以下为速记全文:
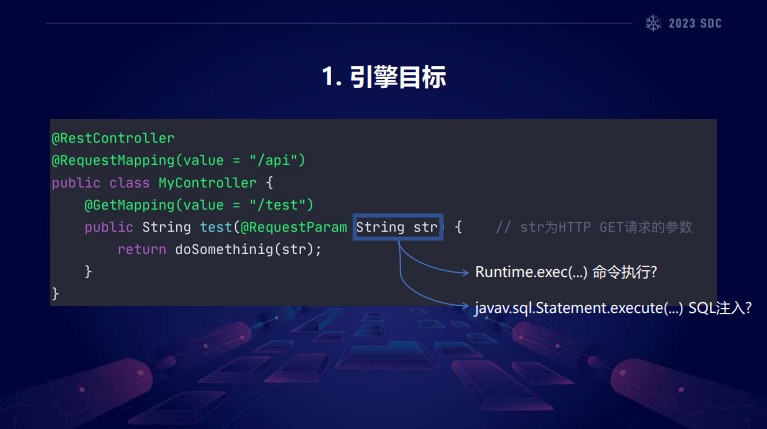
大家好,我是来自京东安全的陈浩浩。本次将由我为大家介绍我们开发的针对Java web应用程序的一个静态分析框架JDoop。我们认为各种Java类型的漏洞,其实都是数据流类型的漏洞,这种漏洞可以被总结为两个方面的问题,一个是数据流向的问题,就是不可信的数据流向到了某种危险的方法中,还有一个数据过滤的问题,在过滤不可信数据的时候出现了一些遗漏,比如说在这里filter()函数过滤的是否完善,属于过滤的一个问题,这个问题就比较复杂了,难以去自动化完成,只能通过人来处理,因此我们则尝试去解决数据流的流向问题。我们项目目标就是去构建一个静态分析引擎,你给定它一个 Java项目,然后它能够自动分析出来自HTTP的那些不可信的数据是否会流向某些危险的函数。这是我们项目的一个整体的架构,大致可以分为前后端两个部分,前端负责去拆解那些架jar包,然后并通过soot将自解码反编译为Jimple格式的IR,右边是Jimple格式的一个例子,Jimple它更加类似于那种Java的源代码了,而且它可以去拆解掉各种原本的语法糖,也更加直观易懂。由于我们是基于Datalog的一个分析,所以仅仅将它反编译为Jimple是不够的,我们还需要将Jimple转换成facts, facts它其实就是一系列的关系表,表示程序中相关的一些指令的一些操作,比如说这里有b=a、c=b那么就会得到一个关于变量之间Assign的关系,就是有b=a、c=b然后New也是类似的。接下来是Datalog分析规则,Datalog分析规则它其实就是在一系列的facts上进行一些逻辑推导,比如说这边是两条简单的指针分析规则的一个例子,如果你有New关系,New出了一个对象o赋给了指针p那么就可以推导出 p指针应该指向对象o; 如果你有指针赋值语句to=from,并且from指向对象o,那么就可以推导出to它应该指向对象o。在提取出facts和编写完Datalog推导规则之后,就可以一起去递交给一个专门的Datalog求解引擎souffle,进行一个求解的工作。比如说这个例子你全都交给souffle之后,它就会自动推导出指针abc都应该指向对象o。为什么我们要采取这样一套看起来比较冗长的架构?第一是Datalog分析规则,它其实与指针分析规则是天然一致的,如果你尝试用Java去编写过指针分析规则的话,你会发现它相较于Datalog来说,它非常不直观,比较晦涩难懂。第二,这样的架构可以将指针分析规则的求解与规则的编写过程进行一个解耦,我们人就只需要专注于规则的编写上面,这样可以提高一个开发效率。第三 souffle它的求解性能是非常高的,他利用了很多c++模板的技巧,还有高效的数据结构,也支持多线程求解,它是比你手写一个worklist的大循环,那种效率是高很多的。第四点是因为Doop框架它是一个静态分析的集大成者了,它里面有不少对于反射分析规则的处理,我们只需要对这些规则进行少量的改动,就可以使项目拥有不错的反射分析能力。污点流方面我们采用的是P/T Analysis算法,,这个算法他认为指针分析与污点分析它们本质上是高度一致的,指针分析研究的是你new出来的那些对象的流动,而污点分析它研究的是那些不可信数据的流动,因此这个算法就认为我们可以将两个分析合二为一。它具体是这样做的,首先对于这些source点,它返回一个特殊的String类型的一个对象,并将其标记为污点对象,然后将污点对象和普通对象一样的正常参与指针分析的过程,进行一个指针的对象的流动。最后在对于sink方法调用的地方去检查,如果调用时 sink方法的使参指向某个污点对象,那么则可以认为你source点产生的数据就流到了sink点中,一条污点流就成立了。我们分析算法它有很多优点,首先是只需要对原有指针分析框架进行少量的改动,便可以实现P/T Analysis算法了。第二点是由于你一次性同时完成了指针分析和污点分析,所以它的很多重复步骤都是被合并了的,它的分析效率也会更高。第三点也是最重要的一点,就是因为你现在污点对象与普通的对象是一起去分析的,所以如果你的指针分析支持一些像lambda还有反射的一些处理的话,那么你的污点分析也就可以天然的继承下来,这个是十分的方便的,不需要再额外编写特殊的规则了。