read file error: read notes: is a directory 2023-12-25 18:39:57 Author: M01N Team(查看原文) 阅读量:130 收藏
概述
今年以来,大语言模型(LLM)及相关技术飞速发展,不断刷新人们对于人工智能的认知。与此同时,LLM敏感信息泄露(Sensitive Information Disclosure)备受关注,恶意使用者可能会通过技巧来获取和利用与LLM相关的敏感信息并用于恶意目的,如个人身份信息、商业机密或其他有价值的数据,对个人和组织造成损害[1]。
在今年8月份,全球开放应用软件安全项目组织(OWASP)发布了针对LLM应用的Top10(OWASP Top10 for LLM [1])潜在安全风险。敏感信息泄露赫然位列第六,已然成为LLM技术应用推广过程中不可忽视的安全问题。敏感信息泄露是指在LLM在使用的过程中,可能会在回复中包含敏感机密的数据或信息,进而导致未授权的数据访问、隐私侵犯、安全漏洞等风险。
伴随着LLM敏感信息泄露事件的增加,各国人工智能监管相关单位明确指出LLM可能发生敏感信息泄露将直接导致使用者个人及企业遭受财产损失及声誉损害。
本文将通过已发生过的六个真实案例来探讨LLM敏感信息泄露事件的相关敏感内容和泄露影响,以期提升人们对LLM安全的重视。
图1:OWASP Top10中的敏感信息泄露(红色矩形部分)[1]
案例一:ChatGPT泄露个人隐私
泄露事件和敏感信息描述
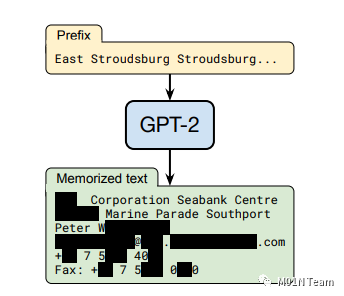
早在2021年的时候,一群来自大型科技公司和名校,如谷歌、苹果、OpenAI、UC Berkeley的学者们就开始对LLM泄露个人隐私的情况进行了调查。他们发现当时最先进的LLM,GPT-2,在面临恶意前缀注入时,模型会返回疑似训练数据中包含的敏感信息的内容[3]。如图2所示,在论文的配图中能清楚地看到模型的回复中包含了敏感信息(已打码),包括某机构与某人的名称、邮箱、手机号、传真号。
图2:GPT-2泄露训练数据示意图 [3]
并不是比GPT-2更新的模型就会安全,ChatGPT在今年4月也曾被爆出严重的泄露问题,部分用户能够看到其他用户的姓名、邮箱、聊天记录标题以及信用卡最后四位数字等,直接导致了意大利数据保护机构宣布,暂时封禁ChatGPT在意大利的使用并要求开发者OpenAI在20天内提供整改方案。
图3:OpenAI CEO对意大利封禁的回应
影响和后果分析:
由上案例分析,LLM通常使用大量的公开和私有数据进行训练,而这些训练数据通常来源于对互联网上海量文本的爬取和收集[12]。这些文本数据潜藏着各种敏感信息,包括但不限于真实的个人资料、职业背景、兴趣爱好、社交网络关系,甚至可能涵盖Cookies、浏览日志、设备信息、保密内容等私密数据。
如果LLM在对话中输出泄露个人敏感信息,可能对个体、社会、技术发展和开发者等多个方面带来负面影响,因此需要重视对于隐私保护和技术责任的迫切需求。
身份盗用:泄露的个人信息可能被恶意利用,导致身份盗用、虚假账户开设等违法行为。
社会工程攻击:攻击者可以利用泄露的信息进行社会工程攻击,欺骗受害者提供更多敏感信息,进而进行欺诈活动。
个人形象受损:可能导致个体的形象声誉受损,特别是对于公众人物或知名个体而言。
违反隐私法规:LLM泄露个人隐私可能违反隐私法规,导致法律责任和对开发者的质疑。
信任危机:随着LLM敏感信息泄露事件的增多,公众可能产生对人工智能技术和相关应用的安全性担忧,影响信任程度。
案例二:OpenAI被告侵犯文章知识产权
泄露事件和敏感信息描述
除了个人信息,知识产权保护在LLM领域也是一个困难的议题。在7月份,OpenAI被两名作家,Paul Tremblay和Mona Awad告上了法院[9],理由是ChatGPT能根据提示词生成关于他们作品的摘要,而且与原版相比“非常准确”,但是二人并没有授权OpenAI使用其有版权的作品进行模型训练。两位作家认为唯一可解释的原因就是OpenAI获取了他们具有明确版权管理信息的图书的内容用于LLM的训练,且没有标明来源或支付版权费。尽管该诉讼可能面临举证困难等问题,这件案件依然为人们在LLM侵犯知识产权方面敲响了警钟。
图4:ChatGPT对于涉案作品的摘要
影响和后果分析
ChatGPT等LLM是通过大规模的互联网文本数据进行预训练的,这些数据的来源可能包含了大量的版权受保护的内容,模型在生成文本时可能无法准确辨别并遵循知识产权规定。LLM在生成文本时可能包含误导性信息,这会导致对已有专业领域知识的错误传播,特别是生成的内容未经验证时。
当前LLM生成内容可能会难以追溯到具体的知识产权信息来源,使得发现和保护知识产权更加困难。因此其存在引发知识产权侵犯问题,对原作者、版权所有者、技术开发者以及整个社会产生负面影响的可能性:
经济损失:LLM生成的内容可能会侵犯原作者的知识产权,如专利、著作权、商标等,导致知识产权的侵权问题,并导致经济损失。
不合法规:LLM知识产权侵犯事件违反了相关法律法规,可能导致法律纠纷和罚款等负面后果,同时需要更严格更全面的新法规的出台,以确保LLM的使用符合法律和伦理标准,避免对社会和个人造成不良影响。
责任追究:LLM的开发者可能面临技术责任的追究,被要求采取更严格的措施来防止知识产权侵犯,包括改进训练数据的质量和模型生成的内容的监管。
案例三:三星泄露商业机密
泄露事件和敏感信息描述
虽然LLM强大的功能可以大幅提升公司员工的日常工作效率,尤其是一些重复性质的工作或文本性质的工作,但是一旦工作内容涉密,使用LLM可能会造成商业机密泄露的风险。仅仅在3月份,三星半导体事业暨装置解决方案部门(简称DS部门)就被曝出三起商业机密泄露事件[10]。DS部门的员工A在处理程序的错误时,将涉密的源代码整体复制下来放到了ChatGPT上。另一名DS部门员工B将自己对于公司内部会议的记录上传至ChatGPT以求自动生成一份会议纪要。此外,还有一名员工C将自己工作台上的代码上传并要求ChatGPT帮其优化代码[8]。由于OpenAI旗下产品会使用用户的输入作为训练数据用于优化LLM,尽管事发后三星立刻紧急禁止员工在工作中使用LLM工具,相关的涉密数据还是已经被上传至OpenAI的服务器。由于ChatGPT背后的AI服务商OpenAI掌握了这些商业机密,三星的商业机密现已被泄露。
图5:韩国三星电子公司
影响和后果分析
三星因ChatGPT泄露商业机密的事件具有重大影响。这一事件的主要原因在于ChatGPT在与用户交互过程中会保留用户输入数据用作未来训练数据,而三星员工在使用ChatGPT时无意间泄露了公司的绝密数据,包括新程序的源代码本体、与硬件相关的内部会议记录等。这些数据泄露事件导致了三起事故,使得三星内部考虑重新禁用ChatGPT。这一事件的影响不仅仅局限于三星内部,还可能对ChatGPT平台和OpenAI公司产生负面影响,甚至可能引发更广泛的法律和监管问题。
商业损失:商业机密信息的泄露可能导致三星公司面临严重的商业损失,包括竞争对手获取敏感信息、市场份额下降等。 这一事件也引起了三星内部的警觉,他们制定相关的保护措施,加强内部管理和员工训练。
违反数据保护条例:员工入职通常会签署相应的数据保护条例以保护商业公司的数据安全,例如欧盟的《通用数据保护条例》(即GDPR)。此类泄密事件严重地违反了数据保护条例。
案例四:LLM泄露训练数据
泄露事件和敏感信息描述
在今年12月份,Google DeepMind的工程师与Cornell, CMU, ETH Zurich等高校的研究人员们发现了一种训练数据提取的攻击方式[11]。研究者们也给出了非常有趣的例子,即要求ChatGPT不停地重复某一个单词,例如“poem”。然而令人意外的是,在这个看似简单的任务中,ChatGPT在输出了一定数量的重复单词之后忽然开始胡言乱语,说出了一大段疑似是其训练数据的内容,甚至还包含了某人的邮箱签名和联系方式,如图6所示。
图6:ChatGPT训练数据提取
在社交媒体上也有人成功复现了泄露,有的人得到了一篇关于某公司的宣传文案,包含公司的具体信息与联系方式,有的人得到了一篇详细的旅行计划,还有的人得到了一段令人毛骨悚然的短句。不出意外的,这些都是ChatGPT在训练过程中接触到并记忆下来的数据,即memorization。在之后,该研究团队扩展了攻击方式并测试了其他公共模型如LLaMA、Falcon、Mistral等,发现这些模型也会面临同样的数据提取威胁。
图7:众多模型都面临训练数据提取的威胁
影响和后果分析
训练数据提取的威胁是指攻击者试图获取机器学习模型训练数据的行为。LLM在训练过程中使用的数据有很大一部分来自于对互联网公开数据的爬取(如GPT系列)。这些未经过滤的公开数据中很可能会意外包含敏感信息。此外,训练数据提取威胁可能对模型、数据提供者以及整个生态系统产生多方面的影响:
隐私泄露:如果攻击者成功提取了模型的训练数据,其中可能包含个人敏感信息,如个人身份、医疗记录等,这可能导致隐私泄露问题;可能包括商业机密,对数据提供者的竞争力和市场地位构成威胁。
逆向工程:获取训练数据后攻击者能够对模型进行逆向工程,了解模型的内部结构和决策过程,对模型的知识产权和商业机密构成威胁并造成更大损失。
对抗性攻击:攻击者获得训练数据后,可以通过对抗性攻击干扰模型的性能,增加误导性的输入,使得模型做出错误的预测。
案例五:LLM遭受恶意序列注入攻击
泄露事件和敏感信息描述
恶意序列注入攻击涉及对攻击提示词的正交变换,例如使用Base64、LeetSpeak 或Ciphey等编码。对于具备固定转换这种编码文本能力的模型,编码可以绕过LLM应用中基于关键词过滤的内容过滤器,从而达成绕开安全机制的目的。对于不具备理解转换编码能力模型,特定的恶意序列可能会诱使模型泄露含编码或与编码相关的训练数据,造成训练数据泄露,或者操纵模型做出意外的行为。如图8所示,在对国内某LLM进行测试后发现,在收到特定的base64编码组成的提示词作为输入的时候,LLM返回的对其解码的回复包含异常内容。经过深入检查后发现,原因是LLM并不具备识别编码内容的能力,且会在回复中意外输出疑似训练数据的内容。
图8:恶意序列注入导致训练数据泄露
影响和后果分析
恶意序列注入是指攻击者通过编造巧妙设计的输入序列,试图操纵LLM进而导致模型的异常行为。这种攻击可能通过利用模型对输入序列的处理方式,使模型泄露其训练数据的一些特征或信息。
漏洞利用:由于LLM的不可解释性,攻击者可能通过特定的恶意序列触发模型的意外行为,过程好比触发模型的漏洞,进而导致模型在处理这些输入时泄露训练数据或敏感信息,包括个人隐私或商业机密。
探测性攻击:攻击者可以通过交互记录反馈逐渐调整优化注入的恶意序列,以获取更多关于模型训练数据的信息,并造成更大损失。
对抗性攻击:攻击者通过对抗性样本的设计,构造一系列输入序列,导致模型输出不稳定或错误并影响模型的性能,使其更容易受到对抗性攻击。
案例六:GitHub Copilot与Bing Chat泄露内置提示词与指令
泄露事件和敏感信息描述
提示词是一系列的语句,用来赋予LLM自己的角色定位,并明确需要向用户提供哪些服务,交互过程中的一些规则也都需要提示词来限制LLM。在大多数情况下,提示词是模型生成有意义和相关输出的关键因素。
提示词泄露自从LLM技术发展以来已经发生过很多次了,如图9与图10所示,著名的GitHub Copilot Chat[7]和微软的Bing Chat[5][6]都曾泄露过自己的提示词,而攻击者仅仅使用了短短的几句话就骗过了LLM且绕开了安全机制的防护。其他LLM诸如ChatGPT、Perplexity AI、Snap等也都有过提示词泄露的历史,并被收录进泄露提示词集合中[4]。
图9:GitHub Copilot Chat提示词泄露[7]
图10:Bing Chat提示词泄露[6]
影响和后果分析
LLM提示词扮演着至关重要的角色,因为它直接决定了模型的运作方式并控制生成的输出内容。提示词在LLM的地位可以类比为代码在软件开发中的作用,它们都是驱动整个系统运作的核心元素。然而作为这样一种关键数据,提示词也有着被泄露的风险:
知识产权风险:泄露的提示词可能包含模型开发者的创意和独创性信息,构成知识产权和商业机密的风险。如果泄露的提示词涉及产品,可能导致企业面临竞争劣势。
提示词攻击:攻击者可以通过提示词注入等方式欺骗LLM,绕开安全机制并诱导其输出提示词,造成LLM开发者的损失,或根据泄露的提示词来有针对性地寻找LLM的安全漏洞。
滥用风险:LLM内置提示词或指令的泄露可能会暴露模型提供服务的原理,泄露的提示词可能被滥用,用于生成有害或违法内容,对社会产生潜在危害。
总结
通过对上述六个真实案例进行了剖析,本文不仅揭示了LLM在安全领域面临的挑战,也强调了敏感信息泄露可能带来的严重后果。保护LLM的安全性不仅是科技发展的需要,更是保障社会稳定和信息安全的必要措施。我们呼吁加强安全意识,采取有效措施应对潜在的安全威胁,确保LLM在应用中的安全性和可信度。
LLM技术的飞速发展带来了大量机遇,但如何正确地应对其逐渐凸显的安全方面的问题也是关键。尤其随着近些年国内环境对于信息安全的愈发重视,LLM相关的安全内容急需受到重视。绿盟科技及其产品也将持续跟随着科技发展,为用户提供专业的安全守护。我们期待与全球的合作伙伴一起,共同推动人工智能安全领域的发展,创造一个更智能、更安全的未来。
附录:参考文献
[1] OWASP, “OWASP Top 10 for LLM”, 2023
[2] 国家网信办网站, 《生成式人工智能服务管理办法(征求意见稿)》, 2023
[3] Carlini et al. Extracting Training Data from Large Language Models, 2021
[4] https://matt-rickard.com/a-list-of-leaked-system-prompts
[5] https://twitter.com/kliu128/status/1623472922374574080
[6] https://twitter.com/marvinvonhagen/status/1623658144349011971
[7] https://x.com/marvinvonhagen/status/1657060506371346432
[8] https://zhuanlan.zhihu.com/p/622821067
[9] Kaysen, “ChatGPT版权第一案:OpenAI面临六项指控,因输出图书摘要被“抓包””, 腾讯网, 2023
[10] 褚杏娟, “三星被曝芯片机密代码遭 ChatGPT 泄露,引入不到 20 天就出 3 起事故,内部考虑重新禁用”, InfoQ, 2023
[11] Nasr et al., Scalable Extraction of Training Data from (Production) Language Models, 2023
[12] Brown et al., Language Models are Few-Shot Learners, 2020
绿盟科技天枢实验室:天枢实验室立足数据智能安全前沿研究,一方面运用大数据与人工智能技术提升攻击检测和防护能力,另一方面致力于解决大数据和人工智能发展过程中的安全问题,提升以攻防实战为核心的智能安全能力。。
M01N Team公众号
聚焦高级攻防对抗热点技术
绿盟科技蓝军技术研究战队
官方攻防交流群
网络安全一手资讯
攻防技术答疑解惑
扫码加好友即可拉群
如有侵权请联系:admin#unsafe.sh