wouldn’t it be great if we didn’t need access to source code? And wouldn’t it be cool to avoid recompilation of BOFs? There surely has to be a way to do this, right?
II. The idea
Since BOFs are object files (hence the name, beacon object files) and CS2BR’s compatibility layer can be compiled into an object file, we might just be able to merge both of them into a single object file.

And indeed, it appears that you can merge object files using ld, the GNU linker:
ld --relocatable cs2br.o bof.o -o brc4bof.o
That’s the basic premise. Before we continue with the details of this idea, let’s have a brief look at the “Common Object File Format” (COFF) that our object files come in.
About COFF
At their core, object files are an intermediate format of executables: they contain compiled code and data but aren’t directly executable. Here’s the source code of a simple BRC4 BOF that prints its input arguments:
#include "badger_exports.h"
void coffee(char** argv, int argc, WCHAR** dispatch) {
int i = 0;
for (; i < argc; i++) {
BadgerDispatch(dispatch, "Arg #%i: \"%s\"\n", (i+1), argv[i]);
}
}
This can be compiled into a COFF file using a C compiler such as mingw on a Linux machine:
$ x86_64-w64-mingw32-gcc -o minimal.o -c minimal.c $ file minimal.o minimal.o: Intel amd64 COFF object file, no line number info, not stripped, 7 sections, symbol offset=0x216, 19 symbols, 1st section name ".text"
We can get detailed information about the compiled object file using the nd or objdump utilities:
objdump output
$ objdump -x minimal.o
minimal.o: file format pe-x86-64
minimal.o
architecture: i386:x86-64, flags 0x00000039:
HAS_RELOC, HAS_DEBUG, HAS_SYMS, HAS_LOCALS
start address 0x0000000000000000
Characteristics 0x4
line numbers stripped
Time/Date Wed Dec 31 19:00:00 1969
Magic 0000
MajorLinkerVersion 0
MinorLinkerVersion 0
SizeOfCode 0000000000000000
SizeOfInitializedData 0000000000000000
SizeOfUninitializedData 0000000000000000
AddressOfEntryPoint 0000000000000000
BaseOfCode 0000000000000000
ImageBase 0000000000000000
SectionAlignment 00000000
FileAlignment 00000000
MajorOSystemVersion 0
MinorOSystemVersion 0
MajorImageVersion 0
MinorImageVersion 0
MajorSubsystemVersion 0
MinorSubsystemVersion 0
Win32Version 00000000
SizeOfImage 00000000
SizeOfHeaders 00000000
CheckSum 00000000
Subsystem 00000000 (unspecified)
DllCharacteristics 00000000
SizeOfStackReserve 0000000000000000
SizeOfStackCommit 0000000000000000
SizeOfHeapReserve 0000000000000000
SizeOfHeapCommit 0000000000000000
LoaderFlags 00000000
NumberOfRvaAndSizes 00000000
The Data Directory
Entry 0 0000000000000000 00000000 Export Directory [.edata (or where ever we found it)]
Entry 1 0000000000000000 00000000 Import Directory [parts of .idata]
Entry 2 0000000000000000 00000000 Resource Directory [.rsrc]
Entry 3 0000000000000000 00000000 Exception Directory [.pdata]
Entry 4 0000000000000000 00000000 Security Directory
Entry 5 0000000000000000 00000000 Base Relocation Directory [.reloc]
Entry 6 0000000000000000 00000000 Debug Directory
Entry 7 0000000000000000 00000000 Description Directory
Entry 8 0000000000000000 00000000 Special Directory
Entry 9 0000000000000000 00000000 Thread Storage Directory [.tls]
Entry a 0000000000000000 00000000 Load Configuration Directory
Entry b 0000000000000000 00000000 Bound Import Directory
Entry c 0000000000000000 00000000 Import Address Table Directory
Entry d 0000000000000000 00000000 Delay Import Directory
Entry e 0000000000000000 00000000 CLR Runtime Header
Entry f 0000000000000000 00000000 Reserved
The Function Table (interpreted .pdata section contents)
vma: BeginAddress EndAddress UnwindData
0000000000000000: 0000000000000000 000000000000006a 0000000000000000
Dump of .xdata
0000000000000000 (rva: 00000000): 0000000000000000 - 000000000000006a
Version: 1, Flags: none
Nbr codes: 3, Prologue size: 0x08, Frame offset: 0x0, Frame reg: rbp
pc+0x08: alloc small area: rsp = rsp - 0x30
pc+0x04: FPReg: rbp = rsp + 0x0 (info = 0x0)
pc+0x01: push rbp
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000070 0000000000000000 0000000000000000 0000012c 2**4
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000000 2**4
ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000000 2**4
ALLOC
3 .rdata 00000010 0000000000000000 0000000000000000 0000019c 2**4
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .xdata 0000000c 0000000000000000 0000000000000000 000001ac 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
5 .pdata 0000000c 0000000000000000 0000000000000000 000001b8 2**2
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA
6 .rdata$zzz 00000020 0000000000000000 0000000000000000 000001c4 2**4
CONTENTS, ALLOC, LOAD, READONLY, DATA
SYMBOL TABLE:
[ 0](sec -2)(fl 0x00)(ty 0)(scl 103) (nx 1) 0x0000000000000000 minimal.c
File
[ 2](sec 1)(fl 0x00)(ty 20)(scl 2) (nx 1) 0x0000000000000000 coffee
AUX tagndx 0 ttlsiz 0x0 lnnos 0 next 0
[ 4](sec 1)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000000 .text
AUX scnlen 0x6a nreloc 2 nlnno 0
[ 6](sec 2)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000000 .data
AUX scnlen 0x0 nreloc 0 nlnno 0
[ 8](sec 3)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000000 .bss
AUX scnlen 0x0 nreloc 0 nlnno 0
[ 10](sec 4)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000000 .rdata
AUX scnlen 0xf nreloc 0 nlnno 0
[ 12](sec 5)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000000 .xdata
AUX scnlen 0xc nreloc 0 nlnno 0
[ 14](sec 6)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000000 .pdata
AUX scnlen 0xc nreloc 3 nlnno 0
[ 16](sec 7)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000000 .rdata$zzz
AUX scnlen 0x17 nreloc 0 nlnno 0
[ 18](sec 0)(fl 0x00)(ty 0)(scl 2) (nx 0) 0x0000000000000000 __imp_BadgerDispatch
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000046 IMAGE_REL_AMD64_REL32 .rdata
0000000000000050 IMAGE_REL_AMD64_REL32 __imp_BadgerDispatch
RELOCATION RECORDS FOR [.pdata]:
OFFSET TYPE VALUE
0000000000000000 IMAGE_REL_AMD64_ADDR32NB .text
0000000000000004 IMAGE_REL_AMD64_ADDR32NB .text
0000000000000008 IMAGE_REL_AMD64_ADDR32NB .xdataThis gave us quite a lot of information of which I’d like to highlight and unpack three particularly important bits:
- Sections: These are regions of arbitrary, binary data. Their content is indicated by a section’s name and flags. For example, the
.textsection with theCODEflag set will usually contain compiled code whereas the.rdatasection with theREADONLYandDATAflags will contain readonly data (such as strings used in the application). - Symbols: Symbols are used to reference various things in object files, such as sections (e.g.
.text), functions (e.g.coffee) and imports (e.g.__imp_BadgerDispatch). - Relocations: An object file’s sections can contain references to symbols (and thus to other sections, functions, and imports). When the file is compiled or loaded into memory by a COFF loader such as BRC4, these references need to be resolved to actual relative or absolute memory addresses.
For example, the aboveBadgerDispatchcall references the stringArg #%i: \"%s\"\nwhich is located in the.rdatasection. The first relocation entry in the.textsection indicates that at offset0x46into the.textsection, there is a reference to the.rdatasymbol (which points to the.rdatasection), which needs to be resolved as a relative address.
COFF section contents dumped using objdump
$ objdump -s -j .rdata minimal.o
minimal.o: file format pe-x86-64
Contents of section .rdata:
0000 41726720 2325693a 20222573 220a0000 Arg #%i: "%s"...
$ objdump -S -j .text minimal.o
minimal.o: file format pe-x86-64
Disassembly of section .text:
0000000000000000 <coffee>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 30 sub $0x30,%rsp
8: 48 89 4d 10 mov %rcx,0x10(%rbp)
c: 89 55 18 mov %edx,0x18(%rbp)
f: 4c 89 45 20 mov %r8,0x20(%rbp)
13: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
1a: eb 3e jmp 5a <coffee+0x5a>
1c: 8b 45 fc mov -0x4(%rbp),%eax
1f: 48 98 cltq
21: 48 8d 14 c5 00 00 00 lea 0x0(,%rax,8),%rdx
28: 00
29: 48 8b 45 10 mov 0x10(%rbp),%rax
2d: 48 01 d0 add %rdx,%rax
30: 48 8b 10 mov (%rax),%rdx
33: 8b 45 fc mov -0x4(%rbp),%eax
36: 8d 48 01 lea 0x1(%rax),%ecx
39: 48 8b 45 20 mov 0x20(%rbp),%rax
3d: 49 89 d1 mov %rdx,%r9
40: 41 89 c8 mov %ecx,%r8d
43: 48 8d 15 00 00 00 00 lea 0x0(%rip),%rdx # 4a <coffee+0x4a>
4a: 48 89 c1 mov %rax,%rcx
4d: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax # 54 <coffee+0x54>
54: ff d0 call *%rax
56: 83 45 fc 01 addl $0x1,-0x4(%rbp)
5a: 8b 45 fc mov -0x4(%rbp),%eax
5d: 3b 45 18 cmp 0x18(%rbp),%eax
60: 7c ba jl 1c <coffee+0x1c>
62: 90 nop
63: 90 nop
64: 48 83 c4 30 add $0x30,%rsp
68: 5d pop %rbp
69: c3 ret
6a: 90 nop
6b: 90 nop
6c: 90 nop
6d: 90 nop
6e: 90 nop
6f: 90 nopThese are the central parts of COFF files that are relevant to this blog post.
Merging object files
Continuing with the idea of merging object files, it turns out that it’s not just going to be a simple ld. Let’s compare a regular BOF in Cobalt Strike to a CS2BR BOF in BRC4:

Pictured above is a regular CS BOF: It resides in a beacon, is executed via its go entrypoint and can make use of serveral CS BOF APIs. In order to execute the BOF, the beacon acts as a linker: it maps the BOF’s sections into memory, resolves CS BOF API imports to the beacon’s internal implementations and resolves relocations. That’s the regular flow of things.

Here’s how the general CS2BR approach works: it provides the CS BOF APIs as part of its compatibility layer. This layer in turn uses the BRC4 BOF APIs which are implemented in the BRC4 badger. From our perspective, a badger loads & executes a BOF similar to how CS does.
When we patch a BOF’s source code via CS2BR and compile it afterwards, the coffee entrypoint will be included in the BOF and able to invoke the original go entrypoint (*). Additionally, calls to the CS BOF API will be “rerouted” to CS2BR’s compatibility layer (*). When both BOF and the CS2BR compatibility layer are compiled separately though, we need to ensure that those two connections are made when we merge the object files. For simplicity’s sake, let’s refer to the compiled CS BOF as bof.o and to the compiled CS2BR compatibility layer as cs2br.o:
- Entrypoint: The
coffeeentrypoint incs2br.oneeds to reference thegoentrypoint inbof.o. When the files are merged, this reference must be resolved. - APIs: The CS BOF APIs imported in
bof.omust be “re-wired” so they don’t reference imports butcs2br.o‘s implementations instead.
Well, this doesn’t sound super complicated, does it?
III. Execution
Now it’s only a matter of putting everything together. We’ll start with the entrypoint:
Preparing the entrypoint
In order to reference bof.o‘s go entrypoint from cs2br.o, we can leverage the fact that such operations are precisely what object files and linkers are great at accomplishing: by defining go as an external symbol in cs2br.o, a linker will resolve it when also supplying it with bof.o which provides this exact symbol. So here’s the single line we add to CS2BR’s badger_stub.c that contains our custom coffee entrypoint:
extern void go(void *, int);
Now, when we compile CS2BR’s entrypoint in badger_stub.c and its compatibility layer beacon_wrapper.h, we observe the resulting cs2br.o‘s symbols. Also, for comparison, let’s also inspect bof.o‘s symbols:
$ objdump -x cs2br.o | grep go [ 52](sec 0)(fl 0x00)(ty 20)(scl 2) (nx 0) 0x0000000000000000 go $ objdump -x bof.o | grep go [ 2](sec 1)(fl 0x00)(ty 20)(scl 2) (nx 1) 0x0000000000000000 go
We can use Microsoft’s documentation on the PE format (which also covers COFF) to better understand what those entries mean:
sec: “The signed integer that identifies the section, using a one-based index into the section table. Some values have special meaning […].”- Value
0(IMAGE_SYM_UNDEFINED): “[…] A value of zero indicates that a reference to an external symbol is defined elsewhere. […]”
- Value
ty: “A number that represents type. Microsoft tools set this field to 0x20 (function) or 0x0 (not a function). […]”- The value (hex value before the symbol name): “The value that is associated with the symbol. The interpretation of this field depends on SectionNumber and StorageClass. A typical meaning is the relocatable address.”
scl: “An enumerated value that represents storage class. […]”- Value
2(IMAGE_SYM_CLASS_EXTERNAL): “[…] The Value field indicates the size if the section number is IMAGE_SYM_UNDEFINED (0). If the section number is not zero, then the Value field specifies the offset within the section.”
- Value
Using this information, we can deduct that:
cs2br.o‘sgosymbol is an external symbol defined elsewhere.bof.o‘sgosymbol is located in section 1 (.text) and located right at the start of the section (offset0).
When we merge them using ld (ld --relocatable bof.o cs2br.o -o brbof.o --oformat pe-x86-64) and inspect them in a disassembler like Ghidra, we see that the linking worked as expected and cs2br.o‘s coffee actually calls bof.o‘s go:

Nice, the first thing is done. This was pretty easy!

Rewiring CS BOF API imports
In the previous section we declared go as an external symbol in cs2br.o‘s source code. This allowed us to have the linker resolve the reference to the supplied bof.o‘s implementation of go.
Rewiring the CS BOF API imports of bof.o to cs2br.o‘s implementations isn’t as straightforward though. Let’s have a look at the symbols involved:
$ objdump -x cs2br.o | grep BeaconPrintf [ 24](sec 1)(fl 0x00)(ty 20)(scl 2) (nx 0) 0x00000000000005e1 BeaconPrintf $ objdump -x bof.o | grep BeaconPrintf [ 18](sec 0)(fl 0x00)(ty 0)(scl 2) (nx 0) 0x0000000000000000 __imp_BeaconPrintf 0000000000000027 IMAGE_REL_AMD64_REL32 __imp_BeaconPrintf
From this output we learn that:
cs2br.oexportsBeaconPrintfas a symbol that- is contained in section #1 (
.text) - is a function (
ty 20) - is at offset 0x5e1 into its section
- is contained in section #1 (
bof.oexports__imp_BeaconPrintfas a symbol that- has the
__imp_prefix, indicating that this function was declared using__declspec(import)and needs to be imported at runtime - is an external symbol (section value
IMAGE_SYM_UNDEFINED) - is not a function (
ty 0)
- has the
bof.oalso references__imp_BeaconPrintfin a relocation in the.textsection. Which makes sense considering thatBeaconPrintfis imported from the CS BOF API and its implementation is not included in the BOF’s source code.
The fact that __imp_BeaconPrintf referes to an import makes it special and more tricky to handle:
Contrary to how cs2br.o called go (which was a call to an address relative to the CALL statement), bof.o calls BeaconPrintf by absolute address that is read from the place in memory where __imp_BeaconPrintf is located. In other words, __imp_BeaconPrintf is a pointer to the actual implementation and a loader needs to calculate and populate this address at runtime.
If we wanted to make the linker resolve these references in bof.o like it did with the go symbol in cs2br.o above, we would need cs2br.o to export not the function implementations but pointers to those implementations. Then we’d still need to rename all the imported functions in bof.o so they don’t have the __imp_ prefix in their names anymore or else a loader might attempt to import them again (and fail doing so).
