
Premessa
Lo User-Agent è una riga di testo che un browser o un’applicazione invia a un server web per identificarsi. In genere include il nome e la versione del browser/applicazione, il sistema operativo e la lingua.
La struttura è formata da un elenco di parole chiave, con commenti facoltativi, che forniscono ulteriori dettagli. Questi token sono generalmente separati da spazi e i commenti sono racchiusi tra parentesi. Ciascuna parte della stringa User-Agent aiuta il server a determinare come fornire contenuto in un formato compatibile per l’ambiente software del client.
Un esempio potrebbe essere
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36- Mozilla/5.0: questo è un identificatore generale utilizzato per compatibilità
- (Windows NT 10.0; Win64; x64): questa parte specifica il sistema operativo come Windows 10, edizione a 64 bit, su un processore basato su x64
- AppleWebKit/537.36: significa che il browser utilizza il motore di rendering AppleWebKit, che è responsabile della modalità di visualizzazione dei contenuti web
- (KHTML, like Gecko): indica che il browser è compatibile sia con i motori di rendering KHTML che con Gecko, migliorando la compatibilità tra browser.
- Chrome/120.0.0.0: specifica il browser come Chrome e fornisce il numero di versione, che in questo caso è 120.0.0.0
- Safari/537.36: l’inclusione di Safari con lo stesso numero di versione di AppleWebKit suggerisce la compatibilità con gli standard di rendering di Safari
Perché quindi monitorare lo user-agent?
I threat actor spesso alterano o creano stringhe User-Agent con l’obiettivo di camuffare il loro traffico all’interno di richieste legittime.
Un esempio è Raccoon Stealer, noto per l’utilizzo di User-Agent specifici durante la comunicazione con il C2. Queste stringhe User-Agent, siccome sono univoche e distinte, riducono al minimo le possibilità di falsi positivi durante le sessioni di analisi dei log o nelle regole di rilevamento.
Tuttavia è bene ricordare che i casi in cui la sola analisi dello user-agent sia sufficiente per identificare un traffico malevolo sono davvero pochi; vedremo più avanti come questa analisi sia fonte di un grande numero di falsi positivi.
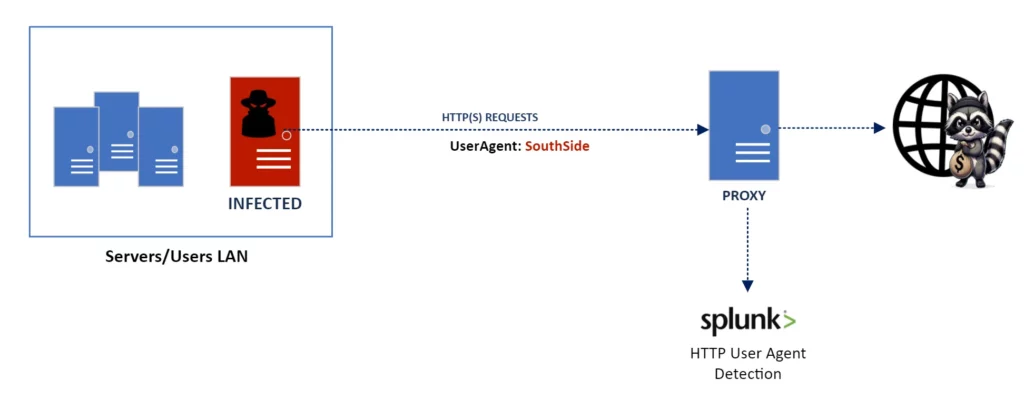
Un primo passo
Una buona lista (quasi) “pronta all’uso” la si può trovare a questo indirizzo.
In breve le colonne sono:
- http_user_agent: questo campo viene utilizzato per abbinare stringhe User-Agent sospette nel SIEM. Supporta voci con caratteri jolly per una corrispondenza flessibile e non fa distinzione tra maiuscole e minuscole
- metadata_description: descrizione dello User-Agent
- metadata_link: collegamento al codice sorgente, al repository o all’articolo che fa riferimento allo User-Agent sospetto
- metadata_flow_direction: direzione del flusso per il rilevamento
- metadata_category: Categoria di minaccia dello User-Agent (C2, Malware, RMM, Compliance, Phishing, Vulnerability Scanner, Exploitation…)
Viene pertanto semplice inserire nelle nostre regole di analisi il controllo e la generazione di allarmi laddove si presentino le occorrenze.
Per prima cosa è doveroso sottolineare nuovamente che questa pratica è fonte di falsi positivi e che questi, in una buona gestione, sono da dover gestire (perdonate il gioco di parole). Inoltre, queste operazioni, non sono "set and forget", ma devono essere costantemente mantenute aggiornate.
Partendo da queste grandi verità, volendo consigliare altre semplici regole di rilevamento oltre a quella già descritta, queste potrebbero essere ricavate andando a controllare:
- dimensione dello user-agent (se molto grandi o molto piccole)
- più connessioni in un breve lasso di tempo con user-agent diversi
- corrispondenza mancata tra user-agent e sistema operativo
- analisi degli user-agent rari o di quelli malformati
- frequenza di utilizzo: è possibile identificare i user-agent che vengono utilizzati con frequenza anomala.
- analisi del testo: è possibile analizzare il testo del user-agent per identificare parole o frasi che potrebbero indicare attività dannose o malevole.
- confronto con una baseline: è possibile confrontare i dati sui user-agent con una baseline di dati conosciuti e sicuri.
Tuttavia, come già detto, non sono da prendere come verità assoluta e quindi vanno sempre contestualizzate all’interno delle vostre infrastrutture.
Threat Hunting
Hacker utilizzano spesso HTTP per facilitare le comunicazioni tra il sistema compromesso e C2. Dopotutto, non è necessario progettare un protocollo personalizzato quando puoi utilizzare l’HTTP che fornisce già la maggior parte delle funzionalità di cui si ha di bisogno. Inoltre l’HTTP in genere è consentito dalla maggior parte delle reti senza restrizioni pertanto è conveniente che il traffico malware si nasconda nella navigazione web già diversificata avviata dall’utente.
Quando un utente malintenzionato sceglie di utilizzare HTTP, ottiene l’accesso ad un’ampia gamma di funzionalità le quali forniscono immediatamente la possibilità di controllare la negoziazione del contenuto anche in base all’uso dell’user-agent.
Dirò una cosa ovvia ma, in prima battuta, se il traffico è in HTTPS non ci sarà modo di visionarne il suo contenuto pertanto è necessario implementare una buona politica di deep packet inspection per amor di decrittare tutto il traffico non in chiaro.

Conclusioni
Il rilevamento dello user-agent è fondamentale per i team SOC nell’identificare le minacce. Tuttavia questa pratica è spesso sottovalutata in quanto è fonte di non pochi grattacapi relativi alla gestione dei falsi positivi che ahimè si devono mette in conto.
Spero vivamente che con gli esempi forniti di migliorare il processo di threat hunting, dando spunti per aiutarti a scoprire informazioni più significative con meno falsi allarmi.
EOF
如有侵权请联系:admin#unsafe.sh