我在直播的时候每隔那么段时间就会遇到一个问题:黑哥你现在在关注哪一块?实际我很多年都没有太多的变化,在技术维度上我一直就是关注数据和漏洞这一块。
漏洞和数据是网络安全的两大基石 -- IC (知道创宇CEO)
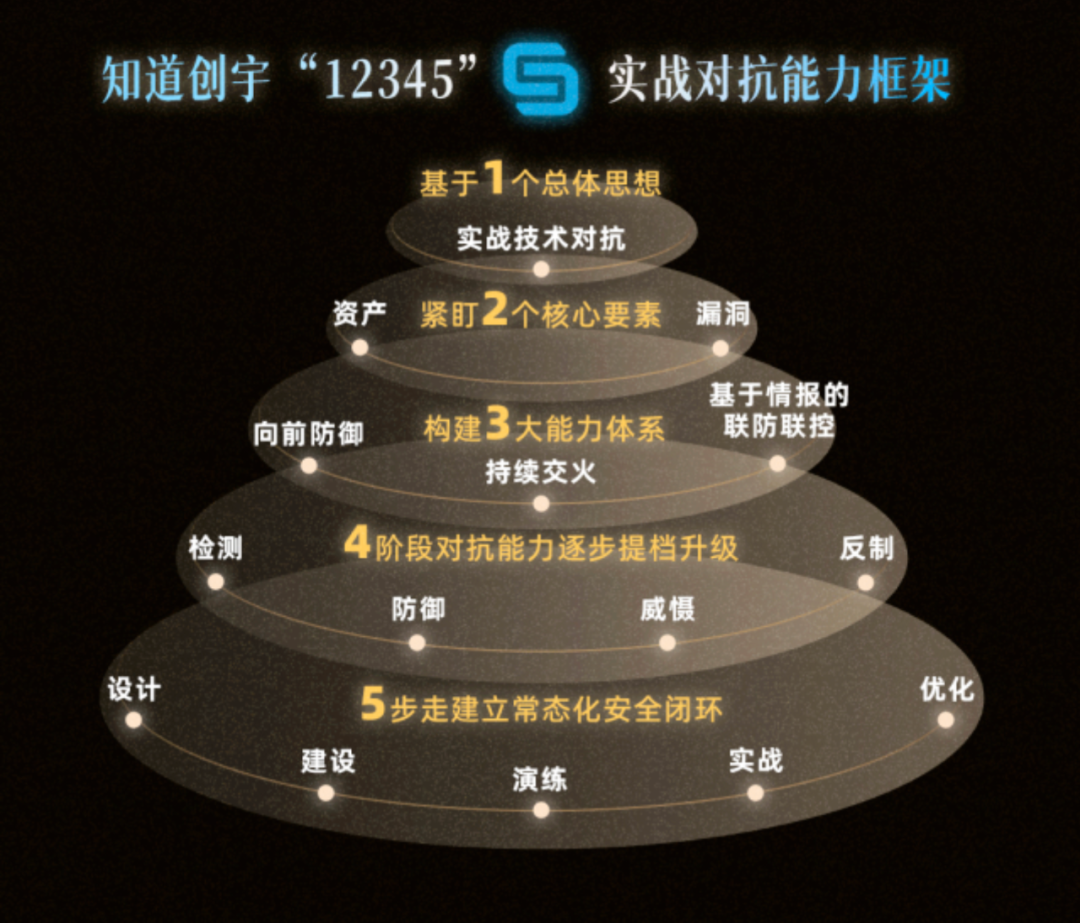
这句话其实我也提到过很多次,而且我们公司成立这么多年来也是一直围绕这两块能力建设始终没有动摇过,在最新发布的《砥砺奋发 共向未来|知道创宇2023年度回顾》 一文中,可能有一些朋友觉得这个只是我们的一个对外的PR而已,实际上在我看来里面还是有我们不少的干货分享的,尤其是下面这个“12345”框架
我们一直在强调“实战安全”才是“真安全”的1个整体思想,接下2个核心要素实际上就是上面提到的数据(“资产”)与漏洞,然后通过数据能力做到了真正的“向前防御”
向前防御的核心是数据及漏洞的提前把控 -- 黑哥尔
美帝是最早提出“向前防御”这个概念的,我觉得只有理解上面这句话才能这真正理解美帝这几年的策略及转变,在我们这么多年大量的实战场景先真正做到的“向前防御”。
至于其他几个点这里就不一一介绍解释,有兴趣的可以联系我们做进一步的沟通交流。
在《砥砺奋发 共向未来|知道创宇2023年度回顾》的另外一个关注点就是“技术为王”,前面我跟一些朋友喝酒或聊天的时候遇到好几次都主动说你们404的paper分享做的很不错,这个时候我都非常自豪的说,这个是我们404实验室的立身之本,我们已经坚持10余年的分享了,在2023年我们列举的那些只是其中的一部分,很多是集中在为威胁情报APT检测维度上的,这个主要是今年我们的重点工作依赖我们的独有的视角及数据能力,包括我们的漏洞检测情报能力等等,在我们近几年来在客户现场实战测试效果来看我们的能力都是非常非常亮眼的,有点发现能力远超友商
当然在这些之外我们还发布了很多重要的数据分析报告,尤其是测绘能力方面的,这个算是我们传统项目了,这里我来补充下几个,如:
在2023年5月4日 青年节这天正式对外发布了我们搞了1整年的报告
这篇报告重复体现我们对数据的理解及分析提取能力,另外还有几篇非常有意思的paper:
《韩美大规模联合军演挑衅升级?朝方 APT 组织近期攻击活动分析》
这些都很好的印证了:
网络空间与现实空间都是存在各种映射关联的,这才是赛博空间的真正意义! -- 黑哥尔
这也是我一直在强调的“获取更多的数据、赋予数据灵活”、“数据-->知识-->智慧-->决策”
“实际上漏洞的最终目的是对数据权限的控制” -- 黑哥尔
在这个时间点很多家都推出了各种各样的2023年的各种排行榜,关于去年漏洞的我个人觉得我们404实验室推出的2023年10大漏洞事件还是非常靠谱的,这个排行榜完全基于实战角度,通过这些漏洞可以看出去年的漏洞实战场景下的趋势:
相比于漏洞本身我更加喜欢漏洞背后的故事,比如Cisco IOS XE系统WebUI未授权命令执行漏洞实际(CVE-2023-20198,CVE-2023-20273)里面涉及到的攻击者于网络空间测绘平台之间多次PK对抗是非常难得一见的,另外基于lua的后门也非常让人印象深刻,除了这些背后还是有很多其他的8卦故事,可惜很多不可说,也就只能相忘于江湖了,另外一个就是差不多火了一年的卡巴斯基披露的“三角测量行动”(Operation Triangulation),这个也是我个人今年关注的重点:
《"Operation Triangulation" 卡巴斯基被黑》
《"Operation Triangulation" 卡巴斯基被黑 - 续》
可惜“随缘”的程度不够,导致在年底卡巴斯基在37C3上再次披露后才得到更多人的“震惊”,实际上漏洞利用链在SaS2023上已经公布,只是这次37C3把关注点放在了CVE-2023-38606是不是苹果的后门而引发更多的关注和讨论,果然阴谋论才是激发关注的法宝 ...
可惜的是之所以说是“阴谋论”的东西基本上是不可能真相的结果给出来的,很多的硬件专家包括卡巴斯基的人也提到这个可能只是为了方便调试而留下的某个接口
https://social.treehouse.systems/@marcan/111655847458820583
相比这个问题,其实我更加想知道攻击者是怎么得到找到这个点的:
另外的一个点就是这个漏洞链,实际上可以说是两条完整的Full Chan
这个点也是让疑惑很久,就这个疑问我问了下iOS一线选手阿智同学(https://mp.weixin.qq.com/s/vwRgZyGqTTI6lrCGtbmmMQ )最后的webkit流程可能只是为了来个shellcode,这让我想起来当年遇到的搞黑产的选手利用一个XSS漏洞只是为了实现一个URL跳转,这个点其实我在前面的文章也有提到,说明攻击者为了实现完美无感的的0click的攻击场景,而不用担心“成本”,另外一个YY的点就是从工程化及漏洞供应链角度上思考,可能这前后是不同的团队合作化的结果?
至于其他的一些关注的点可以看看我以前的文章,从CSO的角度上来看这个事情,还是非常佩服卡巴斯基的,有很多的能力只有真正实战的场景下才能体现出来!当然我之前的文章里我也提到了卡巴斯基能溯源出完整的漏洞链主要是攻击者没有设计“一次性攻击”相关机制(这个可能也跟设备重启后导致控制失效有关),所以卡巴斯基可以重复获取相关样本进行分析提炼,但是这个不能由此否认卡巴斯基的研究能力,而且我觉得iOS可能是不是卡巴斯基研究员平时主要研究的平台,这些都是研究者真正的实力体现。当然这个里面也有一些值得反思的事情,比如这个攻击早在2019年有攻击痕迹,显然卡巴斯基也有对应的流量检测系统,那么为什么会有那么长的发现周期呢?
安全设备只能尽可能解决“视”的问题,不能解决“见”的问题!所以很多时候即使投入了大量的安全设备也很可能处于“视而不见”的尴尬状态!——黑哥尔
说实话这个在很多的实际安全过程中坚持遇到的问题,这里存在着很多的因素,常见的如:防御设备就是摆设平时压根就没人看、防御设备预警太多看不过来、攻击预警有人看但是这个人看到的时候觉得是个小问题所以忽视 等等
所以我们在安全实现过程中,需要解决“视”的问题,也要解决“视而不见”的,而知道创宇推出的创宇铁卫MSS服务,可以帮大家解决这两大难题,我们可以提供专业的设备的同时提供专业的专家团队贴身服务,最终真正赋能于客户!(有需求的可以联系我 :))
另外我想强调的一点是这个世界不存在绝对安全的网络,很多时候可能是攻击已经发生了你看不见,还有一种可能是你根本就不值得别人盯着,所以我们在安全实践者的一个默认前提是:如果你的公司或者组织值得被人攻击,也就是有人盯上了,那么你需要做的第一个假设就是你肯定会被攻击搞定,那么怎么尽可能发现成为核心关键!
盛名之下,必有小鬼!亚历山大~~ -- 黑哥尔
在4年多的时间里卡巴斯基攻击者都做了哪些动作,有没有其他横向摆渡等问题,至今也没有任何相关信息,估计最后也只能是个谜!
从我去年发布的公众号文章来看,我在2023年的一个关注点还是在于ChatGPT大模型上:
4月 《大模型是小模型的基础》
我们回过头来看这两篇文章,到目前为止ChatGPT的进化过程及现在看到的一些安全方向上的应用尝试基本上是符合的,比如11月GPTs的发布就是很典型的一个“大模型是小模型的基础“应用,也就是把之前的精调模式做了进一步的升级,用户可以自己提交Knowledge库,还可以通过Actions调用第三方API,这个完整实现自动化及智能化各种调用,之前LangChain、AutoGPT等应用官方更加智能化的实现了,所以不得不在朋友网感叹一下:
GPTs虽然很强但是距离“模型级服务(MaaS)”还有一点差距,因为在的体验中还存在很多的核心限制:
ZoomEye GPTs 演示视频
这几点看起来是比较具体的事情,尤其是第三点。如果不解决设计好用户提交的配置问题,很难实现所谓的具有真正意义的GPTs Store,当然这些问题都是可以依靠“钞能力”解决的,只是目前就商业模式也还是单纯的plus充值,而没有真正面向用户的模型级服务(MaaS),或者ChatGPT需要考虑下这个“对象”问题(谁是使用者,谁是开发者)。
当然我觉得这个问题同样存在于非ChatGPT的第三方应用服务,类似GPTs的有很多开发者及创业者在做这个方面的工作,在安全方向上的应用之前我在朋友圈里推荐过的 https://www.secasst.com/ 相比线上的我更加推荐客户端版本,最终实现的Agent运行的场景(目前是使用本地Docker容器),未来我觉得这个Agent运行环境直接决定了这类工具的应用场景的上限。
另外一个就是我的老朋友刺(道哥)的创业项目:https://kmind.com/ ,当然他这个项目定义的场景不在安全上,但是我想他这个东西做好了安全应用也是完全没问题的,关于这个问题理解他写了一篇三万字的文章《我们是KMind,志在发明个人AI计算机》 当然你不要被道哥文笔迷失了方向,目前看到的一些应用在我看起来跟前面提到的一些应用是类似的,不过他这个模式更加有点趋向于我之前文章里的“模型级服务(MaaS)”的模式。
不过刺文章提到的“数据垄断”的观点我倒是不是那么感同身受,我比较赞同的一句话,数据是AI的前提或者基础,GPT大模型等的爆发基本实现了一个非常有用的东西,我们需要纠结的是用户数据怎么来的问题,目前提供这些用户数据的都集中在各大互联网厂商,所以API等调用成为了目前可能最有效的方式,当然要实现真正的AI计算机我可能更加看好苹果这种公司,类似Siri控制一切,我想先阶段的技术应该能很好的解决之前Siri的各种疼点,可惜目前还看到苹果公司在大模型上的一些布局,可能在偷偷开发AI版本的iOS也是有可能的,如果在传统OS层面能获取用户各种APP互联的数据那也是有这先天的优势,当然可能在互联网生态的角度上苹果估计不会这样去做。
去年自己公司也做了一些类似的平台开发,这里还没有正式对外开发,有兴趣的可以联系我们体验交流。
这些非ChatGPT的应用跟GPTs相比化,在智能化上肯定是不如GPTs的,但是这些自己开发的平台可以弥补目前GPTs带来的一些限制,另外在安全应用及隐私角度上本地大模型的及用户本地数据空间等模式还是需要考虑的,只是现阶段还是在于“能力展示”阶段,基本没有出现过杀手级的颠覆式应用,更不用说在安全方向的应用了,因为现在更多的展示大模型在知识库及自动化的能力上,在我看来降低安全技能门框目前还是比较伪的伪命题!另外一个方面也缺少非大模型不能解决的问题,所以未来还是有很长的路要走,当然也有可能是不是突然的杀手级颠覆式的出现,很可能是“润物细无声”的漫入大模型时代!
在去年GPTs发布不久实际上我看到周围的人关注度是不够的,相比之下更多的人比较关注OpenAI一波三折的政变,在我看来这个其实反应了技术人的一些“劣根性”:“鱼都没抓到就,就开始纠结鱼刺卡不卡喉咙的问题”,这个问题实际上在我们日常的工作中经常存在这种类事的问题!
安全是业务的一个属性 -- 黑格尔
其实在之前的文章里相比大模型等应用带来的安全问题我更加关注大模型在安全领域里的应用,比如尝试了Prompt编程的问题、使用ChatGPT识别ZoomEye的设备指纹进行画像等,当然还有内容安全方向SafePrompt等尝试等等
这里顺带提一下去年影响比较深刻一点的大模型的安全问题,比如数据泄露的问题、LangChain的Prompt导致的代码执行漏洞(CVE-20223-29394)、Exploiting Novel GPT-4 APIs (https://arxiv.org/abs/2312.14302)等
上面一些都比较杂乱的提到了2023年关注的一些点,然后我直播的时候也经常会遇到一些人问的问题:关于未来的趋势预测等问题!我每次都非常强调,其实我很少去做这种趋势性的预测,因为我的关注点实际上有限的,很多时候现实是“计划赶不上变化”,可能去年大环境的问题,很多的公司都面临倒闭,裁员优化等问题,所以不可避免带来各种迷茫的担忧,所以在去年实际上我也一些谈情怀的鸡汤,安全的方向其实是关注的业务的方向,业务在哪里安全就在哪里,这个其实也说明安全的需求是非常大的,但是这也说明另外一个安全的弊端,因为业务是多种多样的,所以安全必然是碎片化的,再加上先前的安全市场很大一部分是建立在伪供需的基础上的,很多东西都是人为创造出来的泡沫,一旦遇到大环境的变化,比如出现优胜劣汰,这不一定是坏事,但是要坚持下去确实需要莫大的勇气及投入。
祝大家2024年一切顺利!希望遇到更多有缘人!
如有侵权请联系:admin#unsafe.sh