
This post continues a long, wonky discussion of Schnorr signature schemes and the Dilithium post-quantum signature. You may want to start with Part 1.
In the previous post I discussed the intuition behind Schnorr signatures, beginning with a high-level design rationale and ending with a concrete instantiation.
As a reminder: our discussion began with this Tweet by Chris Peikert:

Which we eventually developed into an abstract version of the Schnorr protocol that uses Chris’s “magic boxes” to realize part of its functionality:

Finally, we “filled in” the magic boxes by replacing them with real-world mathematical objects, this time built using cyclic groups over finite fields or elliptic curves. Hopefully my hand-waving convinced you that this instantiation works well enough, provided we make one critical assumption: namely, that the discrete logarithm problem is hard (i.e., solving discrete logarithms in our chosen groups is not feasible in probabilistic polynomial time.)
In the past this seemed like a pretty reasonable assumption to make, and hence cryptographers have chosen to make it all over the place. Sadly, it very likely isn’t true.
The problem here is that we already know of algorithms that can solve these discrete logarithms in (expected) polynomial time: most notably Shor’s algorithm and its variants. The reason we aren’t deploying these attacks today is that we simply don’t have the hardware to run them yet — because they require an extremely sophisticated quantum computer. Appropriate machines don’t currently exist, but they may someday. This raises an important question:
Do Schnorr signatures have any realization that makes sense in this future post-quantum world? And can we understand it?
That’s where I intend to go in the rest of this post.
Towards a post-quantum world
Cryptographers and standards agencies are not blind to the possibility that quantum computers will someday break our cryptographic primitives. In anticipation of this future, NIST has been running a public competition to identify a new set of quantum-resistant cryptographic algorithms that support both encryption and digital signing. These algorithms are designed to be executed on a classical computer today, while simultaneously resisting future attacks by the quantum computers that may come.
One of the schemes NIST has chosen for standardization is a digital signature scheme called Dilithium. Dilithium is based on assumptions drawn from the broad area of lattice-based cryptography, which contains candidate “hard” problems that have (so far) resisted both classical and quantum attacks.
The obvious way to approach the Dilithium scheme is to first spend some time on the exact nature of lattices and then discuss what these “hard problems” are (for the moment). But we’re not going to do any of that. Instead, I find that sometimes it’s helpful to just dive straight into a scheme and see what we can learn from first contact with it.
As with any signature scheme, Dilithium consists of three algorithms, one for generating keys, one for signing, and one for signature verification. We can see an overview of each of these algorithms — minus many specific details and subroutine definitions — at the very beginning of the Dilithium specification. Here’s what it looks like:
As you can see, I’ve added some arrows pointing to important aspects of the algorithm description above. Hopefully from these highlights (and given the title of this series of post!) you should have some idea of the point I’m trying to make here. To lay things out more clearly: even without understanding every detail of this scheme, you should notice that it looks an awful lot like a standard Schnorr signature.
Let’s see if we can use this understanding to reconstruct how Dilithium works.
Dilithium from first principles
Our first stop on the road to understanding Dilithium will begin with Chris Peikert’s “magic box” explanation of Schnorr signatures. Recall that his approach has five steps:
- Signer picks a slope. The Signer picks a random slope of a line, and inserts it into a “magic box” (i.e., a one-way function) to produce the public key.
- Signer picks a y-intercept. To conduct the interactive Identification Protocol (in this case flattened into a signature via Fiat-Shamir), the Signer picks a random “y-intercept” for the line, and inserts that into a second magic box.
- Verifier challenges on some x-coordinate. In the interactive protocol, the Verifier challenges the Prover (resp. signer) to evaluate the line at some randomly-chosen x-coordinate. Alternatively: in the Fiat-Shamir realization, the Signer uses the Fiat-Shamir heuristic to pick this challenge herself, by hashing her magic boxes together with some message.
- Signer evaluates the line. The Signer now evaluates her line at the given coordinate, and outputs the resulting point.
(The signature thus comprises one “magic box” and one “point.”) - Verifier tests that the response is on the line. The Verifier uses the magic boxes to test that the given point is on the line.
If Dilithium really is a Schnorr protocol, we should be able to identify each of these stages within the Dilithium signature specification. Let’s see what we can do.

Step 1: putting a “slope” into a magic box to form the public key. Let’s take a closer look at the Dilithium key generation subroutine:

A quick observation about this scheme is that it samples not one, but two secret values, s1 and s2, both of which end up in the secret key. (We can also note that these secret values are vectors rather than simple field elements, but recall that for the moment our goal is to avoid getting hung up on these details.) If we assume Dilithium is a Schnorr-like protocol, we can surmise that one of these values will be our secret “slope.”
But which one?
One approach to answering this question is to go searching for some kind of “magic box” within the signer’s public key. Here’s what that public key looks like:
pk := (A, t)
The matrix A is sampled randomly. Although the precise details of that process are not given in the high-level spec, we can reasonably observe that A is not based on s1 or s2. The second value in the public key, on the other hand, is constructed by combining A with both of the secret values:
t = As1 + s2.
Hence we can reasonably guess that the pair (A, t) together form the first of our magic boxes. Unfortunately, this doesn’t really answer our earlier question: we still don’t know which of the two secret values will serve as the “slope” for the Schnorr “linear equation.”
The obvious way to solve this problem is to skip forward to the signing routine, to see if we can find a calculation that resembles that equation. Sure enough, at line (10) we find:

Here only s1 is referenced, which strongly indicates that this will take the place of our “slope.”
So roughly speaking, we can view key generation as generating a “magic box” for the secret “slope” value s1. Indeed, if our public key had the form (A, t := As1), this would be extremely reminiscent of the discrete logarithm realization from the previous post, where we computed (g, gm mod p) for some random “generator” g. The messy and obvious question we must ask, therefore, is: what purpose is s2 serving here?

We won’t answer this question just now. For the moment I’m going to leave this as the “Chekhov’s gun” of this story.

Step 2: putting a “y-intercept” into a second magic box. If Dilithium follows the Schnorr paradigm, signing a new message should require the selection of a fresh random “y-intercept” value. This ensures that the signer is using a different line each time she runs the protocol. If Peggy were to omit this step, she’d be continuously producing “points” on a single “line” — which would very quickly allow any party to recover her secret slope.
A quick glance at the signing algorithm reveals a good candidate for this value. Conveniently, it’s a vector named y:

This vector y is subsequently fed into something that looks quite similar to the “magic box” we saw back in key generation. Here again we see our matrix A, which is then multiplied to produce Ay at line (8). But from this point the story proceeds differently: rather than adding a second vector to this product, as in the key generation routine, the value Ay is instead fed into a mysterious subroutine:
w1 := HighBits(Ay, 2𝛄2)
Although this looks slightly different from the magic box we built during key generation, I’m still going to go out on a limb and guess that w1 will still comprise our second “magic box” for y, and that this will be sent to the Verifier.
Unfortunately, this elegant explanation still leaves us with three “mysteries”, which we must attempt to resolve before going forward.
Mystery #1: if w1 is the “box”, why doesn’t the Sign algorithm output it?
If w1 is our “magic box,” then we should expect to see it output as part of the signature. And yet we don’t see this at all. Instead the Sign algorithm feeds w1 into a hash function H to produce a digest c. The pair (c, z) is actually what gets output as our signature.
Fortunately this mystery, at least, has a simple explanation.
What is happening in this routine is that we are using Fiat-Shamir to turn an interactive Identification Protocol into a non-interactive signature. And if you recall the previous post, you may remember that there are two different ways to realize Fiat-Shamir. In all cases the signer will first hash the magic box(es) to obtain a challenge. From here, things can proceed differently.
- In the first approach, the Signer would output the “magic box” (here w1) as part of the signature. The Verifier will hash the public key and “box” to obtain the challenge, and use the challenge (plus magic boxes) to verify the response/point z given by the Signer.
- In the alternative approach, the signer will only output the hash (digest) of the box (here c) along with enough material to reconstruct the magic box w1 during verification. The Verifier will then reconstruct w1 from the information it was given, then hash to see if what it reconstructed produces the digest c included in the signature.
These two approaches are both roughly equivalent for security, but they have different implications for efficiency. If the value w1 is much larger than c, it generally makes sense to employ the second approach, since you’ll get smaller signatures.
A quick glance at the Verify algorithm confirms that Dilithium has definitely chosen to go with the second approach. Here we see that the Verifier uses the public key (A, t) as well as z from the signature to reconstruct a guess for the “magic box” w1. She then hashes this value to see if the result is equal to c:

So that answers the easy question. Now let’s tackle the harder one:
Mystery #2: what the heck does the function HighBits() do in these algorithms?

Based solely on the name (because the specification is too verbose), we can hazard a simple guess: HighBits outputs only the high-order bits of the elements of Ay.
(With a whole lot more verbiage, the detailed description at right confirms this explanation.)
So that answers the “what.” The real question is: why?
One possible explanation is that throwing away some bits of Ay will make the “magic box” w1 shorter, which would lead to smaller signatures. But as we discussed above, w1 is not sent as part of the signature. Instead, the Sign algorithm hashes w1 and sends only the resulting digest c, which is always pretty short. Compressing w1 is unlikely to give any serious performance benefit, except for making a fast hash function marginally faster to compute.
To understand the purpose of HighBits() we need to look to a different explanation.
Our biggest clue in doing this is that HighBits gets called not once, but twice: first it is called in the Sign algorithm, and then it is called a second time in Verify. A possible benefit of using HighBits() here would be apparent if, perhaps, we thought the input to these distinct invocations might be very similar but not exactly the same. If this were to occur — i.e., if there was some small “error” in one of the two invocations — then throwing away the insignificant bits might allow us to obtain the same final result in both places.
Let’s provisionally speculate that this is going to be important further down the line.
Mystery #3: why does the Sign algorithm have a weird “quality check” loop inside of it?
A final‚ and thus far unexplained, aspect of the Sign algorithm is that it does not simply output the signature after computing it. Instead it first performs a pair of “quality checks” on the result — and in some cases will throw away a generated signature and re-generate the whole thing from scratch, i.e., sampling a new random y and then repeating all the steps:

This is another bizarre element of the scheme that sure seems like it might be important! But let’s move on.
Steps 3 & 4: Victor picks a random point to evaluate on, and Peggy evaluates the line using her secret equation. As noted above, we already know that our signer will compute a Fiat-Shamir hash c and then use it to evaluate something that, at least looks like a Schnorr linear equation (although in this case it involves addition and multiplication of vectors.)

Assuming the result passes the “quality checks” mentioned above, the output of the signing algorithm is this value z as well as the hash digest c.
Step 5: use the “magic boxes” to verify the signature is valid. In the most traditional (“standard Fiat-Shamir variant”) realization of a Schnorr protocol, the verification routine would first hash the magic boxes together with the message to re-compute c. Then we would use the magic boxes (t and w1) to somehow “test” whether the signer’s response z satisfies the Schnorr equation.
As noted above, Dilithium uses Fiat-Shamir in an alternative mode. Here the signature comprises (z, c), and verification will therefore require us re-compute the “magic box” w1 and hash it to see if the result matches c. Indeed, we’ve already seen from the Verify routine that this is exactly what happens:
All that remains now is to mindlessly slog through the arithmetic to see if any of it makes sense. Recall that in the signing routine, we computed w1 as:
w1 := HighBits(Ay, 2𝛄2)
In the Verify routine we re-compute the box (here labeled w’1) as follows. Note that I’ve taken the liberty of substituting in the definitions of z and t and then simplifying:
w’1 := HighBits(Az – ct, 2𝛄2)
= HighBits(A(y + cs1) – c(As1 + s2), 2𝛄2)
= HighBits(Ay – cs2, 2𝛄2)
As you can see, these two calculations — that is, the inputs that are passed into the HighBits routine in both places — do not produce precisely the same result. In the signing routine the input is Ay, and in the verification routine it is Ay – cs2. These are not the same! And yet, for verification to work, the output of HighBits() must be equal in both cases.
If you missed some extensive foreshadowing, then you’ll be astounded to learn that this new problem is triggered by the presence of our mystery vector s2 inside of the public key. You’ll recall that I asked you to ignore s2, but reminded you it would trip us up later.

The presence of this weird extra s2 term helps to explains some of the “mysteries” we encountered within the Sign routine. The most notable of these is the purpose of HighBits(). Concretely: by truncating away the low-order bits of its input, this routine must “throw away” the bits that are influenced by the ugly additional term “cs2” that shows up in the Verify equation. This trim ensures that signature verification works correctly, even in the presence of the weird junk vector s2 left over from our public key.
Of course this just leaves us with some new mysteries! Like, for example:
Mystery #4: why is the weird junk vector s2 inside of our public key in the first place!?
We’ll return to this one!
Mystery #5: how can we be sure that the weird additive junk “cs2” will always be filtered out by the HighBits() subroutine during signature verification?
We’ve hypothesized that HighBits() is sufficient to “filter out” the extra additive term cs2, which should ensure that the two invocations within Sign and Verify will each produce the same result (w1 and w’1 respectively.) If this is true, the re-computed hash c will match between the two routines and signature verification will succeed.
Without poking into the exact nature and distribution of these terms, we can infer that the term cs2 must be “insignificant enough” in practice that it will be entirely removed by HighBits during verification — at least most of the time. But how do we know that this will always be the case?
For example, we could imagine a situation where most of the time HighBits clears away the junk. And yet every now and again the term cs2 is just large enough that the additive term will “carry” into the more significant bits. In this instance we would discover, to our chagrin, that:
HighBits(Ay, 2𝛄) ≠ HighBits(Ay – cs2, 2𝛄)
And thus even honestly-generated signatures would not verify.

The good news here is that — provided this event does not occur too frequently — we can mostly avoid this problem. That’s because the signer can examine each signature before it outputs a result, i.e., it can run a kind of “quality check” on the result to see if a generated signature will verify correctly, and discard it if it does not. And indeed, this explanation partially resolves the mystery of the “quality checks” we encountered during signature generation — though, importantly, it explains only one of the two checks!
And that leads us to our final mystery:
Mystery #6: what is the second “quality check” there for?

We’ve explained the first of our two quality checks as an attempt to make the scheme verify. So what does this other one do?
Hopefully we’ll figure that out later down the line.
Leaving aside a few unanswered mysteries, we’ve now come to the end of the purely mechanical explanation of Dilithium signatures. Everything else requires us to look a bit more closely at how the machinery works.
What are these magic boxes?

As we discussed in the previous post, the best real-life analog of a “magic box” is some kind of one-way function that has useful algebraic properties. In practice, we obtain these functions by identifying a “hard” mathematical problem — more precisely, a problem that requires infeasible time and resource-requirements for computers to solve — and then figuring out how to use it in our schemes.
Dilithium is based on a relatively new mathematical problem called Module Learning with Errors (MLWE). This problem sits at the intersection of two different subfields: lattice–based cryptography and code-based cryptography. For a proper overview of LWE (of which MLWE is a variant), I strongly recommend you read this survey by Regev. Here in this post, my goal is to give you a vastly more superficial explanation: one that is just sufficient to help explain some of the residual “mysteries” we noticed above.
The LWE problem assumes that we are given the approximate solutions of a series of linear equations over some ring. Our goal is to recover a secret vector s given a set of non-secret coefficients. To illustrate this problem, Regev gives the following toy example:

Note that if the solutions on the right-hand side were exact, then solving for the values s = (s1, …, s4) could be accomplished using standard linear algebra. What makes this problem challenging is that the solutions are only approximate. More concretely, this means that the solutions we are given on the right side contain a small amount of additive “error” (i.e., noise.)
Note that the error terms here are small: in this example, each equation could be accurate within a range of -1 to +1. Nonetheless, the addition of this tiny non-uniform error makes solving these problems vastly harder to both classical and quantum computers. Most critically, these error terms are essential to the conjectured “hardness” of this function — they cannot be wished away or eliminated.
A second important fact is that the secret coefficients (the ones that make up s) are also small and are not drawn uniformly from the ring. In fact, if the secret terms and error were drawn uniformly from the ring, this would make solving the system of equations trivially easy — there would potentially be many possible solutions to the system of equations. Hence it is quite important to the hardness of the (M)LWE function that these values be “small.” You’ll have to take my word for this, or else read deeper into the Regev survey to understand the detailed reasoning, but this will be very important to us going forward.
Of course, big systems of equations are tough to look at. A more concise way to represent the above is to describe the non-secret (random) coefficients as a matrix A, and then — using s1 to represent our secret — the exact solution to these equations can be represented by the product As1. If we express those additive “error terms” as a second vector s2, the entire LWE “function” can thus be succinctly expressed as:
A, t = As1 + s2
For this function to be a good magic box, we require that given (A, t), it is hard to recover (at least) s1.1 You’ll note that — ignoring many of the nitty-gritty details, including the nature of the ring we’re using and the distribution of s1 and s2 — this is essentially the structure of the public key from the Dilithium specification.
So what should we learn from this?
A clear implication is that the annoying error vector s2 is key to the security of the “magic box” used in Dilithium. If we did not include this term, then an attacker might be able to recover s1 from Dilithium’s public key, and thus could easily forge signatures. At the same time, we can observe that this error vector s2 will be “small” in terms of the magnitude of its elements, which helps explain why we can so easily dispense with its effects by simply trimming away the low-order bits of the product Ay (resp. Ay – cs2) inside of the signing and verification functions.
Phew.
A reasonable person might be satisfied at this point that Dilithium is essentially a variant of Schnorr, albeit one that uses very different ingredients from the classical Schnorr signatures. After all, the public key is just a “magic box” embedding the secret value s1, with some error thrown in to make it irreversible. The signature embeds a weird magic box computed on a value y as well as a “Schnorr-like” vector z = y + cs1 on some challenge point c, which can be approximately “tested” using the various boxes. What more is there to say?
But there remains one last critical mystery here, one that we haven’t addressed. And that mystery lives right here, in the form of a second “quality check” that we still have not explained:

To figure out why we need this second quality check, we’ll need to dive just a little bit deeper into what these values actually represent.
Is Dilithium secure?
If you recall the previous post, we proposed three different properties that a Schnorr-like Identification Protocol should satisfy. Specifically, we wanted to ensure that our protocols are (1) correct, (2) sound, and (3) private — i.e., they not leak their secret key to any Verifier who sees a few transcripts.
Correctness. This simply means that honestly-generated signatures will verify. I hope at this point that we’ve successfully convinced ourselves that Dilithium will likely achieve this goal, provided we get out of the “quality check” loop. (Since producing a valid signature may require multiple runs through the “quality check” loop, we do need to have some idea of how likely a “bad” signature is — the Dilithium authors perform this analysis and claim that 4-7 iterations is sufficient in most cases.)
Soundness. This property requires that we consider the probability that a dishonest signer (one who does not know the secret key) can produce a valid signature. This hangs on two principles: (1) the non-reversibility of the public key “magic box”, or more concretely: the assumed one-wayness of the MLWE function. It also requires (2) a more involved argument about the signer’s ability to compute responses.
In this post we will choose to take the actual hardness of MLWE for granted (i.e., we are perfectly happy to make analyzing that function into some other cryptographer’s problem!) Hence we need only consider the second part of the argument.
Specifically: let’s consider Dilithium as a pure interactive identification protocol. Let us imagine that a prover can satisfy the protocol when handed some random challenge c by the Verifier, and they can do this with high probability for many different possible values of c. If we follow the logic here, this would seem to intuitively imply that such a prover can therefore pick a value y, and then compute a response z for multiple possible c values that they may be handed. Concretely we can imagine that such a prover could produce a few values of the form:
zi = y + ci s1
If a prover can compute at least two such values (all using the same value of y, but different values of c), then presumably she could then use the values to derive s1 itself — simply by subtracting and solving for s1. What we are saying here, very informally, is that any prover who has the knowledge to successfully run the protocol this way is equivalent (up to a point) to a prover who knows the secret key. Although we will not dwell on the complete argument or the arithmetic, this does not seem like an unreasonable argument to make for Dilithium.2
Privacy (or “zero knowledge”.) The most challenging part of the original Schnorr proof was the final argument, namely the one that holds that learning a protocol transcript (or signature) will not reveal the secret key. This privacy, or “zero-knowledge” argument, is one of the most important things we addressed in the previous post.
We can found this argument on the following claim: any number of signatures (or interactive protocol) transcripts, by themselves, do not leak any useful information that can be used by an attacker to learn about the secret key. In order to make this argument successfully for Schnorr, we came at it in a particularly bizarre way: namely, we argued that this had to be true, since any random stranger can produce a correctly-distributed Schnorr transcript — whether or not they know the secret key.
For the traditional Schnorr protocol we pointed out that it is possible to manufacture a “fake” transcript by (1) selecting a random challenge and response, and then (2) “manufacturing” a new magic box to contain a new (to us unknown!) y-intercept for the line.
Translating this approach to the interactive version of the Dilithium protocol, this would require us to first sample the challenge c, then sample the response z from its appropriate distribution. We would then place z into a fresh magic box (“Az”), and compute something like this (here boxes represent MLWE functions):

Given the calculation above, we can use the HighBits() function to compute w1 given the “boxed” version of y.3
The main question we would have to ask now is: is this simulated transcript statistically identical to the real transcript that would be produced by a legitimate signer? And here we run into a problem that has not been exposed throughout this post, mostly because we’ve been ignoring all of the details.
The map is not the territory!
Up to this point we’ve mostly been ignoring what’s “inside” of each of the various vectors and matrices (y, z, A and so on.) This has allowed us to make good progress, and ignoring the details was acceptable for a high-level explanation. Unfortunately when we talk about security, these details really matter.
I will make this as quick and painless as I possibly can.
In Dilithium, all elements in these arrays and vectors consist of polynomials in the ring ![R_q = {\mathbb Z}_q[X]/(X^n+1)](https://s0.wp.com/latex.php?latex=R_q+%3D+%7B%5Cmathbb+Z%7D_q%5BX%5D%2F%28X%5En%2B1%29&bg=ffffff&fg=000000&s=0&c=20201002)
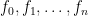
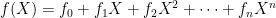
(For an engineering-oriented overview of how to work with these elements, see this post by Filippo Valsorda. Although Filippo is describing Kyber, which uses a different q, the arithmetic is similar.)
What’s important in Dilithium is how all of our various random matrices and vectors are sampled. We will note first that the matrix A consists of polynomials whose coefficients are sampled uniformly from {0, .., q-1}. However, the remaining vectors such as s1, s2 and y comprise coefficients that are not chosen this way, because the requirements of the MLWE function dictate that they cannot be sampled uniformly. And this will be critical to understanding the security arguments.
Let’s take a look back at the key generation and signing routines:
Notice the small subscripts used in generating y and both s1, s2. These indicate that the coefficients in these vectors are restricted to a subset of possible values, those less than some chosen parameter. In the case of the vectors s1, s2 this is an integer η that is based on study of the MLWE problem. For the vector y the limit is based on a separate scheme parameter ɣ1, which is also based on the MLWE problem (and some related complexity assumptions.)
At this point I may as well reveal one further detail: our hash function H does not output something as simple as a scalar or a uniform element of the ring. Instead it outputs a “hamming ball” coefficient vector that comprises mostly 0 bits, as well as exactly r bits that contain either +1 or -1. (Dilithium recommends r=60.) This hash will be multiplied by s1 when computing z.
Once you realize that Dilithium’s s1, y and c are not uniform, as they were in the original Schnorr scheme, then this has some implications for the security of the response value z := y + cs1 that the signer outputs.
Consider what would happen if the signer did not add the term y to this equation, i.e., it simply output the product cs1 directly. This seems obviously bad: it this would reveal information about the secret key s1, which would imply a leak of at least some bits of the secret key (given a few signatures.) Such a scheme should obviously not be simulatable, since we would not be able to simulate it without knowing the secret key. The addition of the term y is critical to the real-world security of the scheme, since it protects the secrecy of the secret key by “blinding it.”
(Or, if you preferred the geometric security intuition from the previous post: the signer chooses a fresh “y-intercept” each time she evaluates the protocol, because this ensures that the Verifier will not receive multiple points on the same line and thus be able to zero in on the slope value. In classical Schnorr this y-intercept is sampled uniformly from a field, so it perfectly hides the slope. Here we are weakening the logic, since both the slope and y-intercept are drawn from reduced [but non-identical] distributions!)
The problem is that in Dilithium the term y is not sampled uniformly: its coefficients are relatively small. This means that we can’t guarantee that z := y + cs1 will perfectly hide the coefficients of cs1 and hence the secret key. This is a very real-world problem, not just something that shows up in the security proof! The degree of “protection” we get is going to be related to the relative magnitude of the coefficients of cs1 and y. If the range of the coefficients of y is sufficiently large compared to the coefficients of cs1, then the secret key may be protected — but other times when the coefficients of cs1 are unusually large, they may “poke out”, like a pea poking through a too-thin mattress into a princess’s back.

The good news is that we can avoid these bad outcomes by carefully selecting the range of the y values so that they are large enough to statistically “cover” the coefficients of cs1, and by testing the resulting z vector to ensure it never contains any particularly large coefficients that might represent the coefficients of cs1 “poking through.”
Concretely, note that each coefficient of s1 was chosen to be less than η, and there are at most r non-zero (+1, -1) bits set in the hash vector c. Hence the direct product cs1 will have be a vector where all coefficients are of size at most β ≤ r*η. The coefficients of y, by construction, are all at most ɣ1. The test Dilithium uses is to reject a signature if any coefficient of the result z is greater than the difference of these values, ɣ1 – β. Which is precisely what we see in the second “quality check” of the signing algorithm:
With this test in the real protocol, the privacy (zero-knowledge) argument for the Identification Protocol is now satisfied. It is always the case that as long as the vector z is chosen to be within the given ranges, the distribution of our simulated transcripts will be identical to that of the real protocol. (A more formal argument is given in Appendix B of the spec, or see this paper that introduced the ideas.)
Conclusion… plus everything I left out
First of all, if you’re still reading this: congratulations. You should probably win a prize of some sort.
This has been a long post! And even with all this detail, we haven’t managed to cover some of the more useful details, which include a number of clever efficiency optimizations that reduce the size of the public key and make the algorithms more efficient. I have also left out the “tight” security reduction that rely on some weird extra additional complexity assumptions, because these assumptions are nuts. This stuff is all described well in the main spec above, if you want the details.
But more broadly: what was the point of all this?
My goal in writing this post was to convince you that Dilithium is “easy” to understand — after all, it’s just a Schnorr signature built using alternative ingredients, like a loaf of bread made with almond flour rather than with wheat. There’s nothing really scary about PQC signatures or lattices, if you’re willing to understand a few simple principles.
And to some extent I feel like I succeeded at that.
To a much greater extent, however, I feel like I convinced myself of just the opposite. Specifically, writing about Dilithium has made me aware of just how precise and finicky these post-quantum schemes are, how important the details are, particularly to the simpler old discrete logarithm setting. Maybe this will improve with time and training: as we all get more familiar using these new tools, we’ll get better at specifying the the building blocks in a clear, modular way and won’t have to get so deep into various details each time we design a new protocol. Or maybe that won’t happen, and these schemes are just going to be fundamentally a bit less friendly to protocol designers than the tools we’ve used in the past.
In either case, I’m hoping that a generation of younger and more flexible cryptographers will deal with that problem when it comes.
Notes:
- In practice, the LWE assumption is actually slightly stronger than this. It states that the pair (A, t = As1 + s2) is indistinguishable from a pair (A, u) where u is sampled uniformly — i.e., no efficient algorithm can guess the difference with more than a negligible advantage over random guessing. Since these distributions are quite different, however, this indistinguishability must imply one-wayness of the underlying function.
- As mentioned in a footnote to the previous post, this can actually be done by “rewinding” a prover/signer. The idea in the security proof is that if there exists an adversary (a program) that can forge the interactive protocol with reasonable probability, then we can run it up until it has output y. Then we can run it forward on a first challenge c1 to obtain z1. Finally, we can “rewind” the prover by running it on the same inputs/random coins until it outputs y again, but this time we can challenge it on a different value c2 to obtain z2. And at this point we can calculate s1 from the pair of responses.
- This argument applies to the Dilithium Identification Protocol, which is a thing that doesn’t really exist (except for implicitly.) In that protocol a “transcript” consists of the triple (w1, c, z). Since that protocol is interactive, there’s no problem with being able to fake a transcript — the protocol only has soundness if you run it interactively. Notice that for Dilithium signatures, things are different; you should not be able to “forge” a Dilithium signature under normal conditions. This unforgeability is enforced by the fact that c is the output of a hash function H and this will be checked during verification, and so you can’t just pick c arbitrarily. The zero-knowledge argument still holds, but it requires a more insane argument that has to do with the “model” we use where in the specific context of the security proof we can “program” (tamper with) the hash function H.