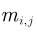
由中国通信学会数据安全委员会指导,奇安信集团、清华大学网络研究院、北京市大数据中心、蚂蚁集团、腾讯安全大数据实验室、Coremail广东盈世、赛尔网络主办的DataCon大数据安全分析竞赛最终排名已揭晓。
清华大学TrickorTech战队、武汉大学N0nE429战队、中国科学院信息工程研究所404NOTFOUND战队、中国科学院信息工程研究所Hematopoiesisbshjdkvhbj战队、社会联合跃哥我真不会啊战队分别获得AI安全赛道、软件安全赛道、邮件安全赛道、互联网威胁溯源赛道、漏洞分析赛道冠军。本期TrickorTech战队将为大家分享AI安全赛道解题思路。
![]()
如今,快速崛起的人工智能(AI)和大型模型技术已经在医疗、金融、自动驾驶等至关重要的领域广泛应用,然而,这个时代也随之带来了严重的安全挑战。其中最突出的问题之一是后门攻击,一种隐蔽而危险的威胁方式,攻击者巧妙地将精心设计的恶意样本混入AI训练数据中,目的是在未来某种特定条件下激活并危害AI系统的安全性与完整性。目前,对于后门攻击的检测和防御方法尚未达到成熟水平,而早期的防御方法很难适应现代AI学习环境,与此同时,后门攻击技术的不断演进也增加了检测和清除的难度。此外,社会对AI系统的安全性和可信度提出了更高的期望,人们迫切需要能够信赖的AI系统来保护隐私、维护数据安全以及维护公共利益。正因如此,为了迎接这个严峻的挑战,组织一场后门攻击比赛显得尤为重要。这类比赛将鼓励技术创新,推动更强大的后门攻击检测和清除技术的研发,以提升AI系统的安全性水平,保障个人隐私和数据安全,并满足社会对AI系统可信度的急迫需求。通过这场比赛,我们有望聚焦于AI系统的安全性问题,激励合作与知识分享,为构建未来更加安全和可靠的AI系统提供强大的支持。这不仅是技术创新的机遇,也是社会安全的责任。参赛者需要设计算法构建一个后门检测器,该检测器能够判断给定的神经网络模型中是否存在后门,并给出对应的攻击目标标签和后门触发器。我们为您提供了一个包含标签(后门、干净)的神经网络模型数据集,用于构建后门检测器。值得注意的是,每个后门神经网络模型的触发器以及对应的攻击目标标签是唯一。题目提供了由后门、正常的神经网络模型组成的数据集 (在MNIST、Fashion-MNIST、CIFAR-10、GTSRB四个数据集上基于pytorch框架训练的神经网络模型集合,由.pth文件组成),其中训练集由40个神经网络模型组成(包含20个正常模型,20个后门模型),用于参赛者构建后门检测器。比赛测试集由60个神经网络模型组成,参赛者需在这60个测试模型上进行答题并上传答案。在这道题中给出了已知正常模型和后门模型的训练集,和60个未知是否带有后门的训练集,对于第一问,最直接的思路是去训练一个后门检测器,做一个二分类任务,但是考虑到40个模型可能容易过拟合,因此我们没有考虑这种思路,而是选用了一些经典的方法,比如Neural Cleanse和这个工作之后的一些改进算法来做这道题。在这道题中,题目要求交三项内容,分别是模型中是否存在后门,对应的攻击目标标签和后门触发器。题目最终的评判标准对于后门触发器检测的是cos相似度,但是考虑到现有的后门检测方法,比如NC,检测思路是,如果存在尽可能小的mask,可以激活模型中的后门,则该模型中存在后门,在这个检测思路下,对于触发器的还原相似度并不高。因此,我们将这道题的三小问分成两个部分,第一部分是检测模型中是否存在后门,以及对应的攻击目标标签,第二部分是对于存在后门的模型生成对应的触发器。 考虑到这道题中给出的数据集为10分类和43分类,使用逐类别的检测方式不会耗费较多时间,因此我们考虑NC的检测方式,具体方式为对于每一个label,首先假定这个label为target label,通过优化算法逆向出可以激活这个类别后门的trigger。定义trigger injection:![]() ,其中
,其中![]() 为图片上第
为图片上第![]() 个像素点对应的mask,
个像素点对应的mask,![]() 只可能为0或1,如果
只可能为0或1,如果![]() 为1,则代表该像素点为trigger,如果
为1,则代表该像素点为trigger,如果![]() 为0,则代表该像素点为原始图片。对于trigger的还原,定义为:
为0,则代表该像素点为原始图片。对于trigger的还原,定义为:![]()
对数据集的每一个类别进行迭代,从而得到假设每一个类别为攻击目标标签时对应的trigger。如果一个模型里面存在后门的话,由于trigger具有隐蔽性,那么存在一个很小的trigger就可以让模型把所有样本都分到目标类上面,因此如果模型恢复出来的这个trigger很小的话,那就说明模型中存在后门。我们使用了NC中的原始设定l1范数来评价trigger的大小,从而找到离群点,即可能成为backdoor trigger,具体流程图如下:![]()
寻找离群点的算法使用MAD(Median Absolute Deviation)算法:对于所有label找到的trigger的l1范数,首先计算它们与中位数的差值绝对值,再对这些绝对值求中位数,即![]() ,得到MAD后,计算异常指数
,得到MAD后,计算异常指数![]() ,如果存在某一个类别的异常指数大于2,则代表模型中存在后门,并且该模型的攻击目标标签为这个类别。对于编号id为61283的模型在以不同类别为攻击目标标签时,逆向的触发器的l1范数,其中标红色的为真实目标标签,可以看出,针对label1生成的触发器的L1范数最小。
,如果存在某一个类别的异常指数大于2,则代表模型中存在后门,并且该模型的攻击目标标签为这个类别。对于编号id为61283的模型在以不同类别为攻击目标标签时,逆向的触发器的l1范数,其中标红色的为真实目标标签,可以看出,针对label1生成的触发器的L1范数最小。![]()
在对于每一个类别逆向触发器的过程中,我们参考了《Better Trigger Inversion Optimization in Backdoor Scanning》这篇工作中提出的优化算法Pixelbackdoor,由于NC在逆向触发器的过程中同时优化触发器的位置(mask)和触发器的像素点取值(pattern),因此优化曲面较为崎岖,这篇工作中直接对触发器的pattern进行优化,并同时加入了对于触发器像素点的限制,在达到生成l1范数较小的触发器的同时,使得优化更容易进行,该方法的优化损失函数如下:![]()
可以看出,该优化损失中只存在对于触发器pattern的优化项和对触发器大小的优化项。因此,该优化方式可以得到更平滑的优化曲面,从而达到更好的触发器还原效果。该方法和NC的损失函数优化曲面如下图所示:![]()
因此,我们考虑使用这种方法来作为在后门检测和目标标签检测过程中,逆向触发器的方法。 通过上述方式,我们可以判断出一个模型是否为后门模型以及攻击目标标签。但是我们发现,对于触发器的还原,评分指标是用cos计算相似度,但是在NC和Pixelbackdoor中的假设,均是如果一个模型中存在后门,那么存在一个很小的扰动可以激活模型中的后门,因此在逆向的过程中,逆向的是这个很小的扰动,这个扰动可以激活模型中的后门,但是该扰动和真正的后门触发器并不一定有很高的cos相似度。比如,对于blending或wanet的攻击方式,真实的触发器是在全图片上都存在的,不止在很少的一些像素点上,逆向很小的扰动这个思路很难优化出相似度很高的触发器。因此,我们考虑使用一个生成模型来生成带有触发器的样本。具体的思路为首先在feature map中分离出良性特征,由于该方法不假设攻击目标标签,因此不去寻找对应攻击目标标签的恶意特征。在分离出良性特征后,训练一个Unet模型,该模型用于生成带有触发器的恶意样本,具体流程图如下:通过使用这种方法,我们得到了质量更高的带有后门的触发器,对比如下:![]()
根据题目要求,我们首先尝试了最经典的NC(Neural Cleanse)算法,但是发现NC生成的触发器和检测准确率都不算很高,因此之后开始调研一些sota的工作,找到了我们最终方案中的参考文献。对于一些以检测为目标的方法,对触发器的还原并不是很好,因此我们又重新考虑了单独对触发器进行生成。以上便是我们队对于“模型后门检测”给出的方案,还请各位前辈与技术大佬不吝指教![1] Tao G, Shen G, Liu Y, et al. Better trigger inversion optimization in backdoor scanning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 13368-13378.
[2] Wang B, Yao Y, Shan S, et al. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks[C]//2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019: 707-723.
[3] Towards Reliable and Efficient Backdoor Trigger Inversion via Decoupling Benign Features. In Submitted to The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=Tw9wemV6cb under review.
参赛者需要设计出有效删除神经网络模型中后门的算法。值得注意的是,所设计的后门删除算法尽可能的减少对主任务的影响,即不破坏模型主任务的性能。题目提供了嵌入后门的神经网络模型数据集 (在MNIST、Fashion-MNIST、CIFAR-10、GTSRB四个数据集上基于pytorch框架训练的神经网络模型集合,由.pth文件组成),共包含20个模型,用于测试后门删除算法。题目文件中包含了GTSRB数据集,由于MNIST、FashionMNIST以及CIFAR-10都是公开数据集,因此也可以直接获得。在这道题中,题目给出的可用数据只有20个带后门的模型,由于使用的数据集均为公开数据集,因此数据集是另一个可用数据。由于触发器和目标标签未知,因此我们无法获得模型原本的攻击成功率和在使用我们的方法后的攻击成功率。并且,无法使用需要已知触发器和目标标签的后门删除方法。在这道题中,题目直接给出了20个后门模型![]() ,我们定义这些后门模型在训练的过程中使用的训练数据集中包含了带有触发器的样本
,我们定义这些后门模型在训练的过程中使用的训练数据集中包含了带有触发器的样本![]() ,其中
,其中![]() 是该后门模型对应的触发器,为了保证攻击的隐蔽性,通常
是该后门模型对应的触发器,为了保证攻击的隐蔽性,通常![]() 。我们的目标是在已有的公开的干净数据集上得到一个模型
。我们的目标是在已有的公开的干净数据集上得到一个模型![]() ,使得
,使得![]() 。同时为了保证模型的可用性,希望模型输出的分类结果正确,因此我们定义优化问题如下:
。同时为了保证模型的可用性,希望模型输出的分类结果正确,因此我们定义优化问题如下:![]()
其中![]() 是损失函数,我们使用的是交叉熵损失。在这个定义中,内部的argmax问题希望找到一个触发器,该触发器可以导致模型预测到正确类别的损失函数值变大,误导模型预测目标错误标签,由于我们不知道题目中给出的模型的目标标签,因此这里采用最大化的模型预测和正确标签之间的损失;外部的argmin问题希望优化模型参数,使得不管内部优化问题找到的扰动是什么,都可以让模型预测正确的分类。由于题目中明确说明不可以重新训练模型,最直接的思路是直接对模型进行finetune,但是finetune需要使用大量epoch来使模型遗忘后门,这种方法效率较低。因此,我们分两步解决这个问题。第一步是为了保证模型中的后门被删除,我们使用了一种基于对抗训练的unlearning方法,来删除模型中的后门。同时,为了保证模型的可用性,我们对删除后门后的模型进行了微调,提高模型的准确率。我们调研了现有的sota工作,参考了《ADVERSARIAL UNLEARNING OF BACKDOORS VIA IM-PLICIT HYPERGRADIENT》这篇工作提出的对于上述最大最小优化问题的优化思路,采用二阶优化算法来近似trigger的扰动对于模型参数
是损失函数,我们使用的是交叉熵损失。在这个定义中,内部的argmax问题希望找到一个触发器,该触发器可以导致模型预测到正确类别的损失函数值变大,误导模型预测目标错误标签,由于我们不知道题目中给出的模型的目标标签,因此这里采用最大化的模型预测和正确标签之间的损失;外部的argmin问题希望优化模型参数,使得不管内部优化问题找到的扰动是什么,都可以让模型预测正确的分类。由于题目中明确说明不可以重新训练模型,最直接的思路是直接对模型进行finetune,但是finetune需要使用大量epoch来使模型遗忘后门,这种方法效率较低。因此,我们分两步解决这个问题。第一步是为了保证模型中的后门被删除,我们使用了一种基于对抗训练的unlearning方法,来删除模型中的后门。同时,为了保证模型的可用性,我们对删除后门后的模型进行了微调,提高模型的准确率。我们调研了现有的sota工作,参考了《ADVERSARIAL UNLEARNING OF BACKDOORS VIA IM-PLICIT HYPERGRADIENT》这篇工作提出的对于上述最大最小优化问题的优化思路,采用二阶优化算法来近似trigger的扰动对于模型参数![]() 的影响,并且在这篇工作中给出了这种算法的收敛性和鲁棒性证明。在使用unlearning方法后,我们又进一步对模型进行对抗性训练,从而进一步删除模型中后门的影响。在第一次使用unlearning提交答案后,我们发现分数只有79分,可以看出直接使用这种方法对模型中后门删除不干净,最直接的想法是调大学习率,加大修剪模型参数的力度,但是我们发现这样会导致模型ACC下降严重。因此在此基础上,我们使用了对抗训练,其主要思想是分步优化,首先固定模型参数增加扰动,先优化内部的argmax问题,找到一个让模型分类不正确的扰动,然后固定扰动优化模型参数,在该扰动存在的情况下,让模型依旧可以分类正确,具体过程如下图所示:
的影响,并且在这篇工作中给出了这种算法的收敛性和鲁棒性证明。在使用unlearning方法后,我们又进一步对模型进行对抗性训练,从而进一步删除模型中后门的影响。在第一次使用unlearning提交答案后,我们发现分数只有79分,可以看出直接使用这种方法对模型中后门删除不干净,最直接的想法是调大学习率,加大修剪模型参数的力度,但是我们发现这样会导致模型ACC下降严重。因此在此基础上,我们使用了对抗训练,其主要思想是分步优化,首先固定模型参数增加扰动,先优化内部的argmax问题,找到一个让模型分类不正确的扰动,然后固定扰动优化模型参数,在该扰动存在的情况下,让模型依旧可以分类正确,具体过程如下图所示:![]()
在使用对抗性训练删除后门后,我们观测到模型的准确率可能略有下降,因此,为了保证模型的可用性,我们进一步对模型进行了微调。参考《Fine-Tuning Is All You Need to Mitigate Backdoor Attacks》这篇工作中循环学习率思路,在微调提高模型acc的同时,进一步删除后门。主要思路为在训练的过程中,最开始使用较大的学习率,使模型参数跳出当前局部最优,然后逐渐降低学习率来寻找新的最优解。循环学习率的优化策略为固定迭代次数后lr的峰值减半,逐渐找到模型的最优解。如下图所示:![]()
在我们的实验中,对于unlearning方法,根据原文中的设定,我们进行了100个epoch的unlearning,然后进行了18个epoch的对抗性训练,最后对模型进行微调提高模型可用性,实验中设定的epoch为100,但是根据模型ACC的情况进行了提前停止。在这道题中,我们首先参考了一种现有的sota方案,但是发现由于触发器未知,超参不容易寻找,因此我们使用了对抗训练的方法,进行分步优化,更有利于该题中模型删除后门,对准确率下降的情况进行微调,保持模型的可用性。[1] Zeng Y, Chen S, Park W, et al. Adversarial unlearning of backdoors via implicit hypergradient[J]. arXiv preprintarXiv:2110.03735, 2021.
[2] Sha Z, He X, Berrang P, et al. Fine-tuning is all you need to mitigate backdoor attacks[J]. arXiv preprint arXiv:2212.09067, 2022.
![]()
文章来源: https://mp.weixin.qq.com/s?__biz=MzU5Njg1NzMyNw==&mid=2247487701&idx=1&sn=688146ee953daca964f07294086804f9&chksm=fe5d0855c92a81433594693f4a28364b6cb719a7dc3536020e5651203339fd612b58b25e8d00&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh