一. 引言
近年来,深度神经网络模型在计算机视觉识别、语音识别、自然语言处理等领域取得了巨大的成功。但是受限于较高的计算复杂度和较大的存储需求,深度模型的部署在有限资源设备上面临着诸多挑战,因此相继出现了各种模型压缩和加速技术。其中知识蒸馏是一种典型的方法,它能从一个大的教师模型中学习到一个小的学生模型,受到了工业界和学术界的广泛关注。
本文介绍一篇知识蒸馏的研究综述【1】,从知识迁移的不同角度进行介绍,包括各种类型的知识、蒸馏方案、蒸馏算法等,共分为上、下两篇,本篇为上篇,希望各位能从中受益并引发更多思考。
二. 知识
在知识蒸馏中,最重要的三个部分是知识类型、蒸馏策略和师生结构,本节重点介绍知识蒸馏中不同类别的知识。
除了最朴素的知识蒸馏使用大型深度模型的logits作为教师知识之外,中间层的激活值、神经元或特征也可以作为指导学生模型的知识,不同激活函数、神经元或样本之间的关系也包含了教师模型学习到的丰富信息,甚至教师模型的参数或层间连接也包含了一些知识。基于此,教师模型中的知识可以分为基于响应的知识、基于特征的知识和基于关系的知识三类,图1直观地展示了这三种知识。
图1 三种知识类型的展示
2.1
基于响应的知识
基于响应的知识通常是指教师模型最后一个输出层的神经响应,其主要思想是让学生模型直接模拟教师模型的最终预测。这是一种简单有效的模型压缩方法,在不同的任务和应用中得到了广泛的应用,在图像分类领域中基于响应的知识被称为soft target,是输入属于某一类的概率。基于响应的知识蒸馏损失可以表示为:
其中LKL表示散度损失。
典型的基于响应的知识蒸馏模型如图2所示,可用于不同类型的模型预测,如目标检测任务中的响应知识可能包含logits和边界框的偏移量,语义地标定位中教师模型的响应知识可能包含每个地标的热图,最近基于响应的知识也用来解决标签作为条件目标的问题。
图2 通用的基于响应的知识蒸馏
基于响应的知识通常依赖于最后一层的输出比如soft target,然而无法表示教师模型中间层的信息,尤其是非常深度的神经网络的中间层的信息是及其重要的,所以soft logits实际上是类概率分布,基于响应的知识蒸馏也被局限在监督学习。
2.2
基于特征的知识
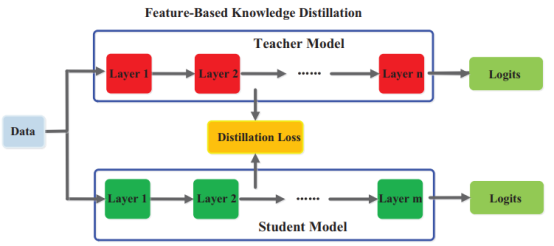
深度神经网络擅长学习抽象程度越来越高的多层次特征表示,这被称为表示学习,所以无论是最后一层的输出,还是中间层的输出,即feature maps,都可以作为监督学生模型训练的知识,特别是对于更窄更深的网络的训练。
近年来,学者们提出了很多方法,主要思想是直接匹配教师和学生模型的中间层的激活特征,如从原始的特征图中推导出“注意图”来表达知识,通过匹配特征空间中的概率分布来迁移知识,为了缩小教师和学生的表现差距提出路径约束进行提示学习,还有教师模型中间层的参数共享和基于响应的知识作为教师知识。基于特征的知识蒸馏损失可以表示为:
其中ft(x)和fs(x)分别表示教师模型和学生模型中间层的特征图,变换函数Φt(ft(x))和Φs(fs(x))通常在教师模型和学生模型的特征图不一致时应用,LF(⋅)表示匹配师生模型特征图的相似度函数。
基于一般特征的知识蒸馏模型如图3所示。尽管基于特征的知识迁移为学生模型的学习提供了有利的信息,但如何有效地从教师模型中选择提示层以及从学生模型中选择引导层,仍有待进一步研究,由于提示层和引导层的大小存在显著差异,如何正确匹配教师和学生的特征表示也需要探索。
图3 基于关系的知识
基于响应的知识和基于特征的知识都使用教师模型中特定层的输出,基于关系的知识进一步探索不同层或数据样本之间的关系。通常,基于特征映射关系的基于关系的知识蒸馏损失可表示为:
其中ft和fs分别是教师和学生模型的特征映射,Ψt (⋅)和Ψs (⋅)分别是教师和学生模型特征映射对的相似性度量函数,LR1表示师生特征图之间的相关函数。
传统的知识迁移方法往往涉及单独的知识蒸馏,教师模型的soft target直接蒸馏用于学生模型。但实际上,蒸馏出来的知识不仅包含特征信息,还包含数据样本之间的相互关系。典型的基于关系的知识蒸馏模型如图4所示。
图4 通用的基于实例关系的知识蒸馏
蒸馏后的知识可以从不同的角度进行分类,比如数据的结构化知识。虽然近年来出现了一些基于关系的知识,但如何将特征图或数据样本中的关系信息建模为知识还有待进一步研究。
三. 蒸馏方案
如图5所示,根据教师模型是否与学生模型同步更新,知识蒸馏的方案可以分为离线蒸馏、在线蒸馏和自蒸馏三大类。
图5 三种蒸馏方案的展示
3.1
离线蒸馏
离线蒸馏是最常见的,在最朴素的知识整理中,知识从教师模型迁移到学生模型的蒸馏过程包含两个阶段,首先在一组训练样本上对大型教师模型进行训练,然后进行知识迁移,也就是使用教师模型以logits或中间特征的形式提取知识来指导学生模型的训练。
离线蒸馏侧重于改进知识迁移的部分,主要优点是简单且易于实现,但是无法避免复杂的大容量教师模型和较长的训练时间的问题,此外,学生模型在很大程度上依赖于教师模型,离线蒸馏中学生模型的训练通常需要教师模型的指导,但教师和学生模型之间的能力差距始终存在。
3.2
在线蒸馏
在线蒸馏克服了离线蒸馏的局限性,特别是在没有大容量高性能教师模型的情况下,其进一步提高了学生模型的性能。在线蒸馏中的教师模型和学生模型可以同时更新,整个知识蒸馏框架是端到端可训练的。
在线蒸馏是一种高效并行计算的单向端到端的训练方案,然而现有的在线蒸馏方法通常无法解决在线环境下高性能教师模型训练的问题,因此还需要进一步探索。
3.3
自蒸馏
自蒸馏中教师模型和学生模型使用相同的网络结构,可以看作是在线蒸馏的一个特例。更直观地,离线蒸馏是指知识渊博的老师教给学生知识,在线蒸馏是指师生共同学习,自蒸馏是指学生自己学习知识,这三种蒸馏各有优缺,可以结合使用。
3.4
教师学生模型架构
在知识蒸馏中,学生模型对知识的获取和蒸馏的质量取决于教师学生模型架构。如何选择或设计合适的师生架构是一个重要而困难的问题,目前大部分工作的教师和学生模型几乎是预先设定的固定大小和结构,容易造成模型性能之间的差异。
知识蒸馏以前被用来压缩深度神经网络,通常将知识从更深更广的神经网络转移到更浅更窄的神经网络,如图6所示,学生模型通常的选择包括更浅更窄的教师模型的简化版本、保留网络结构的教师模型的量化版本、具有基本功能的小型高效网络、优化全局网络结构的小型网络和与教师模型相同的网络。
图6 教师学生模型之间的关系
大型深度神经网络和小型学生神经网络之间的容量差距会降低知识转移,所以很多研究都集中在设计师生模型的结构和师生模型之间的知识转移方案上。近年来,提出了知识蒸馏中的神经网络结构搜索思想,即在教师模型的指导下对学生模型的结构和知识迁移进行联合搜索,这将是未来的研究热点。
四. 小结
知识蒸馏系统主要由知识、蒸馏算法和师生结构组成,本文主要介绍了知识的不同类型和几种蒸馏方案,下篇会介绍典型的蒸馏算法和相关讨论,希望给从业者带来一些思考。
参考文献
[1] Gou J , Yu B , Maybank S J ,et al.Knowledge Distillation: A Survey[J]. 2020.DOI:10.1007/s11263-021-01453-z.
内容编辑:创新研究院 王萌
责任编辑:创新研究院 舒展
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
关于我们
绿盟科技研究通讯由绿盟科技创新研究院负责运营,绿盟科技创新研究院是绿盟科技的前沿技术研究部门,包括星云实验室、天枢实验室和孵化中心。团队成员由来自清华、北大、哈工大、中科院、北邮等多所重点院校的博士和硕士组成。
绿盟科技创新研究院作为“中关村科技园区海淀园博士后工作站分站”的重要培养单位之一,与清华大学进行博士后联合培养,科研成果已涵盖各类国家课题项目、国家专利、国家标准、高水平学术论文、出版专业书籍等。
我们持续探索信息安全领域的前沿学术方向,从实践出发,结合公司资源和先进技术,实现概念级的原型系统,进而交付产品线孵化产品并创造巨大的经济价值。
长按上方二维码,即可关注我
往期回顾:
加密代理篇:
加密恶意流量篇:
加密webshell篇:
开放环境机器学习篇:
流量分析篇:
机器学习部署篇:
如有侵权请联系:admin#unsafe.sh