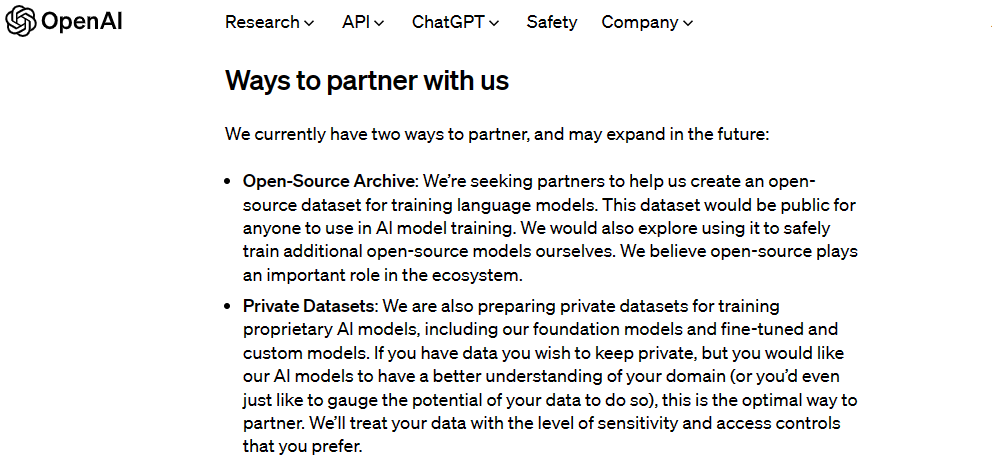
OpenAI目前正在寻求数据合作伙伴,打算与各组织合作生成用于训练人工智能模型的公共及私有数据集,旨在提高人工智能对特定领域或主题的整体理解能力。
该公司的官网博客上写道,为了让人工智能深入理解各个行业、文化和语言,它需要尽可能广泛的训练数据集。“现代人工智能技术通过理解其训练数据来学习我们世界的方方面面——人、我们的动机、互动和交流方式。”
据了解,OpenAI主要对反映人类社会的、目前在公共网络上不易获取的大规模数据集感兴趣。提交的数据类型可以是文本、图像、音频或视频格式。该公司表示,他们有能力处理几乎任何形式的数据,他们拥有世界一流的光学字符识别(OCR)技术,可以将PDF等文件数字化,以及自动语音识别(ASR)技术,可以将口头语言转录为文字。
OpenAI表示他们不寻求包含敏感或个人信息的数据集,也不寻求属于第三方的信息,并可以协助删除提交数据中的这些信息。
目前OpenAI公开了两种合作方式,一是可供任何人在AI模型训练中使用的开源数据集;二是用于训练专有AI模型的私有数据集(OpenAI表示将根据对方的要求对数据设置相应的敏感性和访问控制级别)。
该公司表示他们已经与许多组织合作,例如冰岛政府和Miðeind ehf。通过整合这部分数据集,提升了GPT-4对冰岛语的熟练程度。再如与非营利组织Free Law Project合作,将他们的法律相关文件收集纳入了人工智能训练中。
编辑:左右里
资讯来源:OpenAI官网
转载请注明出处和本文链接
NIST 网络安全标准
美国使用的一种框架,可帮助企业为防御网络犯罪做好准备。
﹀
球分享
球点赞
球在看
文章来源: https://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458528362&idx=3&sn=7ab91dd550a561e95f1176efdb34cadc&chksm=b18d1ae086fa93f6b8487ca2cd4310a92cb9ae68d44c082a32dedf2a65ac2e37e4980b6ba24b&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh