By Michael Brown

Late last month, DARPA officially opened registration for their AI Cyber Challenge (AIxCC). As part of the festivities, DARPA also released some highly anticipated information about the competition: a request for comments (RFC) that contained a sample challenge problem and the scoring methodology. Prior rules documents and FAQs released by DARPA painted the competition’s broad strokes, but with this release, some of the finer details are beginning to emerge.
For those who don’t have time to pore over the 50+ pages of information made available to date, here’s a quick overview of the competition’s structure and our thoughts on it, including areas where we think improvements or clarifications are needed.
*** Disclaimer: AIxCC’s rules and scoring methods are subject to change. This summary is for our readership’s awareness and is NOT an authoritative document. Those interested in participating in AIxCC should refer to DARPA’s website and official documents for firsthand information. ***
The competition at a high level
Competing teams are tasked with building AI-driven, fully automated cyber reasoning systems (CRSs) that can identify and patch vulnerabilities in programs. The CRS cannot receive any human assistance while discovering and patching vulnerabilities in challenge projects. Challenge projects are modified versions of critical real-world software like the Linux kernel and the Jenkins automation server. CRSs must submit a proof of vulnerability (PoV) and a proof of understanding (PoU) and may submit a patch for each vulnerability they discover. These components are scored individually and collectively to determine the winning CRS.
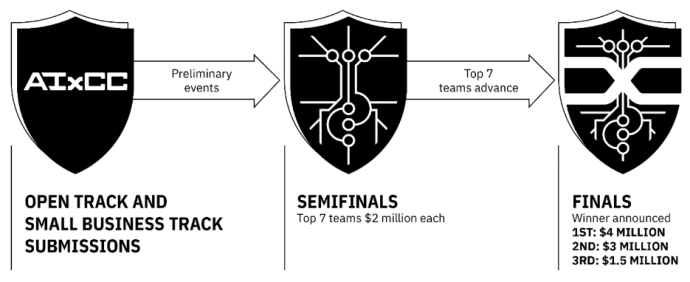
The competition has four stages:
- Registration (January–April 2024): Open and Small Business registration tracks are open for registration. After submitting their concept white papers, up to seven small businesses will be selected for a $1 million prize to fund their participation in AIxCC.
- Practice Rounds (March–July 2024): Practice and familiarization rounds allow competitors to realistically test their systems.
- Semifinals (August 2024 at DEF CON): In the first competition round, the top seven teams advance to the final round, each receiving a $2 million prize.
- Finals (August 2025 at DEF CON): In the grand finale, the top three performing CRSs receive prizes of $4 million, $3 million, and $1.5 million, respectively.

Figure 1: AIxCC events overview
The challenge projects
The challenge projects that each team’s CRS must handle are modeled after real-world software and are very diverse. Challenge problems may include source code written in Java, Rust, Go, JavaScript, TypeScript, Python, Ruby, or PHP, but at least half of them will be C/C++ programs that contain memory corruption vulnerabilities. Other types of vulnerabilities that competitors should expect to see will be drawn from MITRE’s Top 25 Most Dangerous Software Weaknesses.
Challenge problems include source code, a modifiable build process and environment, test harnesses, and a public functionality test suite. Using APIs for these resources, competing CRSs must employ various types of AI/ML and conventional program analysis techniques to discover, locate, trigger, and patch vulnerabilities in the challenge problem. To score points, the CRS must submit a PoV and PoU and may submit a patch. The PoV is an input that will trigger the vulnerability via one of the provided test harnesses. The PoU must specify which sanitizers and harnesses (i.e., vulnerability type, perhaps a CWE number) the PoV will trigger and the lines of code that make up the vulnerability.
The RFC contains a sample challenge problem that reintroduces a vulnerability that was disclosed in 2021 back into the Linux kernel. The challenge problem example provided is a single function written in C with a heap-based buffer overflow vulnerability and an accompanying sample patch. Unfortunately, this example does not come with example fuzzing harnesses, a test suite, or a build harness. DARPA is planning to release more examples with more details in the future, starting with a new example challenge problem from the Jenkins automation server.
Scoring
Each competing CRS will be given an overall score calculated as a function of four components:
- Vulnerability Discovery Score: Points are awarded for each PoV that triggers the AIxCC sanitizer specified in the accompanying PoU.
- Program Repair Score: Points are awarded if a patch accompanying the PoV/PoU prevents AIxCC sanitizers from triggering and does not break expected functionality. A small bonus is applied if the patch passes a code linter without error.