There are two major challenges to this though:
- How can we modify parts (such as symbols) of object files? The GNU utilities I found so far only allowed me to read but not write them.
- How can we debug merged object files? When we just execute any merged BOF via a BRC4 badger, the badger might just not output anything (in the best case) or straight up crash on us (in the worst case).
I’ll cover those next before continuing with the process of merging object files.

IV. Getting the right tools for the job
As outlined above, there are two major challenges related to the tooling I needed to overcome at this point.
Reading/writing COFF: structex
There are lots of COFF parsers out there that allow you to parse existing or create new COFF files. Only very few also allow for modification of existing files though. Since I wanted to stick with Python for the tooling for this project and couldn’t find a suitable solution for my needs, I decided to implement this functionality based on a Python library I programmed in the past: structex.
The idea of structex is that, as a developer, you don’t imperatively write down code to serialize or deserialize individual fields of data structures but instead describe the data structure to your application. The library then does the heavy-lifting and figures out which field is at what offset and does all the (de-)serialization for you. Then you can just have your application map data structures to some binary buffer and access fields of those structures like you access fields in Python classes. Here’s a brief example:
class MachineType(IntEnum):
IMAGE_FILE_MACHINE_I386 = 0x014c
IMAGE_FILE_MACHINE_IA64 = 0x0200
IMAGE_FILE_MACHINE_AMD64 = 0x8664
class coff_file_header(Struct):
# ...
_machine: int = Primitive(uint16_t)
NumberOfSections: int = Primitive(uint16_t)
#...
@property
def Machine(self) -> MachineType:
return MachineType(self._machine)
# Load BOF into memory & parse header
memory = BufferMemory.from_file('bof.o')
bof_header = coff_file_header(memory, 0)
print(bof_header.Machine.name)
# Prints: IMAGE_FILE_MACHINE_AMD64
bof_header.NumberOfSections = 0
# Write modified BOF back to disk
memory.to_file('bof_modified.o')
# bof_modified.o has now set its NumberOfSections to 0
All that I needed to do then was write down the data structures used in COFF, add some property decorators for even easier handling, and implement some bits of custom logic (e.g. reading & modifying the COFF string table). This allowed me to easily parse, inspect and modify any BOF files.
Debugging BOFs: COFFLoader
Implants are mainly designed to operate covertly, leave very few traces, and avoid getting noticed (and for that matter, sometimes even actively evade detection). This can make them hard to locate, observe and make sense of – not exactly ideal conditions for debugging. So I went out looking for alternatives.
It’s safe to assume that any program that executes BOFs does that in a way that is somewhat similar to TrustedSec’s COFFLoader. So why not use COFFLoader then? Well, it doesn’t support BRC4’s BOF API. Considering that COFFLoader is open source and the BRC4 API is pretty limited (as shown in our first blog post TODO: Insert link), it wasn’t terribly difficult to implement that functionality. I basically only needed to
- provide simple implementations of the BRC4 APIs,
- update COFFLoader’s
InternalFunctionsarray to point to theBadger*APIs, - update hardcoded uses of the length of
InternalFunctions, - update the check for symbol prefixes to check for the
Badgerprefix and - update the signature and exact call of the BOF entrypoint.
Since I didn’t want to spend much time on this, I kept the implementations of the BRC4 APIs very simple and didn’t add any sanity checks (or even proper formatting):
size_t BadgerStrlen(CHAR* buf) { returnstrlen(buf); }
size_t BadgerWcslen(WCHAR* buf) { return wcslen(buf); }
void* BadgerMemcpy(void* dest, const void* src, size_t len) { return memcpy(dest, src, len); }
void* BadgerMemset(void* dest, int val, size_t len) { return memset(dest, val, len); }
int BadgerStrcmp(const char* p1, const char* p2) { return strcmp(p1, p2); }
int BadgerWcscmp(const wchar_t* s1, const wchar_t* s2) { return wcscmp(s1, s2); }
int BadgerAtoi(char* string) { return atoi(string); }
PVOID BadgerAlloc(SIZE_T length) { return malloc(length); }
VOID BadgerFree(PVOID* memptr) { free(*memptr); }
BOOL BadgerSetdebug() { return TRUE; }
ULONG BadgerGetBufferSize(PVOID buffer) { return 0; }
int BadgerDispatch(WCHAR** dispatch, const char* __format, ...) {
va_list args;
va_start(args, __format);
vprintf(__format, args);
va_end(args);
}
int BadgerDispatchW(WCHAR** dispatch, const WCHAR* __format, ...) {
va_list args;
va_start(args, __format);
vwprintf(__format, args);
va_end(args);
}
I’m not very familiar with using gbd for debugging and do most of my coding in Visual Studio and Visual Studio Code and debugging in x64dbg. That’s why I also used this opportunity to set up COFFLoader as a Visual Studio solution. Now I could use COFFLoader to run my BOFs and Visual Studio and x64dbg to debug both COFFLoader and my CS2BR BOFs, neat!
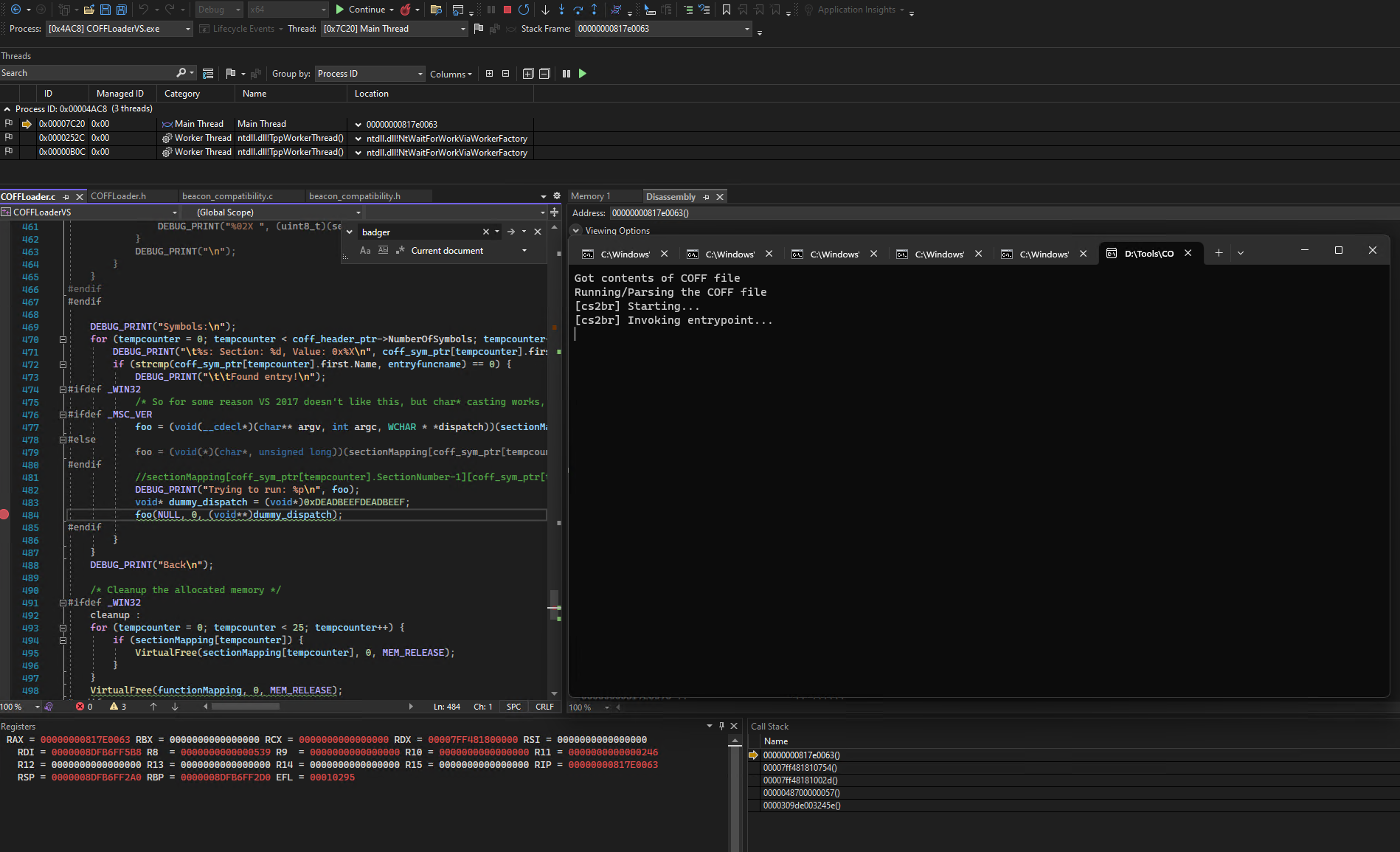
V. Finally: The CS2BR Binary Patching Workflow
RE: Rewiring CS BOF APIs
On the matter of actually rewiring CS BOF API imports, there are two things to consider:
- The relocations to the imports themselves are relative to the instruction using/calling them.
- The imports referenced by the code are pointers to the actual implementations.
Writing this, I realize that all of this sounds pretty abstract, so let’s have a look at an example:
Our
bof.osends text back to operators by using theBeaconPrintfAPI. Because of that,bof.oimports the API by defining a__imp_BeaconPrintfsymbol. This symbol refers to a place in memory where a pointer to the actualBeaconPrintfis stored.
For binary patching in CS2BR this means that we need to overwrite these pointers in bof.o to the actual implementations somehow so they point to CS2BR’s methods. These pointers are set by the loader (e.g. COFFLoader) though and that’s something we can’t control before or even at compile-time. So the question becomes: How can we make the loader point imports to CS2BR’s methods instead?
After staring at Ghidra, x64dbg, objdump output and my Python source code for more days than I’m comfortable to admit, I worked out a solution to this problem. It consists of some preparations and two processing phases that I’ll further detail in the following paragraphs.
The general idea is pretty simple:
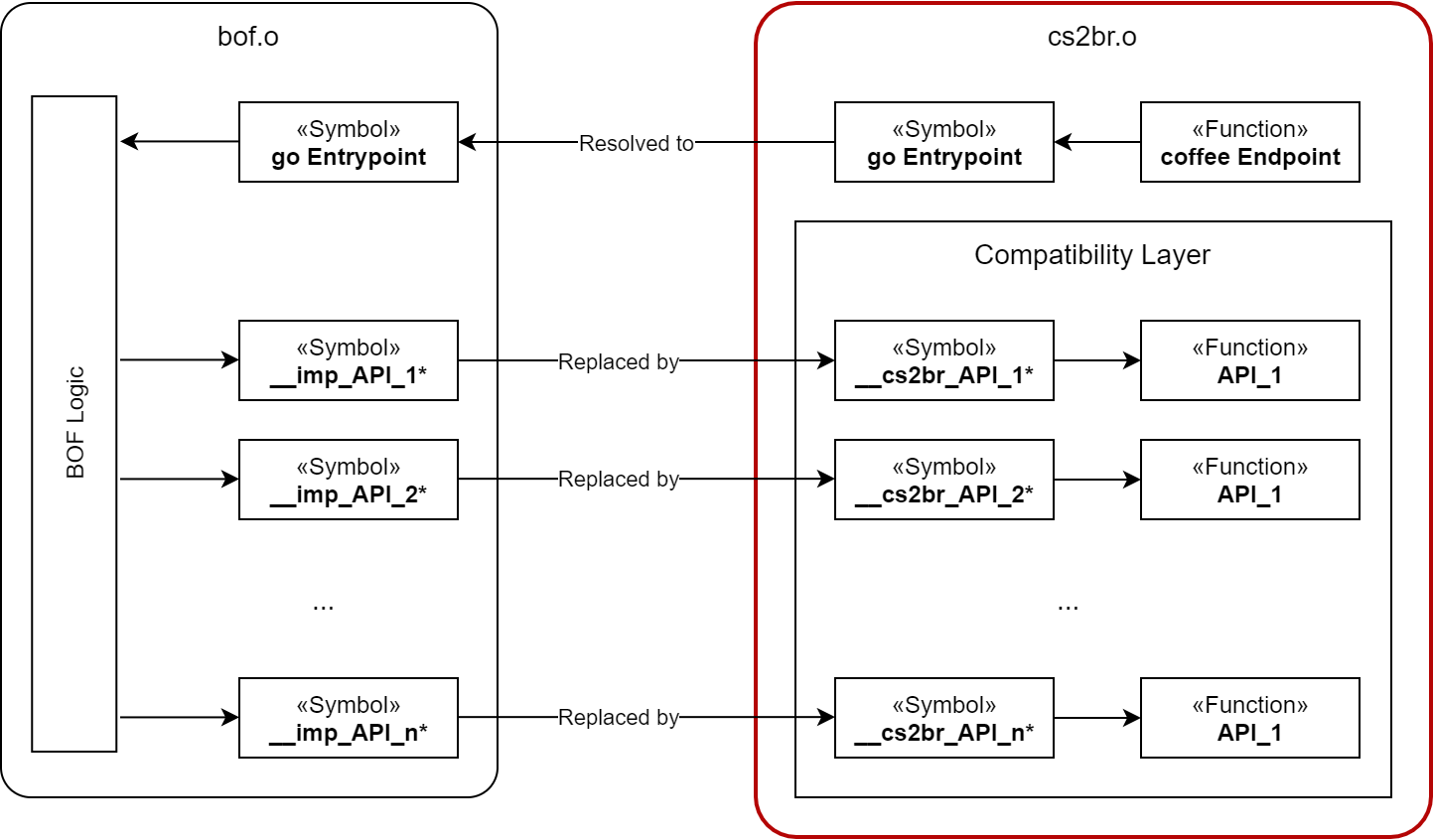
CS2BR defines pointers (prefixed with __cs2br_) to its compatibility layer’s methods. These pointers will also end up in its symbol table. After merging both object files, the __imp_ symbols (that originated from bof.o) to CS BOF APIs are replaced with the __cs2br_ symbols (provided by cs2br.o). This leaves us with symbols that are referenced relative to instructions and contain pointers to our desired CS2BR compatibility layer methods.
Here’s how the complete workflow is implemented in CS2BR:
1. Declaring the go entrypoint
As described earlier in this blog post, the compiled CS2BR object file needs to contain an external reference to the go entrypoint. To do so, I just added the a declaration of this method to CS2BR’s the stub: extern void go(void *, int);
This will make ld correctly resolve this symbol to the BOF’s entrypoint when we merge both object files.
2. Creating proxy symbols
Next, I added pointers to all of the CS BOF APIs implemented in CS2BR’s compatibility layer:
void* __cs2br_BeaconDataParse __attribute__((section(".data"))) = &BeaconDataParse;
void* __cs2br_BeaconDataInt __attribute__((section(".data"))) = &BeaconDataInt;
void* __cs2br_BeaconDataShort __attribute__((section(".data"))) = &BeaconDataShort;
// ...
3. Preprocessing the BOF
Before merging object files, CS2BR identifies all CS BOF API import symbols (named __imp_Beacon*) and reconfigures them:
for symbol_name in cs_patches:
symbol = osrcbof.get_symbol_by_name(f"__imp_{symbol_name}")
symbol.Value = 0
symbol.SectionNumber = 0
symbol.StorageClass = StorageClassType.IMAGE_SYM_CLASS_EXTERNAL
symbol.Name = symbol_name
symbol.Name = f"__cs2br_{symbol_name}"
symbol._type = 0
This reconfiguration achieves that the symbols are
- treated as external (section number
0, storage classIMAGE_SYM_CLASS_EXTERNAL, type0) and - renamed from
__imp_*to__cs2br_*, which allesldto resolve them tocs2br.o‘s defined symbols upon merging.
Then CS2BR renames the symbols of windows APIs that are available to CS BOFs by default (LoadLibrary, GetModuleHandle, GetProcAddress and FreeLibrary) so they have the __imp_KERNEL32$ prefix. This ensures that, if any of those APIs are used by the BOF, BRC4 imports and links them before executing the BOF.
4. Merging both object files
Both object files (bof.o and cs2br.o) are merged using ld. The resulting object file contains the sections and symbols of both files.
5. Recalculating ADDR64 relocations
At this point, both COFFLoader and BRC4 should be able to load and execute the patched BOF. Instead, COFFLoader just crashed and BRC4 gave me the silent treatment.
It turned out that the relocations were flawed and presumably not recalculated by ld. I’ll briefly describe that bug right now, you can skip to my workaround if you want to.
Broken relocations
Relocations are a tricky topic. In fact I don’t think I got my head fully wrapped around the topic myself. When I tested my BOFs at that point and saw COFFLoader crashing, I did a lot of manual investigation by debugging COFFLoader and tracing back why it crashed. Let’s have a look at an example:
We’ll execute a very simple BOF that only formats and outputs a string using BeaconPrintf:
#include <windows.h>
#include "beacon.h"
VOID go(IN PCHAR Args, IN ULONG Length) {
BeaconPrintf(CALLBACK_OUTPUT, "Hi from CS2BR %i\n", 1337);
return;
}
When executing the BOF in COFFLoader, it would end up executing some data, not actual instructions:
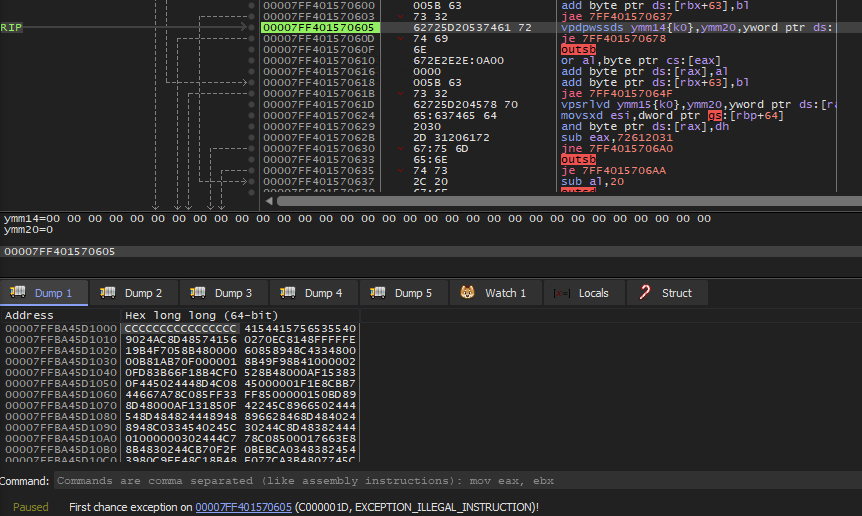
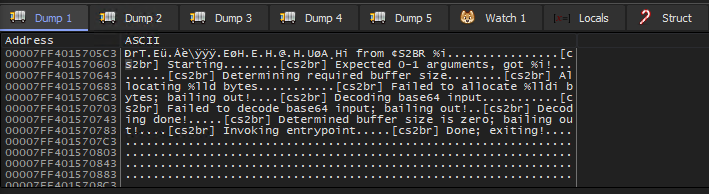
Inspecting the address of RIP in the dump, we can see that RIP lies in the .rdata section of the BOF as we can clearly see the strings used in cs2br.o‘s entrypoint:
By restarting and carefully stepping through the program we see that the coffee entrypoint is invoked correctly, so that bit works just fine:

It also reaches the go entrypoint:

The next call will fail though. It retrieves the address of the method to call from a pointer (mov rax, qword ptr ds:[7ff45d050068]) and calls that. Taking a look at the memory dump of the address of the pointer, we see that this is our .data section:

The 0xDEADBEEFDEADBEF is a dummy value I made COFFLoader pass to the coffee entrypoint to use as the _dispatch variable. CS2BR saves this _dispatch variable as a global variable in .data as can be seen in the objdump output:
$ objdump -x minimal.BR_bin21.o | grep "sec 3" [ 36](sec 3)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000000 .data ... 0x0000000000000068 __cs2br_BeaconPrintf [ 43](sec 3)(fl 0x00)(ty 0)(scl 2) (nx 0) 0x0000000000000050 __cs2br_BeaconFormatPrintf [ 44](sec 3)(fl 0x00)(ty 0)(scl 2) (nx 0) 0x0000000000000088 __cs2br_BeaconIsAdmin [ 45](sec 3)(fl 0x00)(ty 0)(scl 2) (nx 0) 0x0000000000000000 _dispatch [ 46](sec 3)(fl 0x00)(ty 0)(scl 2) (nx 0) 0x0000000000000070 __cs2br_BeaconOutput [ 47](sec 3)(fl 0x00)(ty 0)(scl 2) (nx 0) ...
As expected, the call fails at this point as it jumps to 0x00007FF45D0705E1 which is just some random offset into a method:

It should be pointing to 0x00007FF45D070621 though, as the .text section is mapped to 0x00007FF45D070000 and BeaconPrintf‘s offset into this section is 0x621. Apparently, the value of the pointer to BeaconPrintf is a whopping 0x40 bytes short. This left me confused for quite a while. And just by accident, I noticed something in the objdump output:
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000dc0 0000000000000000 0000000000000000 000000b4 2**4
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
...
5 .data 00000200 0000000000000000 0000000000000000 00001380 2**5
CONTENTS, ALLOC, LOAD, RELOC, DATA
...
SYMBOL TABLE:
...
[ 2](sec 1)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000000 .text
...
[ 28](sec 1)(fl 0x00)(ty 20)(scl 2) (nx 0) 0x0000000000000621 BeaconPrintf
...
[ 34](sec 1)(fl 0x00)(ty 0)(scl 3) (nx 1) 0x0000000000000040 .text
...
[ 42](sec 3)(fl 0x00)(ty 0)(scl 2) (nx 0) 0x0000000000000068 __cs2br_BeaconPrintf
...
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
...
0000000000000027 IMAGE_REL_AMD64_REL32 __cs2br_BeaconPrintf-0x0000000000000068
...
RELOCATION RECORDS FOR [.data]:
OFFSET TYPE VALUE
...
0000000000000068 IMAGE_REL_AMD64_ADDR64 .text-0x0000000000000040
...
Did you spot it? There are two .text symbols, of which one has an offset of 0x40 into the .text section. That same odd symbol is used in relocations of the __cs2br_* symbols.
The ADDR64 relocations for the entries in .data could be read as: “Read the relocation’s current value from its offset into .data (aka its ‘addend’), add to it the absolute address of the .text-0x40 symbol, and write the calculated sum back at the relocation entry’s offset in .data.” This doesn’t quite work though: these relocations aren’t relative to a symbol but to the section their symbols reside in. Thus, COFFLoader correctly resolves the relocation to the address of the .text section plus the relocation’s addend 5E1. We know the relocation’s addend is 5E1 by simply extracting it:
# 5096 is the decimal representation of 1380h (.data offset into the file) + 68h (relocation offset) od -j 5096 -N 8 -t x8 minimal.BR_bin.o 0011750 00000000000005e1 0011760
Here’s where the workaround finally comes into play!
(Cont:) 5. Rebasing ADDR64 relocations
Lastly, CS2BR recalculates relocations that
- are of type
IMAGE_REL_AMD64_ADDR64and - are associated to a symbol that doesn’t refer to a section but to an offset within a section (e.g.
.text-0x40).
For each of those relocations, it will acquire their current addend, add to it the value of the associated symbol, and write the newly calculated addend back to the image, as can be seen here with the __cs2br_BeaconPrintf symbol:
[INFO] Pointing relocation .data:0x68 from .text:0x40+0x5e1 (=> __cs2br_BeaconPrintf) to .text:0x621 (=> BeaconPrintf)...
VI. Demo
Patching a BOF using cs2br is very simple. One only needs to compile the compatibility layer (cs2br.o) and supply & run the patchbin.py script with paths to the BOF file to patch and the cs2br.o:

Running a BOF that was binary-patched by CS2BR works great in COFFLoader:
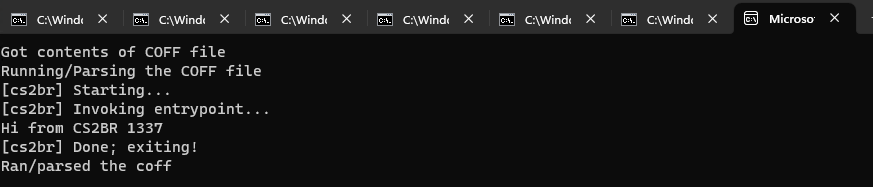
Not so much in BRC4 though:

At this point, there wasn’t much I could do. I certainly didn’t feel like putting more work into it and testing against a black box didn’t make much sense.

I did reach out to Chetan Nayak, the developer of BRC4, via Discord a couple of times during the project. Since this was an internal project at the time however, I couldn’t share CS2BR’s source code. Provided with a fully patched binary, they said the entrypoint was not found and never executed by the badger. Apparently, debugging this blob could take a lot of time and they can’t provide support for such BOFs.
This marks the end of my work on this project – for now.
VII. Conclusion & Outlook
This was one long blog post to write. Working on the tool and debugging BOFs certainly took a long time – I honestly underestimated the effort of documenting all of it in this post though. So, let’s have a look at what CS2BR accomplished:
CS2BR’s source-code patching approach works very well and enables operators to use well-known and battle-tested BOFs that were formerly (almost) exclusive to CS now in BRC4. While it requires access to source code and recompilation of BOFs, it does provide a solid compatibility layer.
In its current iteration, CS2BR is able to patch binary CS BOFs and make them (on paper!) compatible with BRC4. It works well in a modified COFFLoader that provides a simple BRC4 BOF API but doesn’t seem to work with BRC4’s badgers. The reason as to why it doesn’t is a mystery to me. As such, this iteration of CS2BR effectively isn’t usable. Since this is an open-source project, everyone is free to have a look for themselves and maybe someone finds a solution – in which case I would be thrilled to learn all about it!
Both approaches, the source-code and binary patching, make use of the same custom entrypoint which, depending on the exact BOF being executed, requires encoding input parameters with the provided Python script. It would be nice to automate parts of those by parsing the CNA scripts that accompany the BOFs and making use of the BRC4 Ratel Server API to simplify the process.
Afterthoughts
To me, this project was a rewarding, albeit intense and at times frustrating, journey and deep-dive into BOF development and the COFF format. I certainly learned a lot! To be frank though, the fact that this isn’t a success-story leaves me quite unsatisfied.
I’ll be laying down my work on this project for now and provide support for the source-code patching approach. Maybe some day Chetan finds some time to look into his BOF loader, though, and lets me know what’s wrong with CS2BR’s approach to patching.
Since you made it this far, I can only assume that you are very interested in the topic (or skipped a fair bunch of this blogpost). I would love to know your thoughts on the topic, so please leave a reply!

Moritz Thomas
Moritz is a senior IT security consultant and red teamer at NVISO.
When he isnât infiltrating networks or exfiltrating data, he is usually knees deep in research and development, working on new techniques and tools in red teaming.
如有侵权请联系:admin#unsafe.sh