但是需要注意一点,就是在污点对象它的传播过程中,它的类型可能会变的,有可能会被各种各样的方法去操作,比如说这个例子就是你new出来的String对象通过String与其他的那些字符串进行一个合并拼接操作,然后又通过toString()生成了一个新的String对象。由于我们在为source()方法创建String对象的时候,并没有处理其内部的各种字段,这就导致append()方法在访问String的value字段的时候什么也访问不到,该字段是没有任何对象的指向关系的,这样就导致污点流,它在流到append()的时候就中断掉了,导致了一个漏报的情况。对于这种方法的这个问题, P/T Analysis它的解决方法比较简单粗暴,他是提出了一个叫taint transfer的概念,taint transfer它其实就是一条特殊的污点传播规则,用于去描述该方法对于污点对象传播的一个作用。比如说这里append()方法就可以添加一条额外的taint transfer,如果说你的它的参数str指向污点对象,那么它的base指针buf也应该指向一个污点对象。在调用toString()方法处理的时候,如果buf指向一个污点对象,那么它也会返回一个String类型的污点对象。这样子taint transfer就像是一个桥梁一样,把那些断掉的部分又给连接上去,最终又跑通整个污点流了。但是在实际的操作过程中,我们发现taint transfer它是有很多局限性的,比如说这个例子就是str.getChars(),如果我们为它添加一条taint transfer的话,就会生成一个 char[]类型的污点对象,arr指针可以指向一个char[]类型的污点对象,但是这个对象它其实是个空壳子,这个数组的索引它是没有任何指向关系的,这就导致后面在尝试访问这个arr[0]的时候,你什么也获取不到,又会导致一个漏报的问题。实际上这个问题是比较复杂的,因为taint transfer它生成的污点对象的类型非常多的。比如这个是Doop里面的两条规则,它有可能生成LinkedList类型,有可能是Iterator, HashMap或者一些其他的Set类型,所以如何处理污点对象的一个字段指向问题,这是比较复杂的。首先是一个简单的思路,如果我们不设置污点对象内部字段的任何指向关系,虽然很简单,但是这个显然会导致大量漏报的情况,那么如果我们让污点对象内部所有的字段都指向一个污点对象的话,这样又会导致很多误报的一个情况。那么有没有那么一个折中的思路,我们只让污点对象内部的部分字段指向污点对象,这样子的话,因为taint taransfer可能会生成各种各样类型的污点对象,我们就需要考虑各种类型,并且规则也会非常复杂,也是不太行的。那么有没有什么简单而优美的方法可以解决呢?我们发现其实我们只需要在污点传播的过程中,关注String类型的对象就可以了。这其实是基于一个观察。我们发现source点它往往只会生成String的污点对象,而对于sink点的参数,它也往往都是String类型或者是String相关的一些衍生类,比如 String[]这样子的。所以我们在污点传播的过程中,只需要考虑String或者是String相关的那些操作涉及到的类型就可以了,这样就大大简化的 access path问题。比如说之前这个例子string.getChars(),我们会令其arr指向一个char[]类型的对象,并且为该数组的索引添加一个指向关系,令其指向char类型的污点对象,这样子在访问这个数组的时候,这个数不是个空壳子了,在arr[0]就会获取我们刚刚放的char类型的污点对象,这样子整个污点流就又继续跑通了。现在taint transfer它是只会生成char相关的污点对象了,那么对于一些容器类,比如List这样该怎么处理呢?我们经过研究后发现,其实容器类并不适合使用taint transfer去建模,我们应该使用mock JDK的方式去直接修改其在jdk中的实现,使用数组去代替其实现,使其变得更加容易分析,然后正常参与到分析的过程中,比如说这LinkedList的,就让其在内部的一个数组中直接给它放入污点对象,然后list.get()再取出来,为什么要这么做?因为taint transfer它只是对于污点对象的一个传播。倘若你为这个容器类进行一个taint transfer的建模的话,那么普通的对象是没法通过才能taint transfer进行传播的,这会导致你构造出来的CallGraph它是不完整的,这样就会导致漏报。