- Accuracy Multiplier: This multiplies the overall score to award CRSs with high accuracy (i.e., minimizing invalid or rejected PoVs, PoUs, and patches).
- Diversity Multiplier: This multiplies the overall score to award CRSs that handle diverse sets of CWEs and source code languages.
There are a number of intricacies involved in how the scoring algorithm combines these components. For example, successfully patching a discovered vulnerability is incentivized highly to prevent competitors from focusing solely on vulnerability discovery and ignoring patching. If you’re interested in the detailed math, please check out the RFC scoring for details.
General thoughts on AIxCC’s format RFC
In general, we think AIxCC will help significantly advance the state of the art in automated vulnerability detection and remediation. This competition format is a major step beyond the Cyber Grand Challenge in terms of realism for several reasons—namely, the challenge problems 1) are made from real-world software and vulnerabilities, 2) include source code and are compiled to real-world binary formats, and 3) come in many different source languages for many different computing stacks.
Additionally, we think the focus on AI/ML–driven CRSs for this competition will help create new research areas by encouraging new approaches to software analysis problems that conventional approaches have been unable to solve (due to fundamental limits like the halting problem).
Concerns we’ve raised in our RFC response
DARPA has solicited feedback on their scoring algorithm and exemplar challenges by releasing them as an RFC. We responded to their RFC earlier this month and highlighted several concerns that are front of mind for us as we start building our system. We hope that the coming months bring clarifications or changes to address these concerns.
Construction of challenge problems
We have two primary concerns related to the challenge problems. First, it appears that the challenges will be constructed by reinjecting previously disclosed vulnerabilities into recent versions of an open-source project. This approach, especially for vulnerabilities that have been explained in detail in blog posts, is almost certainly contained in the training data of commercial large language models (LLMs) such as ChatGPT and Claude.
Given their high bandwidth for memorization, CRSs based on these models will be unfairly advantaged when detecting and patching these vulnerabilities compared to other approaches. Combined with the fact that LLMs are known to perform significantly worse on novel instances of problems, this strongly suggests that LLM-based CRSs that score highly in AIxCC will likely struggle when used outside the competition. As a result, we recommend that DARPA not use historic vulnerabilities that were disclosed before the training epoch for partner-provided commercial models to create challenge problems for the competition.
Second, it appears that all challenge problems will be created using open-source projects that will be known to competitors in advance of the competition. This will allow teams to conduct large-scale pre-analysis and specialize their LLMs, fuzzers, and static analyzers to the known source projects and their historical vulnerabilities. These CRSs would be too specific to the competition and may not be usable on different source projects without significant manual effort to retarget the CRSs. To address this potential problem, we recommend that at least 65% of challenge problems be made for source projects that are kept secret prior to each stage of the competition.
PoU granularity
We are concerned about the potential for the scoring algorithm to reject valid PoVs/PoUs if AIxCC sanitizers are overly granular. For example, CWE-787 (out-of-bounds write), CWE-125 (out-of-bounds read), and CWE-119 (out-of-bounds buffer operation) are all listed in the MITRE top 25 weaknesses report. All three could be valid to describe a single vulnerability in a challenge problem and are cross-listed in the CWE database. If multiple sanitizers are provided for each of these CWEs but only one is considered correct, it is possible for otherwise valid submissions to be rejected for failing to properly distinguish between three very closely related sanitizers. We recommend that AIxCC sanitizers be sufficiently coarse-grained to avoid unfair penalization of submitted PoUs.
Scoring
As currently designed, performance metrics (e.g., CPU runtime, memory overhead, etc.) are not directly addressed by the competition’s areas of excellence, nor are they factored into functionality scores for patches. Performance is a critical nonfunctional software requirement and an important aspect of patch effectiveness and patch acceptability. We think it’s important for patches generated by competing CRSs to maintain the program’s performance within an acceptable threshold. Without this consideration in scoring, it is possible for teams to submit patches that are valid and correct but ultimately so nonperforming that they would not be used in a real-world scenario. We recommend the competition’s functionality score be augmented with a performance component.
What’s next?
Although we’ve raised some concerns in our RFC response, we’re very excited for the official kickoff in March and the actual competition later this year in August. Look out for our next post in this series, where we will talk about how our prior work in this area has influenced our high-level approach and discuss the technical areas of this competition we find most fascinating.