在现有的日志库中,包括 go 1.21.0 引入的 slog 日志库,它们通常都支持对日志文件进行轮转与切割,只不过这些功能并不直接被内置,而是需要我们主动配置来启用。本文将探讨几个热门的日志库如 l 2023-11-28 20:56:37 Author: Go语言中文网(查看原文) 阅读量:39 收藏
在现有的日志库中,包括 go 1.21.0 引入的 slog 日志库,它们通常都支持对日志文件进行轮转与切割,只不过这些功能并不直接被内置,而是需要我们主动配置来启用。
本文将探讨几个热门的日志库如 logrus、zap 和官网的 slog,我将分析这些库的的关键设计元素,探讨它们是如何支持日志轮转与切割功能的配置。
准备好了吗?准备一杯你最喜欢的咖啡或茶,随着本文一探究竟吧。
★前段时间发布了一篇 Go slog 包:开启结构化日志的奇妙之旅 文章,有一位网友问我该日志库是否支持日志轮转与切割功能,此文章也算是解答他的一个疑惑。
”
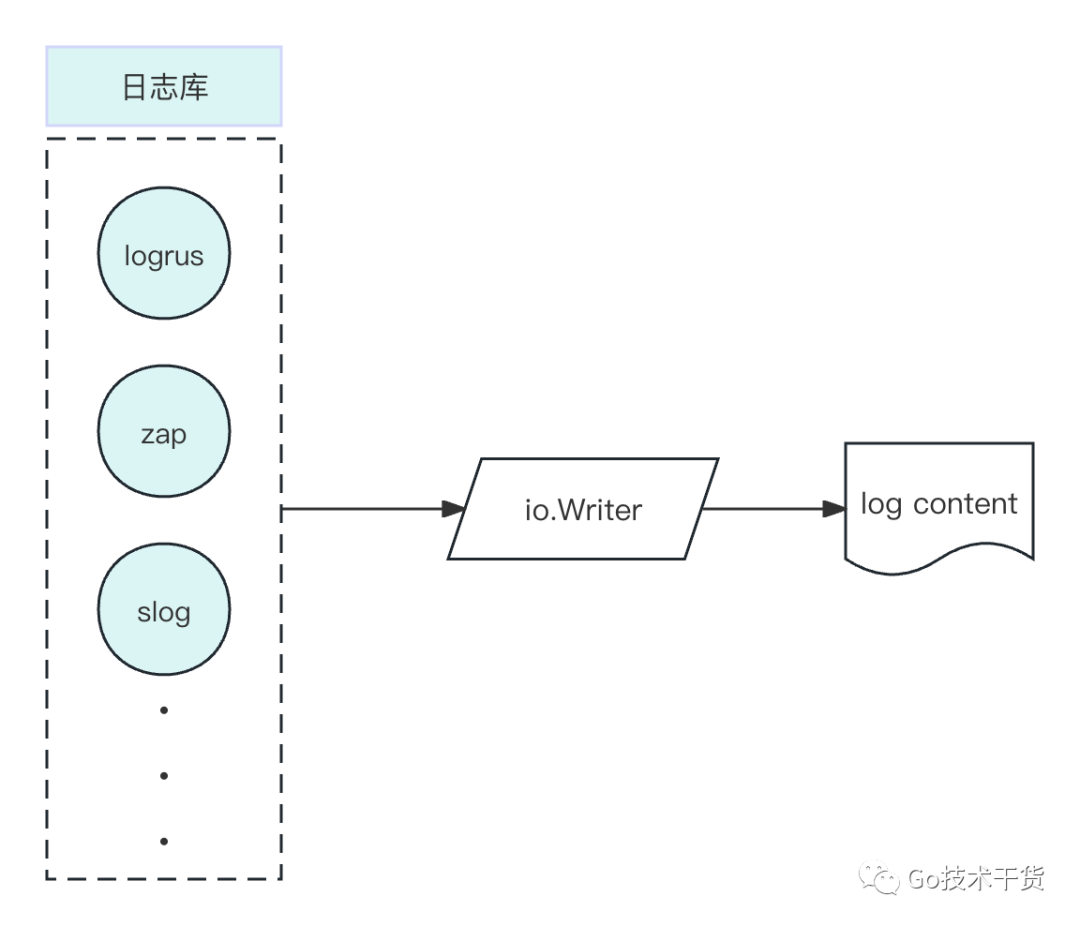
在对 logrus、zap 和 slog 这几个日志库的设计进行对比分析时,一个显著的共同点是它们都包含了 io.Writer 这个关键的属性。这一属性在日志框架设计中起着核心作用,它决定了日志输出的目标位置。
logrus 日志库
logrus 是一个功能丰富的Go语言日志库,它提供了结构化日志记录、日志级别控制等功能。
当使用 logrus 时,可以调用 logrus.New() 函数来创建 Logger 实例。通过该实例我们执行很多操作,例如自定义日志输出的位置和打印日志等。我们看看下面的代码:
logger := logrus.New()
logger.Out = os.Stdout // 标准输出
// 或者定向到文件
//out, err := os.OpenFile("file.log", os.O_CREATE|os.O_WRONLY, 0666)
//if err != nil {
// panic(err)
//}
//logger.Out = out
Logger 结构体的定义如下所示:
type Logger struct {
Out io.Writer
Hooks LevelHooks
Formatter Formatter
// 其他字段...
}
关键属性 Out,其类型为 io.Writer,这一属性用于指定日志的输出目标,无论是标准输出、文件,还是其他自定义的输出载体。
zap 日志库
zap 是一个性能极高的日志库。它提供了结构化日志记录、多级别日志控制,以及灵活的配置选项。
与 logrus 类似,zap 也允许支持通过配置来决定日志输出的位置,但实现方式略有不同。在 zap 中,日志输出是通过配置 zapcore.Core 实现的。在创建 zapcore.Core 实例时,需要指定一个 zapcore.WriteSyncer 接口实现作为参数,这个参数直接决定了日志的输出目标。要创建 zapcore.WriteSyncer 实例,通常使用 zapcore.AddSync() 函数,它接收一个类型为 io.Writer 的参数。
下面是一个使用 zap 创建日志实例的基本示例:
writer := zapcore.AddSync(os.Stdout) // 使用标准输出作为日志目标
core := zapcore.NewCore(
zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig()),
writer,
zap.InfoLevel,
)
logger := zap.New(core)
defer logger.Sync() // 刷新任何缓冲的日志条目// 使用 logger 进行日志记录
关键在于 zapcore.AddSync() 函数,该函数接收一个类型为 io.Writer 的参数,这一参数用于指定日志的输出目标,无论是标准输出、文件,还是其他自定义的输出载体。
slog 日志库
slog 是在 go 1.21.0 版本引入的一个官网日志库,它提供了结构化日志。如果想要更详细地了解 slog 日志库,自荐一篇文章 Go slog 包:开启结构化日志的奇妙之旅。
与 logrus 和 zap 类似,slog 也允许用户通过指定 io.Writer 参数来设置日志输出的目标。这一设置是在创建 slog.Handler 接口的实现时进行的。
textLogger := slog.New(slog.NewTextHandler(os.Stdout, nil))
jsonLogger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
在这两个函数中,slog.NewTextHandler 和 slog.NewJSONHandler 第一个参数的类型都是 io.Writer。
浅析总结
在对 logurs、zap 和 slog 这三个主流日志库的分析中,我们可以发现一个关键的共同点:它们在处理日志输出时均依赖于 io.Writer 接口。这些日志库通过将 io.Writer接口作为关键参数的类型,以便设置日志的输出目标。
实现机制
在浅析了 logurs、zap 和 slog 日志库的设计后,我们发现了它们的共同点。现在,让我们深入了解日志轮转与切割功能的实现机制。
为了实现 日志文件的轮转与切割,通常我们会借助第三方库,如 lumberjack,当然还有其他类似的库可供选择,这里就不一一列举了。
lumberjack 是一个专门设计用于日志轮转和切割的库,其作用可以类比于一个可插拔的组件。我们可以通过配置该组件,并将其 集成 到所选的日志库中,从而实现日志文件的轮转与切割功能。
初始化 lumberjack 组件的代码如下所示:
log := &lumberjack.Logger{
Filename: "/path/file.log", // 日志文件的位置
MaxSize: 10, // 文件最大尺寸(以MB为单位)
MaxBackups: 3, // 保留的最大旧文件数量
MaxAge: 28, // 保留旧文件的最大天数
Compress: true, // 是否压缩/归档旧文件
LocalTime: true, // 使用本地时间创建时间戳
}
在这个例子中,我们创建了一个 lumberjack.Logger 实例,并设置了以下参数:
Filename:指定日志文件的存储路径。MaxSize:日志文件达到多少MB后进行轮转。MaxBackups:最多保留多少个旧日志文件。MaxAge:旧文件保留的最长时间(天)。Compress:是否压缩旧文件(如转换为.gz)。
需要特别注意的是, lumberjack 的 Logger 结构体实现了 io.Writer 接口。这意味着所有关于日志文件的轮转与切割的核心逻辑都封装在 Write 方法中。这一实现也方便 Logger 结构体被集成到任何支持 io.Writer 参数的日志库中。
明白了这些,想必你已经知道如何实现日志轮转与切割的功能了吧。lumberjack 的 logger 结构体实现了 io.Writer 接口,因此将它传递到第三方库中,就能完成集成配置了。
实践
logrus 日志库的实现
log := &lumberjack.Logger{
Filename: "/path/file.log", // 日志文件的位置
MaxSize: 10, // 文件最大尺寸(以MB为单位)
MaxBackups: 3, // 保留的最大旧文件数量
MaxAge: 28, // 保留旧文件的最大天数
Compress: true, // 是否压缩/归档旧文件
LocalTime: true, // 使用本地时间创建时间戳
}
logger := logrus.New()
logger.Out = log
zap 日志库的实现
log := &lumberjack.Logger{
Filename: "/path/file.log", // 日志文件的位置
MaxSize: 10, // 文件最大尺寸(以MB为单位)
MaxBackups: 3, // 保留的最大旧文件数量
MaxAge: 28, // 保留旧文件的最大天数
Compress: true, // 是否压缩/归档旧文件
LocalTime: true, // 使用本地时间创建时间戳
}
writer := zapcore.AddSync(log)
core := zapcore.NewCore(
zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig()),
writer,
zap.InfoLevel,
)
logger := zap.New(core)
defer logger.Sync() // 刷新任何缓冲的日志条目
slog 日志库的实现
log := &lumberjack.Logger{
Filename: "/path/file.log", // 日志文件的位置
MaxSize: 10, // 文件最大尺寸(以MB为单位)
MaxBackups: 3, // 保留的最大旧文件数量
MaxAge: 28, // 保留旧文件的最大天数
Compress: true, // 是否压缩/归档旧文件
LocalTime: true, // 使用本地时间创建时间戳
}
textLogger := slog.New(slog.NewTextHandler(log, nil))
jsonLogger := slog.New(slog.NewJSONHandler(log, nil))
本文对三个热门的日志库 logrus、zap 和 slog 设计要素进行浅析,我们发现虽然它们在创建日志实例的细节上有所差异,但它们共同依赖于 io.Writer 接口参数来处理日志的输出。掌握如何配置 io.Writer 参数,并结合 lumberjack 库的使用,我们就可以实现日志文件的轮转与切割功能。
即使后面推出新的日志库,我们也可以通过类似的方法,快速地集成日志文件的轮转与切割功能。
推荐阅读
如有侵权请联系:admin#unsafe.sh