2023 年是大模型的元年,2024 年将是 AI 超级应用的爆发年,「一定要有真正贴近用户,贴近场景,让用户感觉到好用、必须用的超级应用才能进一步推动 AI 发展」,在 12 月 16 日举办的极客公园创新大会 2024 上,印象笔记董事长兼 CEO 唐毅提出了上述观点。2023 年,随着 ChatGPT 引发 AIGC 热潮,印象笔记在这一年开始将 AI 的能力由功能释放为服务,全面赋能自己软硬件生态:4 月推出了自研的大语言模型「大象 GPT」,并推出「印象 AI」;
8 月,完成「印象 AI 2.0」迭代(提供专属模型 Adaptive Self Model,并为混合部署训练和调优 AI 路由);
9 月,硬件产品 EverPAPER 支持大象 GPT,打造了 AI 智能硬件的产品品类。
在业界看来,大模型的应用上,目前普遍存在一个「不可能三角」的困境,即难以兼顾通用性、可靠性和经济性。面对这个「不可能三角」,唐毅指出,C 端和 B 端分别有不同的挑战。对 B 端而言,事实验证性是一个关键挑战,如果它的靠谱程度不上升,就很难去解决一些 B 端关键场景的问题;而对 C 端而言,用户可能对模型的经济性以及逻辑推理和涌现能力要求会很高。在考虑大模型的「不可能三角」(通用性、可靠性和经济性)时,需要从多个角度来看待模型和应用厂商所面临的挑战。唐毅提到,在开发 AI原 生应用时,无论是模型厂商还是应用厂商,都需要综合考虑六个关键要素:用户、场景、交互、模型、数据和载体。而为了解决「不可能三角」困境,印象笔记正探索一种「1+N 混合部署」的技术方案,通过 AI 路由进行任务分配,既发挥通用大模型的多步复杂推理能力,也利用专有模型的经济实用和准确性。此外还要综合考虑用户、场景、交互、模型、数据和载体六大要素,以实现「无处不在的 AI 界面」,适应不同场景和需求。以下是唐毅在极客公园创新大会 2024 上的演讲实录,由极客公园整理。有一个观点我先提出来,今天上午 Robin(李彦宏)也提了,不同嘉宾也都提了:2023 年是一个大模型之年,2024 年一定是 AI 的超级应用之年,一定要有真正贴近用户,贴近场景,让用户感觉到好用、必须用的超级应用才能进一步推动 AI 发展,这是我今天演讲重要的核心观点。中国现在有 200 多家公司在做基础模型,非常热闹,大家投入了非常多的时间、资金、人才,有很多进步的同时,也面临同质化竞争的问题。一个比较典型的问题是留存率不够。我们看一些公开的数据,不管是原来有应用+ AI 的产品,还是有大模型加应用的产品,留存率都不高。虽然模型很多,但让大家想起来说我每天都在用,我离不开它了的「真正的超级应用」,还是很少。所以有个问题就是,大模型和这一代新的生成式人工智能势必会带来实质性的商业和社会的变革,但是它是不是正在带来呢?现在一个相对比较客观和实际的情况是这样的,用户想用的时候,会存在比较典型的一些担心:第一个担心是隐私的担心,是不是我问模型的所有问题模型都知道?会不会我问它的问题它就记下来了,训练到模型的大脑里面去了?
第二点是专业能力的问题,它是不是能够具体地帮到我一些专业问题?它的幻觉问题怎么样了?
第三点是使用便捷的问题,现在要使用大模型产品真的有那么方便吗?看起来好像无处不在,但是真正使用起来似乎又会觉得没有那么方便。
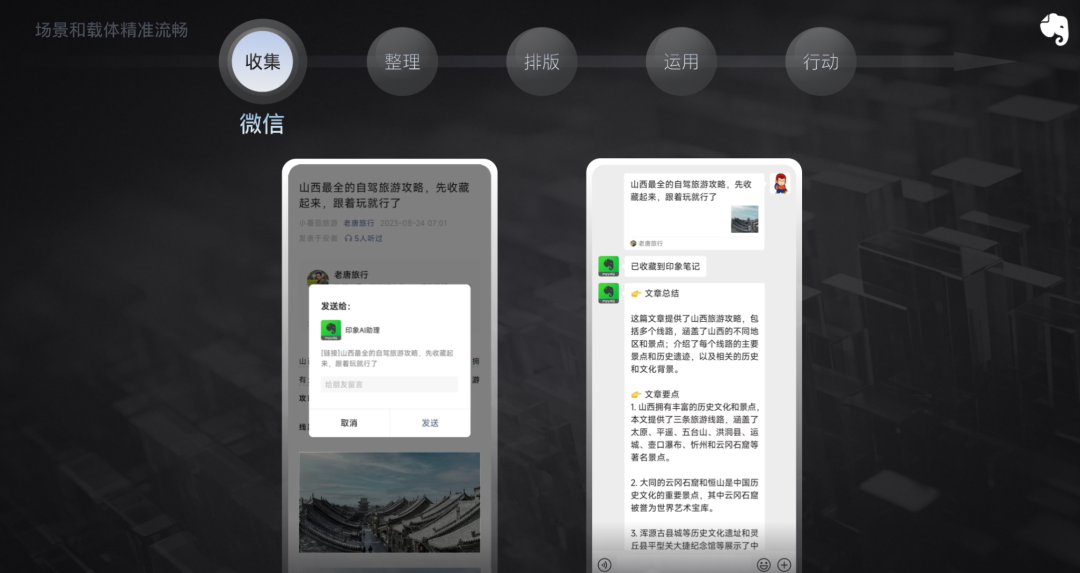
真正用起来会进一步产生三个问题,一个感觉它没有那么聪明,或者说话没在点上,或者真正有一些核心的知识并不了解;还有一点是没有那么靠谱,幻觉的问题还是挺明显;另外确实是不便宜,使用不是很便捷。也就是说大模型,特别是大模型的应用看起来很近,用起来还是有点远。从这一点引入的话,我们会觉得这里存在一个不可能的三角,这个不可能的三角是基于通用性、可靠性和经济性之间的不可能三角。不可能三角这个概念,代表三者之中只能获得其二,难以获得全部。这意味着在大模型的实际应用中,我们很难在同一时间满足这三个方面的要求。从逻辑上讲,模型参数越多,涌现能力、逻辑推理能力和上下文理解能力就越强。然而,仅仅通过扩大参数或优化模型和算法是无法完全解决问题的。一定程度上,大模型具有更强大的涌现能力、逻辑推理能力和上下文理解能力,这些能力与模型一次性能处理的 Token 数量和遵循指令的能力密切相关。然而,随着模型规模的扩大,其经济性和可靠性可能会受到影响。可靠性包括专业知识、领域能力和事实验证等方面。从另外一个角度来讲也就是说,大模型能不能真正在可解释性、安全性和事实验证等方面都做好可能存在很大的问题。就大模型应用而言,现在哪怕就是终端用户和它聊几句天都会感受到这三个方面的「不可能三角」。在这三角里面,C 端和 B 端都分别有不同的挑战。B 端的话,比较大的问题是它的事实验证性如果不强,它的靠谱程度不上升,它就很难去解决一些 B 端关键场景的问题。C 端而言,用户可能对模型的经济性以及逻辑推理和涌现能力要求会很高。![]() 唐毅认为是有方法破解大模型「不可能三角」问题的|极客公园在考虑大模型的「不可能三角」(通用性、可靠性和经济性)时,我们需要从多个角度来看待模型和应用厂商所面临的挑战。这些挑战包括选择合适的载体,载体在哪里?我们到底是用一个很熟悉的原生应用,或者移动应用中的 AI 能力,还是我们应该去到某一个平台上去用它的插件,比如 GPTS 插件等等。数据的使用方式是什么?数据上我们到底是通过 prompt 跟它聊?还是像一些应用的处理方式,把一些文件上传给它?还是真正用我们自己的数据做一定的模型训练?场景上,是在什么地方能够解决哪些问题?应该跳出我现在的应用场景,跳出我现在的熟悉的应用?还是应该留在里面?这些都很难决定。为了解决这些问题,我们需要采用一种不同于以往的思维方式。这其中一个很重要的点是,在开发 AI 原生应用时,无论是模型厂商还是应用厂商,都需要综合考虑六个关键要素:用户、场景、交互、模型、数据和载体。如果简单一点来看,它们之间关系串起来是这样的——用户在某一个场景下需要解决一个什么样的问题,通过什么交互能够更符合用户的需求和场景特点。在这个场景或者这个需求的链路上,怎样通过模型,通过什么样的模型,什么样的模型部署,在什么载体里面解决这些问题?是插件?Web?Desktop?移动端?而在这个过程中,所有产生的数据,这些数据的问题又怎么解决?怎么部署?怎么应用?哪些给模型,哪些不交给模型?这六个元素将是持续需要考虑的,我们印象笔记在这方面的思考,随着技术的发展,基本上每两周更新一次。比如 GPTs 出现的时候我们发现,载体好像迅速从移动端或者传统应用跑到大模型平台上。又比如说 ChatGPT 刚刚出现的时候,有人说,未来一切的交互都变成自然语言的交互,你跟它说话就可以,但是到底是不是这么一回事?这是否真的是未来的趋势?先从交互来说,我们观点是交互和唤起应该是无处不在。我们先看一个典型 LUI(语言交互界面)对话。先来看看笔记里有哪一些影评,然后来讲讲《触不可及》的电影怎么样——这个讲述的回答完全是通过挖掘笔记里面的内容得来的。使用的信息是基于用户授权的,不会用于训练或调优模型。(印象笔记将推出基于用户个人笔记和知识库问答的产品,真正实现打造个人的知识助理。)另一个例子是 Copilot 性质的交互。这里有一篇关于 AI 视频制作的笔记,用户可以要求 AI 总结一下这篇笔记里面有什么内容?笔记里面有哪些 AI 对视频制作的改造可以拿来分类?AI 可以挑出笔记内容,并且同步回答用户的问题。它是自然语言界面和传统 GUI 界面(图形界面)的结合,右侧的 Copilot 是辅助驾驶,主驾驶还是在传统 GUI 界面上,主副驾驶之间是可以互相指引、指导的。在实际工作场景中,如果用户本身就是在一个文档界面进行编辑,比如要写一个采访提纲,写采访提纲之后,还想让采访提纲中间一部分再多解释一下。这种使用场景下最不需要的就是自然语言,用户只需要在传统的界面上操作就可以了。这是一种 in-context 的交互方式。这些例子依次是从纯粹的 LUI 到纯粹 GUI 过程,应该选择在那个场景下和那个用户的情况下最适合的一种交互方式,我们把这个称之为「无处不在的 AI 界面」。第二个元素,场景和载体。不同的工作和场景需要不同的载体来实现最优的生产力工作流。传统意义上来讲,这些功能通常在原生的移动、桌面或 Web 应用中产生。现在通过大模型平台,我们可以通过 API 和内容文件调用来实现这些功能。这当中总会有一个问题——到底应该在传统应用上实现这些功能,还是在大模型平台上实现?还有一个因素是存在很多不同设备——我们需要在各种设备、大模型平台(如 GPTs 类平台)、大模型新推出的原生应用产品,以及传统移动应用之间,找到合适的解决方案——应该在什么地方解决问题?应该在该解决问题的地方解决问题。我们来以规划一次旅行为例,这当中典型的流程包括收集、整理、排版、应用、行动。我现在在微信公众号里阅读一篇关于山西旅行的文章,然后转给我的印象笔记,它就可以帮我收藏在笔记里面。这个场景一定先从微信开始,因为这个信息在微信公众号里面。紧接着我们打开印象笔记,通过 AI 助理来整理内容,标好标签,并且和其他的旅游笔记进行关联。因为笔记里还有两篇其他的笔记,可以自动把它关联上,那么当我想要规划山西旅游的时候,这三篇笔记都是相关的,可以通过 Copilot 形式展现出来,帮我更好地了解目的地。然后我继续在印象笔记的原生应用当中排版,这个排版很重要,因为很多的公众号文章存进来之后不利于阅读,排版也没有优化,也没有目录和很清晰内容标注。我们可以通过 AI 进行有效重新排版,利于阅读。然后规划 7 天行程,可以在原生应用内通过 AI 助理来问,也可以到一个大模型平台上面用插件对话,它的这个规划不是用网上的公用的语料和信息来规划,而是会专门根据所需要的场景来进行规划。然后我们可以在大模型平台通过其他的插件,比如说某一个旅行平台的插件来进行机票酒店的安排。我们也可以同时通过印象笔记的插件反映到我们的日程表里面,反映到我们的清单里面,同时让印象笔记的微信助理提醒行程。这个规划本身可以在微信里进行,可以在原生的应用里规划,也可以在大模型平台上规划。
唐毅认为是有方法破解大模型「不可能三角」问题的|极客公园在考虑大模型的「不可能三角」(通用性、可靠性和经济性)时,我们需要从多个角度来看待模型和应用厂商所面临的挑战。这些挑战包括选择合适的载体,载体在哪里?我们到底是用一个很熟悉的原生应用,或者移动应用中的 AI 能力,还是我们应该去到某一个平台上去用它的插件,比如 GPTS 插件等等。数据的使用方式是什么?数据上我们到底是通过 prompt 跟它聊?还是像一些应用的处理方式,把一些文件上传给它?还是真正用我们自己的数据做一定的模型训练?场景上,是在什么地方能够解决哪些问题?应该跳出我现在的应用场景,跳出我现在的熟悉的应用?还是应该留在里面?这些都很难决定。为了解决这些问题,我们需要采用一种不同于以往的思维方式。这其中一个很重要的点是,在开发 AI 原生应用时,无论是模型厂商还是应用厂商,都需要综合考虑六个关键要素:用户、场景、交互、模型、数据和载体。如果简单一点来看,它们之间关系串起来是这样的——用户在某一个场景下需要解决一个什么样的问题,通过什么交互能够更符合用户的需求和场景特点。在这个场景或者这个需求的链路上,怎样通过模型,通过什么样的模型,什么样的模型部署,在什么载体里面解决这些问题?是插件?Web?Desktop?移动端?而在这个过程中,所有产生的数据,这些数据的问题又怎么解决?怎么部署?怎么应用?哪些给模型,哪些不交给模型?这六个元素将是持续需要考虑的,我们印象笔记在这方面的思考,随着技术的发展,基本上每两周更新一次。比如 GPTs 出现的时候我们发现,载体好像迅速从移动端或者传统应用跑到大模型平台上。又比如说 ChatGPT 刚刚出现的时候,有人说,未来一切的交互都变成自然语言的交互,你跟它说话就可以,但是到底是不是这么一回事?这是否真的是未来的趋势?先从交互来说,我们观点是交互和唤起应该是无处不在。我们先看一个典型 LUI(语言交互界面)对话。先来看看笔记里有哪一些影评,然后来讲讲《触不可及》的电影怎么样——这个讲述的回答完全是通过挖掘笔记里面的内容得来的。使用的信息是基于用户授权的,不会用于训练或调优模型。(印象笔记将推出基于用户个人笔记和知识库问答的产品,真正实现打造个人的知识助理。)另一个例子是 Copilot 性质的交互。这里有一篇关于 AI 视频制作的笔记,用户可以要求 AI 总结一下这篇笔记里面有什么内容?笔记里面有哪些 AI 对视频制作的改造可以拿来分类?AI 可以挑出笔记内容,并且同步回答用户的问题。它是自然语言界面和传统 GUI 界面(图形界面)的结合,右侧的 Copilot 是辅助驾驶,主驾驶还是在传统 GUI 界面上,主副驾驶之间是可以互相指引、指导的。在实际工作场景中,如果用户本身就是在一个文档界面进行编辑,比如要写一个采访提纲,写采访提纲之后,还想让采访提纲中间一部分再多解释一下。这种使用场景下最不需要的就是自然语言,用户只需要在传统的界面上操作就可以了。这是一种 in-context 的交互方式。这些例子依次是从纯粹的 LUI 到纯粹 GUI 过程,应该选择在那个场景下和那个用户的情况下最适合的一种交互方式,我们把这个称之为「无处不在的 AI 界面」。第二个元素,场景和载体。不同的工作和场景需要不同的载体来实现最优的生产力工作流。传统意义上来讲,这些功能通常在原生的移动、桌面或 Web 应用中产生。现在通过大模型平台,我们可以通过 API 和内容文件调用来实现这些功能。这当中总会有一个问题——到底应该在传统应用上实现这些功能,还是在大模型平台上实现?还有一个因素是存在很多不同设备——我们需要在各种设备、大模型平台(如 GPTs 类平台)、大模型新推出的原生应用产品,以及传统移动应用之间,找到合适的解决方案——应该在什么地方解决问题?应该在该解决问题的地方解决问题。我们来以规划一次旅行为例,这当中典型的流程包括收集、整理、排版、应用、行动。我现在在微信公众号里阅读一篇关于山西旅行的文章,然后转给我的印象笔记,它就可以帮我收藏在笔记里面。这个场景一定先从微信开始,因为这个信息在微信公众号里面。紧接着我们打开印象笔记,通过 AI 助理来整理内容,标好标签,并且和其他的旅游笔记进行关联。因为笔记里还有两篇其他的笔记,可以自动把它关联上,那么当我想要规划山西旅游的时候,这三篇笔记都是相关的,可以通过 Copilot 形式展现出来,帮我更好地了解目的地。然后我继续在印象笔记的原生应用当中排版,这个排版很重要,因为很多的公众号文章存进来之后不利于阅读,排版也没有优化,也没有目录和很清晰内容标注。我们可以通过 AI 进行有效重新排版,利于阅读。然后规划 7 天行程,可以在原生应用内通过 AI 助理来问,也可以到一个大模型平台上面用插件对话,它的这个规划不是用网上的公用的语料和信息来规划,而是会专门根据所需要的场景来进行规划。然后我们可以在大模型平台通过其他的插件,比如说某一个旅行平台的插件来进行机票酒店的安排。我们也可以同时通过印象笔记的插件反映到我们的日程表里面,反映到我们的清单里面,同时让印象笔记的微信助理提醒行程。这个规划本身可以在微信里进行,可以在原生的应用里规划,也可以在大模型平台上规划。![]() 唐毅详解印象笔记在大模型上的探索路径|极客公园这里边的逻辑是什么呢?是要去找到「最适合的」场景和载体的配合点。如果你要做一个超级应用,不要试图仅仅在一个平台,或者仅仅用一种交互,或者仅仅选择一种载体,而是要让载体和场景移动、变化、流动。然后我们来谈谈模型,我们认为要解决经济性、通用性、可靠性的「不可能三角」,就要有非常不一样的部署。这里不是越大越好,也不是越专越好。先说一下印象笔记自研的大模型,我们开始比较早,很早就成立了人工智能研究院并开始 NLP 方面的研究,现在知识类的专有模型拥有百亿级别的参数,基于 1 亿多人群的使用行为,进行了 4 年研究和训练而得出的。再说一下数据,数据是一个非常敏感的问题,首先,公有通用的语料虽然很丰富,通用性很强,但是专业性不够。像印象笔记这样的专有模型训练厂商会基于训练到一定程度的基座模型进行进一步的训练和调优,这个过程中用到的是公有的专用数据,也就是知识类的数据或者其他场景下的专有数据,比如说交通类的数据、金融类的数据,目的是增强知识和降低幻觉,印象大模型就是这样训练出来的。但个人的数据怎么办?个人的数据能不能用来训练大模型,或者甚至训练小模型?一个最根本的原则是 - 不经用户明确授权,用户的任何数据都不会被用于任何形式的处理 - 不管是调优、索引还是其它。印象笔记是不会拿个人的数据来训练的。那么,怎么让模型处理数据?一个方法是用户明确授权。在这种情况下,我们会通过用户授权认可的 RAG (Retrieval-Augmented Generation) 能力来处理数据。也就是提前对数据进行向量数据库类的索引和处理,让模型帮助分析数据,同时确保隐私和安全得到保护。智能体是下一个 AI 的发展和应用的重要方向,印象笔记的模型训练也是基于很多的这种任务型数据和复杂任务流程进行的,以及需要多步处理的数据来训练的。大模型不可能三角的问题,也就是通用性、可靠性和经济性的问题,怎么解决呢?我们的「印象 AI」提出的破解不可能三角的独特方法是混合模型方案,它结合了印象笔记自家研发的轻量化大语言模型「大象 GPT」和其他大语言模型。这种混合部署的方式与 MoE(混合专家模型)有相似之处,但它们之间还是存在明确差异的。混合部署具有一定联邦属性,主要通过 AI 路由进行任务管理和任务分配。当收到一个提示或需求时,AI 路由会对这个提示进行评价和判断,并确定任务是分步推理还是一次性解决。如果任务属性与专有模型训练语料更接近,AI 路由会选择仅使用专有模型,因为这样更经济、更靠谱。如果任务需要多步处理和多次推理,涉及不同模型的能力,AI 路由会将任务分配到不同的模型上进行处理。在这种情况下,任务调度能力变得尤为重要。印象笔记作为一款为大量国内和国外用户所熟知的产品,具备一些独特的优势。这些优势包括庞大的用户基础、丰富的私域数据、强大的交互经验、精准流畅的场景载体以及基于智能体的自研模型。此外,印象笔记采用了独特的混合部署架构,以解决大模型在通用性、可靠性和经济性之间的平衡问题。这种混合部署架构有助于实现模型和应用的持续发展,为用户提供更优质的服务和体验。通过这些优势和特点,印象笔记能够为上亿用户提供下一代的超级应用,满足他们在不同场景下的需求。我们希望在 2024 年能够跟用户一起用印象笔记打造持续进化的第二大脑,也希望 2024 年的印象 AI 能够成为 AI 超级应用的种子选手。本文为极客公园原创文章,转载请联系极客君微信 geekparkGO王小川参加极客公园创新大会 2024 时表示,「以前我们老是觉得自己在造工具……但这一次我们造的是伙伴,是个新物种,更像人一样。」
唐毅详解印象笔记在大模型上的探索路径|极客公园这里边的逻辑是什么呢?是要去找到「最适合的」场景和载体的配合点。如果你要做一个超级应用,不要试图仅仅在一个平台,或者仅仅用一种交互,或者仅仅选择一种载体,而是要让载体和场景移动、变化、流动。然后我们来谈谈模型,我们认为要解决经济性、通用性、可靠性的「不可能三角」,就要有非常不一样的部署。这里不是越大越好,也不是越专越好。先说一下印象笔记自研的大模型,我们开始比较早,很早就成立了人工智能研究院并开始 NLP 方面的研究,现在知识类的专有模型拥有百亿级别的参数,基于 1 亿多人群的使用行为,进行了 4 年研究和训练而得出的。再说一下数据,数据是一个非常敏感的问题,首先,公有通用的语料虽然很丰富,通用性很强,但是专业性不够。像印象笔记这样的专有模型训练厂商会基于训练到一定程度的基座模型进行进一步的训练和调优,这个过程中用到的是公有的专用数据,也就是知识类的数据或者其他场景下的专有数据,比如说交通类的数据、金融类的数据,目的是增强知识和降低幻觉,印象大模型就是这样训练出来的。但个人的数据怎么办?个人的数据能不能用来训练大模型,或者甚至训练小模型?一个最根本的原则是 - 不经用户明确授权,用户的任何数据都不会被用于任何形式的处理 - 不管是调优、索引还是其它。印象笔记是不会拿个人的数据来训练的。那么,怎么让模型处理数据?一个方法是用户明确授权。在这种情况下,我们会通过用户授权认可的 RAG (Retrieval-Augmented Generation) 能力来处理数据。也就是提前对数据进行向量数据库类的索引和处理,让模型帮助分析数据,同时确保隐私和安全得到保护。智能体是下一个 AI 的发展和应用的重要方向,印象笔记的模型训练也是基于很多的这种任务型数据和复杂任务流程进行的,以及需要多步处理的数据来训练的。大模型不可能三角的问题,也就是通用性、可靠性和经济性的问题,怎么解决呢?我们的「印象 AI」提出的破解不可能三角的独特方法是混合模型方案,它结合了印象笔记自家研发的轻量化大语言模型「大象 GPT」和其他大语言模型。这种混合部署的方式与 MoE(混合专家模型)有相似之处,但它们之间还是存在明确差异的。混合部署具有一定联邦属性,主要通过 AI 路由进行任务管理和任务分配。当收到一个提示或需求时,AI 路由会对这个提示进行评价和判断,并确定任务是分步推理还是一次性解决。如果任务属性与专有模型训练语料更接近,AI 路由会选择仅使用专有模型,因为这样更经济、更靠谱。如果任务需要多步处理和多次推理,涉及不同模型的能力,AI 路由会将任务分配到不同的模型上进行处理。在这种情况下,任务调度能力变得尤为重要。印象笔记作为一款为大量国内和国外用户所熟知的产品,具备一些独特的优势。这些优势包括庞大的用户基础、丰富的私域数据、强大的交互经验、精准流畅的场景载体以及基于智能体的自研模型。此外,印象笔记采用了独特的混合部署架构,以解决大模型在通用性、可靠性和经济性之间的平衡问题。这种混合部署架构有助于实现模型和应用的持续发展,为用户提供更优质的服务和体验。通过这些优势和特点,印象笔记能够为上亿用户提供下一代的超级应用,满足他们在不同场景下的需求。我们希望在 2024 年能够跟用户一起用印象笔记打造持续进化的第二大脑,也希望 2024 年的印象 AI 能够成为 AI 超级应用的种子选手。本文为极客公园原创文章,转载请联系极客君微信 geekparkGO王小川参加极客公园创新大会 2024 时表示,「以前我们老是觉得自己在造工具……但这一次我们造的是伙伴,是个新物种,更像人一样。」
文章来源: https://mp.weixin.qq.com/s?__biz=MTMwNDMwODQ0MQ==&mid=2653027790&idx=1&sn=163082c2e3c8aec613a2d2781d473ab8&chksm=7e5480784923096e4486556b04f8a082f5122160465fcde1ffa34e3b29f0180a1decf9e07950&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh