2023-11-9 12:5:0 Author: reusablesec.blogspot.com(查看原文) 阅读量:5 收藏

Everything that happens once can never happen again. But everything that happens twice will surely happen a third time.
-- Paulo Coelho
Introducing the JupyterLab Password Cracking Framework:
For the last couple of months, I've been (slowly) working on building out a new backend/framework to be able to manage password cracking sessions using JupyterLab as the frontend/GUI. The current version of this framework is available [here].

This project is under active development (well active for me anyways), and I'd really appreciate feedback and suggestions on how to extend and improve it. My goal is to have an opensource, community driven alternative for Team Hashcat's List Condense (LC) collaboration server ready by CMIYC2024.
About The Framework:
I view JuypterLabs as a stone soup. It provides a good interface, interactive Python debugger, and a way to save and share analysis results. But it is still up to you to do all of the backend analysis. That became very evident when I used JupyterLabs in the CMIYC2023 contest (as detailed in the previous three blog posts on this site). I spent a lot of time debugging my code and messing with data structures when I really needed to be focused on cracking passwords. I quickly realized for this approach to be effective in future password cracking contests that I'd need to develop back-end data structures and classes to better organize all the data and provide built-in features to aid in common tasks.
Backing up a bit, in the past I've really enjoyed using MITRE CRITs (Collaborative Research Into Threats) [Link]. Unfortunately CRITs is no longer being maintained (the switch from Python2 to Python3 killed the project), but it was a tool for CSOC (Cyber Security Operation Center) team members to collaborate with each other when analyzing intrusion sets and threat actors. CRITs organized Top Level Objects (TLO) into the following buckets/categories:
- Actors
- Campaigns
- Certificates
- Domains
- Emails
- Events
- Indicators
- IPs
- PCAPs
- Raw Data
- Samples
- Targets
It then made the data available in these different buckets cross linkable as well as accessible to various plugins. Following that approach, I created several different TLOs for this password cracking framework:
- Hashes: Contains information about the hashes including plaintext values, hash types, etc
- Targets: Contains information about particular targets/users and metadata
- Sessions: Contains information about a cracking session. The closes CRITs equivalent would be Campaigns.
- PWCrackerMgr: Not really a data structure, but a way to translate between Hashcat and John the Ripper cracking sessions
In the future as this toolset becomes more developed, I may end up taking a lot of the metadata out of Targets and putting it into its own TLO much like CRITs did. Also longer term, I may end up incorporating disk storage or a database, but for now I'm keeping this focused on helping with password cracking competitions, (vs. activities like pen-testing and managing ALL my password lists). You can download the framework right now, and it already has some example Notebooks in it that show how to use it on the CMIYC2023 challenges.
What this framework WILL NOT do is crack hashes or run your actual cracking sessions. I may add some scripting/logging support in the future, but this framework is focused on helping with data analysis as well as automating some of the busywork/repetitive tasks in a password cracking competitions such as creating custom wordlists, left list, translating between JtR and Hashcat, and hash submission.
Using the Framework to Crack CMIYC2022 Challenges:
A big question I have is how effective will this framework be in the NEXT password cracking challenge? Since I can't predict what Korelogic is going to do (beyond the fact that Bon Jovi references will somehow be involved), probably the best thing I can do is look back at past competitions. To that end I figured I might dig up the 2022 contest hashes and attempt to crack them again.
To obtain the challenge files, you can visit Korelogic's 2022 contest page [here].
Side note: Mad props to Korelogic for continuing to host past contest files. I really appreciate it!
Also, I had written a short blog post about my experiences in the contest, which is available [here].
I'll admit, it's always hard looking back on past work/documentation, but I'm a bit annoyed with my past self. I think that blog post has a lot of good information in it, but it really doesn't go into too much detail about the contest itself. On the plus side, that will make using this framework for this challenge more "realistic" since I can't just rely on my past documentation, and I have very hazy memories of what happened over a year ago.
Unpacking the Contest Files:
The CMIYC2022 contest had three file "drops" over the course of the challenge. Aka not all the hashes were released at the start, so this gave teams something constantly new to bang their heads against.
The contest files are PGP encrypted and as a player you need to decrypt them with the password that KoreLogic provided. Since the first thing I always do is Google "How do you decrypt PGP files" I'm going to put the command here for future me. Also this will hopefully disabuse you early on the false idea that I know what I'm doing ;p
- gpg -o <output_file> -d <input_file>.pgp
Do that for all three files, saving them with .tgz extensions. Then unzip the files using the command:
- tar -xvzf <input_file>.tgz
This creates three different directories filled with different encrypted file types. These are:
- cmiyc-2022_street_1/
- list18-Thursday17January2021.odt
- list17-TOWMINTP.hashes.gpg
- list19-paidanextra500000.zip
- list20-Authoritiesappeartohaveuncoveredavastnefariousconspiracy.7z
- list24-ThisYearsWorst.pdf
- list16-FL_kdIZUGpI.zip
- cmiyc-2022_street_2/
- DEFCON-Street.kdbx
- cmiyc-2022_street_3/
- rar.sdrawkcab
- 1991whattimeisit.tgz
Cracking the Encrypted File Containers (Part 1: File Extraction):
This competition starting to come back to me. The main issue with this challenge was to figure out how to crack the various encrypted file types. Once you cracked the top level file, it would present you an internal hash_list of fast to compute hashes that you need to crack for actual points. For the street teams, the top level file hashes are encrypted with fairly easy to guess passwords. For the pro teams ... not as much.
In my previous writeup [here] the first two "Tips" cover how to set up John the Ripper to crack these files. I'm going to largely skip those tips here, but assuming you followed them, the following commands can be used to extract and save the hash for the above file to a single file you can crack. I'm appending them all to a "encrypted_file_hashes.hash" file that I can load into JtR. If you want to use Hashcat to crack the hashes instead, you'll need to do some additional fixups to remove things like the username (or run hashcat with the --username field). Side note, I also highly recommend checking out [this] external blog entry about using John the Ripper to crack different file formats. I heavily leveraged it since it highlights things like to crack .odt files you need to use lbreoffice2john.
- list16-FL_kdIZUGpI.zip
- zip2john list16-FL_kdIZUGpI.zip >> hash_files/encrypted_file_hashes.hash
- list17-TOWMINTP.hashes.gpg
- gpg2john list17-TOWMINTP.hashes.gpg >> hash_files/encrypted_file_hashes.hash
- list18-Thursday17January2021.odt
- libreoffice2john.py list18-Thursday17January2021.odt >> hash_files/encrypted_file_hashes.hash
- list19-paidanextra500000.zip
- zip2john cmiyc-2022_list19-paidanextra500000.zip >> hash_files/encrypted_file_hashes.hash
- list20-Authoritiesappeartohaveuncoveredavastnefariousconspiracy.7z
- 7z2john.pl list20-Authoritiesappeartohaveuncoveredavastnefariousconspiracy.7z >> hash_files/encrypted_file_hashes.hash
- DEFCON-Street.kdbx
- keepass2john DEFCON-Street.kdbx >> hash_files/encrypted_file_hashes.hash
- rar.sdrawkcab
- rar2john rar.sdrawkcab >> hash_files/encrypted_file_hashes.hash
- 1991whattimeisit.tgz
- Trick challenge here! You can unzip/untar this with normal commands. Aka:
- gunzip 1991whattimeisit.tgz
- tar -xvf 19whattimeisit.tar
- The real challenge is to decrypt a gocrypt message which isn't directly supported by either John the Ripper or Hashcat.
- I'm going to skip this challenge for now. I have vague memories of downloading a gocrypt command line utility and writing a quick script to pass password into it from an external file. But since I'm focusing on the JupyterLab Framework, that yak shaving task is out of scope of this writeup.
- list24-ThisYearsWorst.pdf
- pdf2john.pl list24-ThisYearsWorst.pdf >> hash_files/encrypted_file_hashes.hash
Cracking the Encrypted File Containers (Part 2: JtR Cracking):
While I could certainly load these hashes into the JupyterLab Framework ... I don't see a lot of value doing so as there isn't a lot of "analysis" to do on them. Perhaps if/when I add the ability to keep track of targeted attacks, wordlists, and mangling rules run against a hash then it will make sense, but for now let's just crack these hashes so we can get access to the larger hash lists which we will be able to leverage the current JupyterLab Framework against. Below I'm going to list the JtR command I used (including mode) to crack the password as well as the plaintext. To help with spoilers, I'm setting the background of the plaintext to be black, but to read it you can just highlight the text and copy/paste it somewhere else.
- list16-FL_kdIZUGpI.zip
- john --pot=../pot_files/cmiyc2020_john.pot --format=pkzip encrypted_file_hashes.hash
- Note: As I said, the street file passwords are pretty easy to guess...
- Hackers
- list17-TOWMINTP.hashes.gpg
- john --pot=../pot_files/cmiyc2020_john.pot --format=gpg --wordlist=../wordlists/hacker_movies.txt --rules=Single encrypted_file_hashes.hash
- Note: This one required a non-default attack, partially because GPG is such a slow format to make guesses against, and partially since the base word wasn't in JtR's default wordlist. Based on the other hashes I cracked I figured it'd be a Vegas themed password or from a hacker movie so I made a small wordlist based on that.
- DEFCON
- list18-Thursday17January2021.odt
- john --pot=../pot_files/cmiyc2020_john.pot --format=odf --wordlist=password.lst --rules=":c;:u" encrypted_file_hashes.hash
- Note: This was a slow enough hash that I couldn't do all the rules in Single mode in a reasonable timeframe. Also the base word wasn't in my targeted dictionary. But given the other cracked passwords I ran two rules against the default JtR dictionary on the command line (Capitalize and Uppercase). I wrote more how to specify rules on JtR's command line [here].
- Sunday
- list19-paidanextra500000.zip
- john --pot=../pot_files/cmiyc2020_john.pot --format=pkzip encrypted_file_hashes.hash
- Note: I cracked this one in the same session as list16, which is why it is nice to save all these hashes to the same hash-file
- Swordfish
- list20-Authoritiesappeartohaveuncoveredavastnefariousconspiracy.7z
- john --pot=../pot_files/cmiyc2020_john.pot --format=76 --wordlist=password.lst --rules=":c;:u" encrypted_file_hashes.hash
- Note: Same constraints and attack as I ran against list18.
- Queen
- DEFCON-Street.kdbx
- john --pot=../pot_files/cmiyc2020_john.pot --format=KeePass encrypted_file_hashes.hash
- Note: This attack froze up my laptop trying to run it under WSL, so I copied it over to my server to run which worked a lot better, with almost an instant crack. The funny part was, ((Spoiler Alert)) the "username" attack in JtR's Single mode cracked the password and not a normal dictionary attack
- Street
- rar.sdrawkcab
- john --pot=../pot_files/cmiyc2020_john.pot --format=RAR5 encrypted_file_hashes.hash
- Note: I'll admit I got thrown a bit with the format (trying --foramt=rar first) until I looked at the saved hash. Otherwise this was a simple crack with a default attack
- drowssap
- 1991whattimeisit.tgz
- Didn't try this one for this writeup
- list24-ThisYearsWorst.pdf
- john --pot=../pot_files/cmiyc2020_john.pot --format=pdf encrypted_file_hashes.hash
- Note: ((Spoiler)) Surprisingly it wasn't the username attack that got this one. The base word was in passwords.lst which is JtR's default wordlist.
- Worst
Extracting the "REAL" Hash Lists:
The next step is to decrypt/unzip/open all the files and save the hashes from them. You may laugh, but I always forget the command line options to do this, so I'm listing how I did that below for future me. I'm also listing what types of hashes were in each file. To determine the hash type I mostly relied on looking at the scoreboard that KoreLogic published [link] and matching it to the hash. If that wasn't provided though, there would be several ways to figure out the hash such as using mdxfind.
- list16-FL_kdIZUGpI.zip
- unzip list16-FL_kdIZUGpI.zip
- Contains: 2766 half-md5 hashes
- JtR Mode: Not supported
- HC Mode: 5100
- list17-TOWMINTP.hashes.gpg
- gpg -d list17-TOWMINTP.hashes.gpg > ../../hash_files/list17.txt
- Note: I needed to pipe the results to a file to save them
- Contains: 2933 raw-md5 hashes
- JtR Mode: raw-md5
- HC Mode: 0
- list18-Thursday17January2021.odt
- Open it on a Linux system using LibreOffice and paste the hashes into list18.hash
- Contains: 5456 raw-sha1 hashes
- JtR Mode: raw-sha1
- HC Mode: 100
- list19-paidanextra500000.zip
- unzip list19-paidanextra500000.zip
- Contains: 4997 raw-sha256 hashes
- JtR Mode: raw-sha256
- HC Mode: 1400
- list20-Authoritiesappeartohaveuncoveredavastnefariousconspiracy.7z
- 7z x list20-Authoritiesappeartohaveuncoveredavastnefariousconspiracy.7z
- Contains: 10004 raw-sha384 hashes
- JtR Mode: Raw-SHA384
- HC Mode: 10800
- DEFCON-Street.kdbx
- Open the file in keepassx and then paste contents in list21.hashes
- Note: There is a command line version but that became too big of a pain to figure out how to export the hashes properly
- Contains: 10812 mssql05 hashes
- JtR Mode: mssql05
- HC Mode: 132
- rar.sdrawkcab
- unrar x rar.sdrawkcab
- Contains: 4214 mysql CRAM hashes
- JtR Mode: mysqlna
- HC Mode: 11200
- list24-ThisYearsWorst.pdf
- Open in a PDF viewer and copy/paste the hashes into list24.hashes
- Contains: 2000 SSHA/nsldaps hashes
- JtR Mode: Salted-SHA1
- HC Mode: 111
Creating a Config For the JupyterLab Framework:
Now that we have tens of thousands of password hashes to crack, it's time to use the JupyterLab password cracking framework. To do this, we'll first need to load the hashes into it, and to do that we'll need to configure the config file.
The framework uses the YAML file format for its configs. That means spaces/whitespace is important, but it is also a pretty flexible file format. For our config, we'll define our JtR and hashcat potfile locations, how much the hashes are worth, and where and how to load the hashes. I'll be including # Comments as well to help explain why I'm doing what I'm doing.
---
# This defines where the potfiles are for this contest. This lets you load cracked hashes from them
# as well as keep your JtR and HC potfiles synced.
jtr_config:
main_pot_file: "./challenge_files/CMIYC2022_Street/jtr_cmiyc2022.pot"
hashcat_config:
main_pot_file: "./challenge_files/CMIYC2022_Street/hc_cmiyc2022.potfile"
# This is information on where to load the challenge files. If they have additional metadata you
# may need to write a custom function to import them, but in this case they are pure raw hash lists
# so we can use the "plain_hash" plugin to import them.
#
# This plugin requires the hash type to be specified (if not it will default to "unknown"). Typically
# I use the JtR naming format for the hash type. The "source" field is used to list a source for the
# hashes in the framework. Basically it's a note for you later when looking at the cracked hashes.
#
challenge_files:
list14:
file: "./challenge_files/CMIYC2022_Street/sample_hashes/list14-4214-BrunnersMentalPrisoner.hashes"
format: "plain_hash"
type: "mysqlna"
source: "list14-BrunnersMentalPrisoner"
list16:
file: "./challenge_files/CMIYC2022_Street/sample_hashes/list16-FL_kdIZUGpI.txt"
format: "plain_hash"
type: "half-md5"
source: "list16-FL_kdIZUGpI"
list17:
file: "./challenge_files/CMIYC2022_Street/sample_hashes/list17.txt"
format: "plain_hash"
type: "raw-md5"
source: "list17"
list18:
file: "./challenge_files/CMIYC2022_Street/sample_hashes/list18.hash"
format: "plain_hash"
type: "raw-sha1"
source: "list18"
list19:
file: "./challenge_files/CMIYC2022_Street/sample_hashes/list19-paidanextra500000.hashes"
format: "plain_hash"
type: "raw-sha256"
source: "list19-paidanextra500000"
list20:
file: "./challenge_files/CMIYC2022_Street/sample_hashes/list20-Authoritiesappeartohaveuncoveredavastnefariousconspiracy.hashes"
format: "plain_hash"
type: "raw-sha384"
source: "list20-Authoritiesappearto"
list21:
file: "./challenge_files/CMIYC2022_Street/sample_hashes/list21.hashes"
format: "plain_hash"
type: "mssql05"
source: "list21"
list24:
file: "./challenge_files/CMIYC2022_Street/sample_hashes/list24.hashes"
format: "plain_hash"
type: "ssha"
source: "list24"
# The score info is taken from the Korelogic scoreboard. This isn't necessary, but it is nice to have
# a local count of what your score should be so you can compare it to the official score to validate that
# you are submitting your cracks properly
score_info:
raw-sha384: 46
mysqlna: 17
raw-sha256: 13
mssql05: 9
raw-sha1: 5
ssha: 5
half-md5: 3
raw-md5: 1
Loading the Challenge Files into JupyterLab Framework:
This is the easy part for these hashes. The biggest challenge is setting up the config file. Once that's done you can just load it up in the current framework. At this point I should mention that I'll be eventually including the Notebook in this blog post in the example files in the framework github repo.

Once it is loaded you can run the built in tools to merge Hashcat and JtR potfiles, display cracked passwords, and calculate your expected score.

Next Steps - Cracking Some Passwords:
There's not a ton more analysis to do (besides look at the cracks). And don't worry, we'll get to that! But this is where I'm glad that I decided to go back through these old CMIYC challenges. The last contest in 2023 was very heavy in its use of metadata. So I of course focused on metadata analysis for this framework. But for this contest, there is very little metadata. The focus instead was on cracking encrypted containers and (cough, SPOILER ALERT, cough) building custom wordlists from online articles. This highlights other new capabilities that I really want to add into this framework. For example, going through logfiles, extracting the rule/dictionary that cracked a password, and then storing that data with the hash in this framework. That would be super cool! How about doing google searches on passwords for you? That would be cool too. That points to the stone-soup approach of this framework. Once we have these hashes/passwords/metadata stored in a searchable framework with a Python3 backend we can build upon this to add new capabilities.
Enough talking! Let's look at some cracks. Looking above, I managed to crack over 50% of the ssha hashes in under a minute cracking run in JtR. I wonder what those plaintexts look like. I can use the SessionMgr.print_all_plaintext(meta_fields=['source']) to display them.

You don't have to be a master password cracker to design an attack against these. That being said, going back to the score graph, they aren't worth a lot of points. Even if you cracked all 2k ssha hashes (which is totally doable) you would only get 10k points. That's a lot less than most of the other hash types. So this is a list to play around with when you don't have anything better to crack and need that serotonin hit to see cracks flash across your terminal.
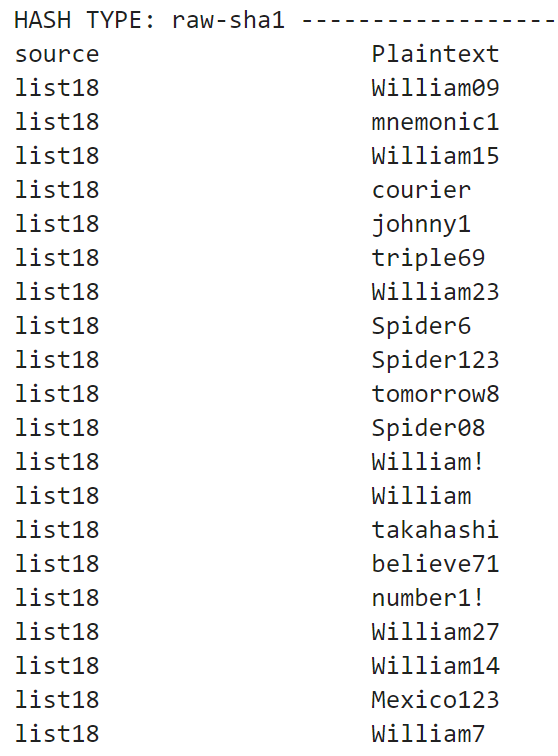
That leads us to the other hash lists. Let's check out the raw-sha1 hashes:

At least for the limited cracks so far, it looks like these plaintexts were generated using some common words that have various mangling rules applied to them. You can start to see why I want to automate pulling out dictionaries + rules from JtR and HC logfiles to make it easier to reverse engineer these rules vs. having to do it by hand.
Actually, this might be a good time to end this blog entry and work on some of those new features.... All the code is uploaded to the gitlab site and I'll upload some sample hashes as well so you can follow along. But for now I probably need to look into parsing some Hashcat log files.
如有侵权请联系:admin#unsafe.sh