所以我们总结一下,我对于它原版的taint transfer,它是有可能生成各种各样类型的污点对象的,并且还没有处理这些对象内部的字段的指向关系。为了解决这个问题,我们对这个问题进行了细化,首先是限制了taint transfer它的适用范围,只生成了String操作相关的一些类对象,以简化 access path问题。第二点是通过mock JDK的方式去代替原本的一些容器类的实现,而不是将单纯的使用taint transfer进行处理,这样子这些容器类可以在指针分析的过程中,将普通的对象和污点对象一视同仁,不进行特殊对待,这样也是更加符合P/T Analysis的一个思想。以上是污点分析算法方面的一些改进,想要进行实际的分析,还涉及到一个上下文策略方面的改进,静态分析的时候,如何为被叫方法选取一个它的上下文,成为上下文策略。传统的策略有callsite sensitivity就是使用调用这个方法的调用语句作为它的上下文元素,有object sensitivity使用被调用方法的receiver object作为被掉方法的一个上下文元素,还有type sensitivity以及其他的策略. 在动态执行中,每一个调用帧都会被依次压入到调用栈中,整个调用栈它是共同构成了被调方法的一个上下文。但是在静态分析的时候,我们会选取一些上下文元素,每一个上下文元素其实就是对于一个调用帧的抽象,然后多个调用元多个上下文元素组合起来,共同构成了被调方法的一个上下文。因为在静态分析的时候,由于我们要考虑各种各样的分支,而且计算时间是有限的,我们不可能让上下文变得无限长,所以一般往往只会选择有限长度的上下文,比如典型的3-callsite-sensitivity,它就是选择最近的三个调用点作为它的被调方法的上下文,那么对于更早之前的调动点,就直接给忽略掉了。我们研究发现其实在选取上下文元素的时候,不能按照那种单纯的先来后到的一个原则,因为不同上下文元素的区分性是不同的,应该在有限的上下文长度当中,去保留那些更具有区分性的上下文元素。下面是我一个例子,比如说第一个入口类cookie1.getValue(), getValue()方法,它的上下文原本应该有两个元素,分别是 requestObj1和cookieObj,但是如果你是传统的1-object-sensitivity的话,按照先来后到的原则,因为上长度只有1,所以必须要丢弃一个,那么就会丢弃更早的requestObj1。对于第二个方法,对于第二个入口类 cookie2.getValue()同样也是类似的,由于你上下文长度只有1,所以会丢弃更早的requestObj2,这样上下文就只剩下一个cookieObj。这样会导致什么后果呢?cookie1.getValue()与cookie2.getValue(),它们这两个方法被掉方法的上下文是完全一致的,这样就会导致这两次调用中他们这个方法中的指针的指向关系会被并在一起,就会导致数据流混淆的情况。我们可以去直观感受一下,处理HTTP请求的不同入口类,它们之间的数据流肯定是区分的越开越好的,因为你每一次对于 HTTP请求的处理都是独立的,所以我们应当在上下文元素中去保留那些与入口类相关的一些元素。比如说这里的requestObj1,他就是T1的处理get请求的入口类的请求对象,还有requestObj2,它就是入口类T2中的 HTTP请求的对象,他们这两个对象都是与入口类相关的,如果我们选择去保留requestObj1和requestObj2会发生什么呢?同样是对于cookie1.getValue()的调用,由于requestObj1它与入口类相关更加具有区分性,所以我们这次予以保留,而不是简单地丢弃。我们选择丢弃没有什么区分性的cookieObj。对于cookie2.getValue()也是类似的一个策略,我们选择保留requestObj2而丢更新的cookieObj,这样我们发现cookie1.getValue()与cookie2.getValue(),他们两次上下文是不同的,这样我们就成功区分了来自不同入口类的污点流,避免了一个数据流混淆的情况。下面是一个对比,横坐标是测试压力的数量,纵坐标是分析出 的污点流数量,正常来说你提供n个测试样例,那么最多分析出n个污点流,所以正常情况下应该是一个线性增长的,但是如果我们采取黄色这条传统的1-object-sensitivity策略,可以发现污点流的数量是随着测试样例数量按照平方级别增长的,在只有60个左右测试样例的时候,污点流就已经达到了3000多个了,基本上就是已经接近60的平方了。如果去换成我们刚刚说的去保留上下文相关元素的这样一个上下文策略,可以发现它基本上整体都是按照一个线性增长的,这样子我们不仅去大大减少了数据流混淆的一个情况,而且还十分有效的去降低了数据流的分析压力。因为你随着污点流流的这种指数级平方级别的上升,你后续分析200 300 400个前的时候是直接会OOmM分析不出来的。与此同时我们还观察到一个比较反常的情况,正常来说,上下文长度越短,那么能区分的方法就越少,要分析的指针也就越少,分析压力会越轻。但是我们做了测试发现上下文长度为6/3/1,这样子的话它随着上下文长度的减少,要分析的指针数量反而是越来越上升的,这个就与我们的一些认知相悖了,那么为什么会发生这种情况呢?要回答这个问题,我们需要先思考一下上下文程度减少导致什么后果。假设我们有n个测试样例上下文长度为k的话,那么那么我们指针分析要分析的量大概是按照n乘k这样去增长的。那么随着k的下降,整体指针指向关系是一种线性的下降速度,但是由于你上下文变短了,更多的上下文会被更多方法的数据流混淆在一起,这样就会导致了一个更严重的数据流混淆问题。别忘了我们使用的P/T Analysis算法,它是在指针分析与污点分析一起进行的,污点流数据流的一个混淆就会导致指针分析数据流混淆,导致指针指向关系是非常多的,最极端的情况就是你任意两个入口点,他们的数据流都会混在一起,也就是说你提供了n个测试样例,那么极端情况下它就会分析出 n的平方级别个指向关系,上下文k的长度的减少,虽然它会导致指针指向关系线性的减少,但与此同时由于数据流混淆的情况,会导致指针指向关系同进行一个平方级别的增加,增加量是非常多的,所以上下文长度越少,要分析的指针越少,这句话是成立的,但成立的前提是对于指针分析而言的,而不是对于P/T Analysis的算法这种指针分析和污点分析同时进行而言的。所以我们认为在分析javaEE程序的时候,应当尽量地去增加上下文长度,来尽量避免数据流混淆的情况,这样反而会减小分析压力。以上就是算法方面的改进,如果想要将其实际应用到程序的扫描中,我们还必须要考虑一个Spring框架适配的问题。在最开始前端进行反编译的过程中,我们就发现 soot存在一个问题, shoot它其实不只是一个简单的反编译作用,了解过的同学应该知道它自身也是具有一些比较简单的指针分析能力的,比如说我们指定为入口类开始进行一个反编译,那么soot就会通过指针分析出哪些类是可达的,然后后续反编译的过程就只会去分析这些可达类,但这时候就涉及到一个问题了,万一它soot的分析是错误的,也就是说某些你实际运行时可达的方法被soot给丢弃掉了,soot认为他们不可达,比如说这里m3方法有可能通过反射调用到了方法m7, m8方法有可能是Spring框架的入口方法,被Spring框架引用到,这时候就会产生一个漏报的问题,因为方法m8和m7在前端的反编译阶段就已经被忽略掉了。一个简单的想法是我干脆全部都反编译得了,但实际上这样做是不可行的,因为你全部反编译的话,就会给后续的整个流程造成非常的压力。所以我的处理方法是在最开始就额外使用soot进行了一次预分析,预分析的目的,就是去分析出那些隐式可达的方法,去作为后面反编译的一个入口点来解决遗漏的问题。这个识别它不会进行任何的指针分析,它十分的简单,首先会把所有的字节码都反编译为R,然后去遍历这些类,如果发现这个类他被String相关的注解了,这就说明这个类有可能通过Spring框架访问到,就会将其纳入到分析范围中,与此同时它还会遍历程序中的所有的字符串常量,如果发现这个字符串常量是个类名,那么就说明这个类有可能会通过反射相关的操作被访问到,那么也会认为其是可达的,从而将其指定为后面反编译的一个入口类,这样就解决掉了一个静态分析时隐式可达的丢失的一个问题。第二点是Spring框架,它会在动态执行的时候会进行一个bean的创建,还有bean之间的依赖注入的处理。Spring框架是一个复杂的框架,我们不可能在静态分析的时候直接从框架的入口点进行分析,所以最好的策略是编写一些规则去模拟Spring框架的行为。我这边是通过编写规则支持了一个基于注解去识别和创建那些bean,并且基于注解去处理了bean之间的依赖注入机制去模拟框架的行为。比如说第三点是你需要为这些Spring框架的入口方法的一些参数去给它添加一个污点对象,比如说这里user,注意,我们不能直接去创建一个user类型的污点对象,因为这会遇到我们之前说的一个问题,我们应该去创建一个user类型的对象,然后去遍历对象中内部的所有字段。比如说这里有个name,它是String类型的,我们就令name字段指向一个String类型的污点对象,去填充类。下面是我们的一个beanchmark,我们的测试样例是选择是owasp benchmark v1.1,上面的命令注入部分的样本总共是2708个,然后我们最终测试的准确率是84.80%,召回率是100%。然后右图是我们是与其他的一些工具的一个对比,可以发现我们JDoop它的准招率是更靠近左上角的ideal区域,其得分也是最高的,然后下面会将会由我的同事为大家介绍JDoop的使用和它的一些特点。大家好,我是来自京东安全的陈光义。下面由我继续向大家介绍一下JDoop的使用流程和它的几个特点。首先是使用流程在该流程图中需要使用者来完成的是项目打包和规则编写两个部分,项目打包的话JDoop支持解析War包和Jar包两种打包格式,项目编写的话只需要完成sink点的编写,而无需完成source点的编写,JDoop目前支持通过框架适配的方式,可以自动识别所有的web入口点,而在完成这两部分之后,通过运行python脚本的方式,它会进行对项目进行一个解析,并调用匹配相应的 sink点规则,然后输出一个结果,该结果会包括一个source点 、sink点以及污点参数,也可通过运行相应的脚本来获取完整的污点数据流调用栈。JDoop的几个特点,一个特点是源码解析可选,安全人员在使用其他Java静态代码分析工具来分析项目的时候,可能会遇到你在获取的源码是一些预编译好的jar包,导致工具无法对其进行一个解析,又或者是预编译好的jar包中的 依赖包比较多,解析的时候需要耗费比较多的时间,那么JDoop是通过自定义规则的方式,可动态来选择需要解析的源码,来提高分析的效率。第二个特点是易编写多实现的sink点规则,易编写指的是我们通过对sink点的一个优化,达到了让使用者可以更快速的理解并上手编写规则,多实现指的是使用者在编写sink点规则的时候,可能会对污点映射的需求不只是一对一,还需要一对多、多对多的一个映射需求。那么我们是通过将同一条规则写入不同的tsv文件中,即可实现不同的匹配规则。第三个特点是污点流的优化,我们通过对算法的优化以及函数调用的识别,解决了污点参数在经过多层封装以及像Java反射调用导致断链的一个问题。如图所示的是通过一个maven install打包的Jar包的结构,JDoop默认会将源码和Jar包中第三方依赖包进行一并的解析,然后也可以通过自定义过滤规则的方式来选择需要解析的依赖包来提高分析的效率。需要注意的是如果你选择了某个依赖包不进行解析的话,则不能将sink设在该依赖包中,它会导致数据流传递的一个断裂。如图所示是一个freemarker模板注入的漏洞代码,假设字符串变量可控的话,它会传递到模板中并调用的process方法对其进行一个解析,最后会触发freemarker execute类下的exec方法,触发了Runtime exec导致了命令注入。在该项目中,如果我们选择不解析freemarker这个依赖包的话,则不能将sink点设在freemarker execute类下的exec方法,它会导致数据流在传递到freemarker依赖包的时候,就会导致一个链路的断裂。sink点规则的编写,这里以Runtime exec为规则,向大家展示两种主要的sink点规则的编写,即可实现一对一、一对多以及多对多的一个污点方法的映射。首先是一对一的污点规则的编写,该部分该规则分为三个部分,第一个部分为cmdi表示的是该规则的一个签名,是可自定义的,是起到一个提示的作用。第二个参数零表示的是污点方法的第一个参数为污点参数,第三个部分为该污点方法的一个签名,该部分包括类名、返回值类型、方法名以及参数类型,该3部分可组成一条完整的sink点规则。第二个部分是一对多、多对多的sink点规则,如右下所示的一个sink点规则,它表示的是指向了Runtime类下的所有exec函数重载的第一个参数为污点参数,也可将此规则置于我们内置好的其他的tsv规则文件中即可表示指向的是Runtime类下exec的所有承载方法以及它的第一个参数及其之后的所有参数都为污点参数。该漏洞代码为一个反射调用了Runtime exec的命令注入代码,污点流是从cmd参数值最后传到了Runtime exec。在该漏洞代码中,首先是调用了 Rce类下的exec方法,又通过了反射调用了Runtime exec导致命令注入,那么JDoop是如何处理反射调用导致断裂的问题,它是怎么解决的呢?在Java中想获取类的方法有很多,如果类已经加载的话,我们可以通过类的class属性来获取类,也可通过像类对象的getClass方法来获取类,亦可通过像Class.forName、loadClass等方法,基于字符串常量的方法来获取类,JDoop主要是解决了基于字符串常量反射调动的一个识别。在处理反射调研过程中,JDoop会先记录一下Method对象的方法名以及Class对象的一个类名。然后再识别Method对象invoke方法的一个调用,通过方法名加上类名的方式来和sink点规则进行匹配,来判断是否调用了一个sink点。所以在该样例中,我们只要sink点设置Runtiem.exec中,JDoop就可以把整个污点进行跑出来。该图所示一个代码样例是log4j的部分污点数据流,在21年时候Log4j席卷全球,然后网上出现了很多的分析案例,然后也有不少人尝试通过像CodeQL等静态代码分析工具来尝试自动化还原Log4j的污点数据流。在尝试自动化还原的过程中,大家会发现污点参数在经过二次分装指向logEvent对象后,CodeQL则不认为它是一个污点对象,则会产生一个断链的问题,我们需要自己通过净化函数将它进行接上,那么JDoop它又是如何解决这个问题的呢?JDoop路径分析算法的核心思想是把污点对象像正常对象一样进行传播。然后最终是检测sink点规则的参数集合中是否包含了污点对象来判断是否污点成立。所以在该样例中,我们只需要将sink点设在Context的lookup的方法中,即可将Log4j的污点数据流跑出来。下面通过一个简单案例来分享一下如何使用JDoop来挖掘漏洞。Jeecg-Boot该框架在护网中多次曝出过漏洞,已在今年的护网中爆出了未授权freemarker这个模板注入漏洞,该漏洞的Source点是在积木报表依赖包中,然后它的sink点最终是在实体化模板这个方法,所以我们将它的sink点最后设在了是实例化模板方法,并将它的第二个参数设为污点参数,通过该规则最后是跑出了两条污点流。第一条污点流对应的则是今年爆出了漏洞的web入口。第二个污点流则是对应的是我们通过JDoop跑出来的一个新接口,经过验证,该两个污点流均真实存在漏洞。最后分享一下自己的使用感受。JDoop比较好的点,一个在于它的源码解析,可以通过自定义规则的方式来选择需要解析的源码,可提高自己的分析效率,以及在污点流传递上的优化,通过优化反射调用污点经过多次封装导致断链的问题,然后我们可以用更少的规则,更简单的规则匹配出较为复杂的污点数据流。那么待提高的部分是用户体验上,目前各种操作还是基于命令行的形式,以及它无法像CodeQL等工具那样,通过点击某个具体的污点流节点的方式来跳转到具体的污点函数。第二个待提升点就是计算资源上,目前想要运行,把JDoop这款工具跑起来还是需要比较高的配置,以及像可能一些比较大的java项目还需要更高的配置。*峰会议题PPT及回放视频已上传至【看雪课程-2023 SDC】
链接:https://www.kanxue.com/book-leaflet-171.htm
PPT及回放视频对【未购票者收费】;
【已购票的参会人员免费】:我方已通过短信将“兑换码”发至手机,按提示兑换即可~
![]()
《看雪2023 SDC》
看雪安全开发者峰会(Security Development Conference,简称SDC)由拥有23年悠久历史的顶尖安全技术综合网站——看雪主办,面向开发者、安全人员及高端技术从业人员,是国内开发者与安全人才的年度盛事。自2017年七月份开始举办第一届峰会以来,SDC始终秉持“技术与干货”的原则,致力于建立一个多领域、多维度的高端安全交流平台,推动互联网安全行业的快速成长。
文章来源: https://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458527530&idx=1&sn=745a7ac176dad8343c481a57d2c2dde7&chksm=b18d17a086fa9eb6aa59de093d947507f1b33d0af65b53f4522b7f173117cae0e1dba4f12da1&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh