原文标题:Examining Zero-Shot Vulnerability Repair with Large Language Models
原文作者:Hammond Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, Brendan Dolan-Gavitt
发表会议:In 44th IEEE Symposium on Security and Privacy (SP 2023)
原文链接:https://arxiv.org/pdf/2112.02125.pdf
主题类型:漏洞自动化修复
笔记作者:{吴晓杰, 梅瑞}@iFLYTEK
主编:黄诚@安全学术圈
商业大语言模型(LLM)在经过大量源代码的训练后,已经被用来帮助开发人员实现一些编码任务,如在不同的编程语言之间翻译、代码理解等。在众多下游代码任务中,本文关注LLM修复代码安全漏洞的能力:即传统方法中需要安全测试人员通过运行安全工具如Fuzzer或静态分析器、尝试理解安全工具的反馈并定位问题代码、最终修复代码中安全漏洞的过程。
本文提出的根本问题是:用于代码完成(Code Completion)的“开箱即用”的LLM能否帮助开发人员修复安全漏洞?文章充分考虑LLM的三个特性即黑盒(Black-box)、现成的代码大模型(Off-the-shelf)、零样本(Zero-shot)对漏洞修复带来的影响,寻求如下4个研究问题的答案:
RQ1: 现有的“开箱即用”LLM能够生成安全的、功能正确的代码来修复安全漏洞吗? RQ2: 改变一个提示(Prompt)中的代码注释上下文数量是否会影响LLM提出修复建议的能力? RQ3: 使用LLM修复真实场景的代码安全漏洞存在哪些挑战? RQ4: LLM在生成修复代码的可靠性方面如何?
LLM技术本质上被作为一个“可扩展的序列预测模型”,即给定一个包含令牌序列的Prompt,模型预测并输出下一步“最可能”的令牌集,在代码大模型中,可以让LLM完成编写函数体、代码注释等下游任务。LLM的参数如temperature、top-p、top-k等用来调优生成代码的多样性和对齐偏好。
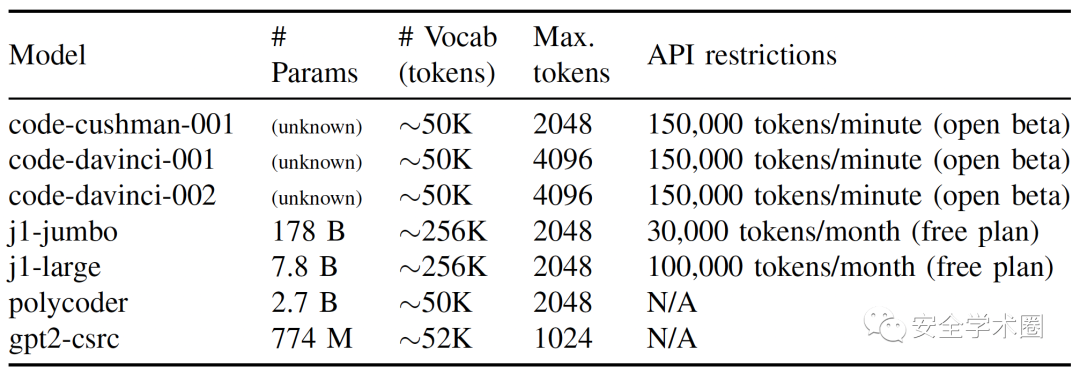
本文评估了几个现成的开箱即用LLM在代码安全漏洞修复中的表现,下表中总结了这些LLM的基本特征。其中,前3个模型为OpenAI的Codex模型的不同版本,第4、5项为AI21的Jurassic-1模型的不同版本,以上模型均采用API服务的方式调用;第6项pylycoder是在本地部署的一个预训练大模型,gpt2-csrc是采用C/C++代码数据集在本地训练的大模型。
文章设计并实现了如下图所示的LLM评估框架,首先将存在安全漏洞的原始程序输入到安全工具中测试,然后采用CodeQL来管理和分析程序源代码和漏洞信息;然后,将程序源代码、注释等信息按照预置的Prompt模板生成Prompt,并输入到待评估的LLM中,借助LLM的代码预测能力完成漏洞的修复;最后,将修复后的程序按照第一步相同的测试用例进行安全测试,验证漏洞是否修复成功,同步进行功能性验证,确保程序可以正常运行。
本分析框架在一台PC上开展,硬件环境如下:Intel i7-10750H处理器,16GB DDR4内存,英伟达RTX 2070显卡(8GB显存);软件环境如下:Ubuntu 20.04,Python 3.8,GCC 9.3.0-17和CodeQL 2.7.2。
本部分通过构建人工合成的包含漏洞的程序源代码数据集,尝试回答RQ1和RQ2两个问题,实验分为两个阶段,第一阶段是模型参数扫描,以识别LLM生成修复代码的良好“典型”参数,第二阶段面向Prompt,以确定随着“Bug上下文”信息的增加,不同的Prompt模式是否对黑盒LLM生成的修复代码质量有影响。
3.1 漏洞程序生成
本实验从CWE Top 25中选取2个漏洞作为人工合成程序的漏洞,分别是:1)CWE-787,越界写入(Out of bounds write);2)CWE-89,SQL注入。这里选择上述2个CWE的原因为:
它们都是在CWE Top 25列表中的高影响漏洞,可能造成数据丢失/泄漏或权限提升; 容易检测,判定是否存在上述2类漏洞可以直接从给定的代码中确定,而不需要任何额外的上下文; CWE-787和CWE-89表现为两个不同的抽象层次,CWE-787往往发生在“低级”语言中,如C/C++可以直接操纵内存指针,而CWE-89常发生在“高级”语言如Java或Python中,这意味着本方案可以对软件开发的两个不同层面获得LLM修复漏洞能力的评估。
为了生成大量功能独特且漏洞相似的程序,本文采用LLM生成大量存在漏洞的程序作为评估数据集,采取如下步骤:
指定与CWE-787和CWE-89相关的存在漏洞的程序作为Prompt的开头; 将Prompt输入OpenAI的Codex大模型(分别使用code-cushman-001和code-davinci-001两个版本),各生成500个代码样本; 对这些代码样本进行单元测试和基于CodeQL的分析; 将功能可用且存在漏洞的程序作为数据集,下表为生成的代码样本的统计详情,生成了功能正常且存在漏洞的代码样本分别为388(CWE-787)和23(CWE-89); 最终,在过滤了功能相似的代码样本后,共生成CWE-787和CWE-89的漏洞程序样本分别为95个和22个。
3.2 漏洞程序修复(RQ1)
这里采用与3.1节相似的生成方法,将95个CWE-787和22个CWE-89漏洞程序代码作为Prmopt,分别向code-cushman-001和code-davinci-001两个LLM查询漏洞修复代码,每个模型每次生成500个代码样本,两个漏洞分别生成了47500和11000个,下表为生成代码样本的详情,可以看到,CWE-787场景中的22034个有效程序中有2.2%被修复,而CWE-89场景的10796个有效程序中有29.6%被修复。值得注意的是,LLM即使在没有额外的上下文假设的前提下,也能够零样本(Zero-shot)生成无Bug代码,即在漏洞修复的下游任务中用于自动化漏洞修复。
此外,实验还观察到不同的大模型参数给代码修复带来的影响,如下图所示:采用较高的temperature参数的LLM对于CWE-787的修复表现更好,而对于CWE-89更差,反之亦然,因此,似乎没有单一的temperature参数可以覆盖所有情况;另一方面,总体上看参数top_p的数值越大具有表现更优秀的趋势。因此,根据Codex官方文档的建议,本文后续的实验中,temperature采用宽泛的取值*{0, 0.25, 0.50, 0.75, 1.00},而top_p取固定值1.0*,这使得后续评估的搜索空间减少80%。
3.3 Prompt工程的影响(RQ2)
本节讨论RQ2,通过增加Prompt的类型(如增加、减少注释中的上下文数量)和评估更广泛的漏洞场景范围等来测量Prompt工程对于漏洞修复的影响,实验设置详情如下:
考虑到3.2节采用LLM来生成代码样本的方法可能隐含了提示LLM生成漏洞修复代码的线索,因此本实验采用人工构建的方法,从CWE Top 25中选取了7类典型漏洞并构建存在漏洞的代码(分别为CWE-79,CWE-125,CWE-20,CWE-416,CWE-476,CWE-119,CWE-732),作为进一步开展Prompt工程评估的基础; 漏洞修复的Prompt设计:实验框架中使用多种提示词注释模版来增强每个漏洞场景的Prompt上下文信息量,由于构建漏洞修复提示词有许多可能的自然语言措词,本文通过Codex等大模型的用户指南、Github检索到的注释关键词,设计了5个Prompt模版,这些模版改变了提供给 LLM的上下文的数量,从没有提供任何信息(n.h.)到大量的注释和提示(c./c.m.),详情见下表所示。
基于上述实验设置的评估结果表明,不同的Prompt、漏洞场景(CWE)和大模型之间的表现差异很大。在某些情况下(如CWE-20),采用较少上下文信息的Prompt模版(n.h,s.1,s.2)优于采用丰富上下文信息的模版(c.和c.m),然而在一些场景中(如CWE-79和CWE-732)情况正好相反。实验结果数据见下表。
值得注意的是,对于低上下文信息的提示词模版构建的Prompt,可能无法提供足够的信息来生成成功通过功能测试的代码,也就是说,生成的补丁代码尽管通过了安全测试,但无法通过功能测试。下图为CWE-79(XSS跨站脚本漏洞)的一个代码样本的示例,其中图(a)为存在漏洞的源代码,图(b)采用n.b.模版构造的Prompt,尽管对username变量进行了过滤,修复了XSS漏洞,但由于程序返回的字符串不包含<p>标签,从而造成功能测试失败,而图(c)由于在注释中提供了足够的上下文信息即存在漏洞的源代码,因此LLM能够生成通过功能测试和安全测试的修复代码。
为了进一步了解LLM用于真实场景下的代码修复能力,本节通过开源项目中的CVE漏洞代码作为输入,评估大模型在真实软件项目中的漏洞修复的表现。这里从3个项目中收集了12个真实CVE漏洞,这些项目来自于ExtractFix数据集。下表为本实验中使用的开源项目和CVE编号列表。
本节评估的关键挑战是:由于每个LLM的令牌长度限制,以及开源项目的代码量普遍较大,无法如RQ1和RQ2评估中那样为大模型提供源代码文件中完整的上下文信息,因此需要引入代码压缩步骤,以使得Prompt符合令牌限制的要求,具体如下:
首先,根据LLM的用户指南,基于“开发人员本应知晓的”上下文,在Prompt开头包含文件的#define等信息; 其次,跳转到源代码中与漏洞相关的函数开头,将代码添加到Prompt中,直到漏洞点所在的代码行,并采用下表所列的2种Prompt模版构建Prompt; 最后,如果Prompt仍超出令牌最大长度,则截断Prompt直到符合令牌限制。
实验结果显示,12个CVE漏洞中的8个被至少一个LLM修复,即代码通过了与修复前相同的功能测试与安全测试过程。这表明,LLM在零样本状态下修复漏洞的能力与此前最先进的工作ExtractFix相媲美(后者修复率为10/12),尽管人工检查后发现一些LLM修复的代码中引入了新的Bug,但是通过Prmopt中给出的有限的上下文,这样的表现仍展现了LLM在漏洞修复任务中的前景,LLM甚至还修复一个ExtractFix也无法修复的漏洞(CVE-2018-19664)。
首先,本文评估了包含2个CWE漏洞的117个(CWE-787:95,CWE-89:22)简单合成的程序中,LLM生成了58500个可能的补丁,其中3688个成功完成了修复。然后,文章手工制作了7个包含CWE漏洞的易受攻击的程序,LLM共生成10000个可能的补丁,其中2796个成功修复(且修复了7个程序中的100%)。此外,作者还使用了12个真实存在的CVE程序样本,LLM生成了19600个补丁,其中982个补丁修复了漏洞。
总的来说,详细的Prompt能够更有效地引导大模型生成修复补丁代码,当LLM只需要生成短的局部修复代码时,它们的工作效果最好,而在需要复杂上下文的地方,它们的表现较差。此外,考虑到100%的合成和手工制作的漏洞程序都得到了令人信服的修复,本文的评估结果对LLM在修复安全漏洞时生成的代码的质量充满信心。然而,基于对真实场景(CVE程序样本)的定性分析结果表明,LLM尚不足以取代现有的人工分析和半自动华修复工具,如基于LLM的修复当前仅限于单个文件中的局部位置等限制。
不充分的功能测试。 程序修复中的一个众所周知的问题是代码的回归测试,尽管LLM修复了安全漏洞,在相同的功能测试用例和安全测试用例中都验证成功,但LLM生成的代码无法保证不会引入新的Bug,这可能需要更稳健的评估方法。 漏洞场景设计。 虽然本文基于CWE Top 25列表,试图在不同的漏洞场景中捕获不同的安全漏洞,但对各种程序设计语言和漏洞开展完整的LLM漏洞修复评估仍面临诸多挑战。 Prompt工程。 虽然本文设计若干提示词模版,但由于LLM的黑盒特性,仍无法全面判断不同Prompt对LLM漏洞修复的影响,以及可解释的根本原因。
[1] Pearce H, Tan B, Ahmad B, et al. Examining zero-shot vulnerability repair with large language models[C]//2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2023: 2339-2356.
[2] GitHub, Inc. CodeQL documentation[EB/OL]. https://codeql.github.com/docs/
Hammond Pearce, 新南威尔士大学助理教授,纽约大学访问学者,研究方向为嵌入式网络安全和网络物理系统。https://www.cyberhammond.com/
Benjamin Tan, 卡尔加里大学助理教授,曾工作于纽约大学网络安全中心,研究兴趣包括计算机系统硬件安全、基于机器学习的集成电路供应链安全研究。https://profiles.ucalgary.ca/benjamin-tan
Baleegh Ahmad, 纽约大学网络安全中心博士研究生,研究方向包括检测和修复硬件设计中的安全漏洞。https://www.baleeghahmad.com/
Ramesh Karri, 纽约大学教授,网络安全中心联席主席,研究方向为硬件网络安全,包括可信IC、处理器和网络物理系统。https://engineering.nyu.edu/faculty/ramesh-karri
Brendan Dolan-Gavitt, 纽约大学副教授,研究兴趣涉及网络安全的多个领域,包括程序分析、虚拟化安全、内存取证以及嵌入式和网络物理系统。https://engineering.nyu.edu/faculty/brendan-dolan-gavitt
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh