2024-1-10 11:28:59 Author: mp.weixin.qq.com(查看原文) 阅读量:6 收藏
在本届ICASSP 2024 各类音频国际挑战赛中,字节跳动流媒体音频团队联合西北工业大学音频语音与语言处理研究实验室,在丢包补偿(Packet Loss Concealment, PLC)与音质修复(Speech Signal Improvement, SSI)两个挑战赛道中,多项指标上表现优秀,分别取得第一和第二的优异成绩,达到国际领先水平。
ICASSP峰会上的音频挑战赛由国际音频顶级会议 ICASSP 和微软联合发起,旨在激发各研究构在音频效果与音质提升上的研究,自第一届举办以来就吸引了亚马逊、腾讯、阿里巴巴、百度、快手、中科院、西工大等全球诸多知名企业和科研院所的参与。随着流媒体领域技术的不断发展,让声音听得清,听得真,变成音频技术行业发展必然趋势。围绕着如何让用户有最优的音频体验,多个研究团队对音频从采集到转发进行端到端的优化,这一过程包含了如何对音频采集缺陷,算法处理缺陷,编解码缺陷,网络传输缺陷等进行一体化修复。本届挑战赛中,字节跳动流媒体音频团队结合真实的业务落地场景,参加了丢包补偿与通用音质修复这两个挑战赛道。
ICASSP PLC 挑战赛旨在解决网络IP通话中长间隔数据包丢失和全带音频(48k Hz采样率)处理的问题。该挑战具有严格的时延限制,同时提供了苛刻的数据集来反映不利的网络条件。主观评估将使用 P.804 多维音频质量评估方法进行,同时 WER 也被用于评估参赛系统生成语音的可懂度。流媒体音频技术团队通过对模型结构进行优化,有效降低了丢包补偿模型的复杂度。同时,通过多判别器对抗训练与多任务学习,使丢包补偿模型可以以高质量、高可懂度恢复丢包片段,最终取得第一的成绩。
ICASSP SSI 挑战赛旨在解决通信系统中语音信号面临的频率响应失真、不连续失真、响度失真、噪声和混响这五类问题。该挑战赛在严格设置模型时延以及因果性的前提下,使用 ITU-TP.804 标准下的主观意见分和语音识别率综合评判名次。流媒体技术团队使用两阶段模型结构将复杂的修复问题简化为多个子任务,在第一阶段主要修复频率响应失真、不连续失真以及响度失真,并进行初步降噪与去混响;在第二阶段进一步去除第一阶段生成的伪影以及残余噪声。最终,团队在实时赛道取得第二名的成绩。
丢包补偿系统
为解决48kHz全带音频处理复杂度的问题,在丢包补偿系统中使用了频域模型,并根据频率将音频分为 0-8kHz,8-24kHz 两个子带并行处理。将主要计算量集中在对听感影响更大的 0-8kHz 频段,实现了低复杂度、高质量的丢包补偿。为了应对长间隔丢包问题,在编解码器每层后添加了时频扩张卷积模块(TFDCM),在保持小尺寸卷积核同时通过时间和频率维度逐层膨胀的因果扩张卷积捕获长时历史信息与频率相关性。
为了更高质量的补偿音频,结合使用频域多分辨率判别器、时域多周期判别器与 MetricGAN,进行生成对抗训练,使得生成音频听感优秀。对于长间隔丢包以及可懂度的问题,采用多任务学习框架。除了通常的语音信号相似度学习,还引入了基频预测与基于 whisper 的语义理解损失函数。模型最长能够以高质量恢复超过100ms的丢包片段,且恢复音频可懂度较高,词正确率(WAcc)指标领先所有参赛队伍,总体评估得分并列第一。
丢包补偿模型结构示意图
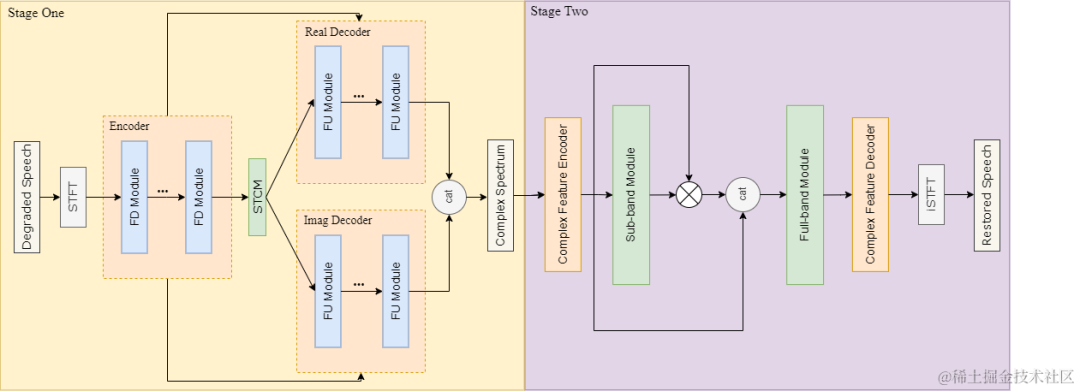
音质修复系统
为了修复同时受多种失真影响的音频,构建系统中使用了两阶段模型架构,在不同阶段着重对不同失真进行处理。一阶段模型使用映射(Mapping)的方式直接预测修复后音频的复数谱,从而使模型同时具备生成音频缺失成分与消除干扰信号的能力,同时为了提升模型的长时捕获信息的能力,在编码器和解码器中引入了时频卷积模块(Time-Frequency Convlution Module,TFCM);由于映射法的不稳定性,可能产生伪影,因此引入使用掩蔽(Mask)方式的二阶段模型,并采用子带-全带建模的方式对频带进行细粒度建模,从而进一步消除一阶段模型生成的伪影与残余噪声。
为了提升生成的音频成分的自然度,引入生成式对抗网络框架,使用多分辨率判别器、分子带多分辨率判别器辅助模型进行训练。同时为了多阶段模型在训练时更容易收敛,首先在降噪和去混响任务上对二阶段模型进行预训练,然后冻结已训练完成的一阶段模型的参数,并将其与预训练的二阶段模型级联进行联合训练,从而加快模型收敛。
音质修复模型结构示意图
加入我们
字节跳动流媒体音频团队,致力于提供全球互联网范围内高质量、低延时的实时音视频通信能力,帮助开发者快速构建语音通话、视频通话、互动直播、转推直播等丰富场景功能,目前已覆盖互娱、教育、会议、游戏、汽车、金融、IoT 等丰富实时音视频互动场景,服务数亿用户。音频开发工程师和音频资深算法工程师热招中!戳原文 or 打开链接查看招聘详情:https://job.toutiao.com/s/i8cuNmcf
如有侵权请联系:admin#unsafe.sh