2024-1-24 13:0:44 Author: mp.weixin.qq.com(查看原文) 阅读量:3 收藏
一. 综述
来自波士顿大学、新南威尔士大学、IBM实验室的六位作者于12月19日发表了一篇名为《Can Large Language Models Identify And Reason About Security Vulnerabilities? Not Yet》的论文[1]。该文针对“LLM能否可靠地识别与安全有关的错误”进行了广泛的实验,在多达228个代码场景中,使用17种prompt方法分别测试了8个不同的LLM。
*如无特殊说明,本文中所有图表均取自原论文*
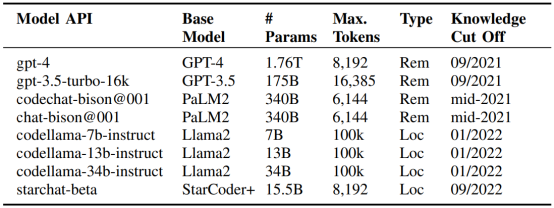
图1 论文中所测试的模型列表
作为实验结论,论文对LLM检测漏洞的能力持悲观态度,认为“即使是最先进的模型(包括PaLM2和GPT4)也显著缺乏鲁棒性”。具体包括:
1、 准确性不足:虽然最终性能受具体模型和prompt方法影响,但所有模型都表现出较高的误报率(FPR)
2、 稳定性不足:LLM的输出并不稳定,所有模型都会在多次运行测试中改变答案;
3、 可解释性不足:即使LLM正确识别了漏洞,也难以正确提供推理过程;
4、 分步推理能力不足:基于分步推理的prompt要求模型使⽤思维链(COT)推理逐步解决问题,但表现不佳;
5、 泛化能力不足:LLM未能有效检测超出它们的训练集范围的、现实场景中的漏洞。
二. 实验数据集
原论文中表示,其实验过程共使用了228组测试数据,其中:
2.1
手工编写数据48组
a) 选取8种CWE漏洞类型
b) 每个漏洞类型包含3种难度
c) 另外分为2种漏洞状态(有漏洞/无漏洞)
图2 论文中选用的8种CWE漏洞类型
2.2
真实CVE代码数据30组
a) 选取15个CVE
b) 每个CVE包含2种漏洞状态(有漏洞/修补后)
c) 缩略至不超过6144个token,以适应PaLM2的限制
图3 论文中选用的15个CVE
2.3
琐碎增强(Trivial Augmentations)84组
a) 从手工编写的数据中选取2类CWE(越界写入和SQL注入),共12个原始样本
b) 对每个样本分别进行以下7种变换方法:
i. 随机重命名函数的参数
ii. 随机重命名函数
iii. 添加随机的不可达代码
iv. 在注释中添加随即代码
v. 插入空白符
vi. 添加一个无用的函数
vii. 添加换行符
c) 意在衡量模型针对随机噪声的鲁棒性
2.4
非琐碎增强(Non-Trivial Augmentations)66组
a) 以下变换方法各12组:
i. 将变量名改为漏洞相关的关键字
ii. 将实际安全的函数名称改为“vulnerable”
iii. 将实际不安全的函数名称改为“non_vulnerable”
iv. 添加一个具有潜在风险的库函数(strcpy、strcat等)但以安全的方式使用它
b) 以下变换方法各9组:
i. 在存在漏洞的代码上添加实际无效的过滤函数
ii. 使用“#define”宏定义,其名称为安全的函数名,但实际指向不安全的函数
图4 使用“#define”宏定义,其名称为安全的函数名,但实际指向不安全的函数
三. 评估方法
3.1
运行LLM
运行参数主要控制温度值(temperature),分别取0.2和0.0进行测试。
具体prompt模板共17种,具体如下:
表1:prompt模板列表
其中,ID为“S”开头的表示单步推理、“R”开头的表示分步推理,“D”开头的会向模型提供额外的信息(如MITRE官方网站上对安全漏洞的定义)。Type中的“ZS”表示Zero-shot,“FS”表示Few-shot,“TO”表示任务导向,“RO”表示角色导向。
3.2
LLM是否在给定代码中发现漏洞
LLM有时不会给出明确的答案,所以该项的可选值包括:是、否、N/A。由于是离散分类输出,且原始样本自带分类标注,因此可以直接统计分类准确率,该输出分量的评估并不复杂。
3.3
要求LLM编写100字左右的推理过程
3.3.1 样本标注
1、 从228组样本中随机抽取48组,由包括原论文第一作者在内的三名安全专家分别编写100字左右的推理过程,互相讨论并达成共识
2、 另外180组样本由原论文第一作者自行编写。
3.3.2 相似性测度
原论文中使用三个维度进行相似性判断:
1、 Rouge-N相似度:
a) 即,将预测值和标注值均作n-gram切分,取其中重叠片段的占比作为相似性度量
b) 若Rouge-N相似度大于阈值0.34,则认为两个样本是“相似的”
2、 余弦相似度:
a) 将预测值和标注值提交到OpenAI的嵌入模型“text-similaritydavinci-001”,求两个嵌入向量的余弦作为相似性度量
b) 若余弦相似度大于阈值0.84,则认为两个样本是“相似的”
3、 GPT4一致性判断
a) 即将预测值和标注值提交到GPT-4,要求GPT-4判断两者的推理是否一致
b) 仅在GPT-4输出Yes时,认为两个样本是“相似的”
随后,若三个维度中有至少两个判断为“相似的”,则最终认定预测值是正确的。
但,原论文中似乎没有具体说明两个相似度阈值是如何确定的。
四. 评估结论
4.1
稳定性评估
即以模型默认的温度值(OpenAI默认建议0.2)将同样的输入重复运行10次,并观察模型输出结果是否发生变化。在这个评估过程中不考虑模型输出正确与否,仅评估其稳定性,结果如下:
图5:稳定性评估结果
4.2
温度值的影响评估
论文中还测试了不同温度值对模型输出准确性的影响,但这部分的实验用例较少:
图6:CWE-787(越界写入)中温度值对准确性的影响
图7:CWE-89(SQL注入)中温度值对准确性的影响
上两图中,3v表示实际存在漏洞的样本,3p表示实际已经修复漏洞的样本,Rec列表示使用模型推荐的温度值(0.2)的情况。最终,原论文认为温度值对模型输出的准确与否并没有明显影响。
原论文还表示,即使将温度值设置为0,chat-gison和GPT-4的输出仍会存在不稳定的的情况。
4.3
Prompt效果评估
在48个手工编写的数据中进行评估,其中绿色部分表示分类正确的数量、红色部分表示分类错误的数量,白圆(距离左侧的长度)表示分类和解释均正确的数量:
图8:Prompt效果
以三项指标的加权和为准,其中红框为最优Prompt。
结果看来,GPT-4以89.5%的综合准确率位居第一,但“最佳的Prompt”在不同模型中各不相同。有三个模型更喜欢角色导向的Prompt(即R系列中产生最优),而另外两个则不然(在S系列中产生最优)。
虽然原论文中没有指出,但在笔者看来,D系列的表现都不太好,因此认为额外输入关于漏洞类型描述的信息对于LLM推理而言可能帮助不大,而且还会起反作用。
4.4
漏洞种类间的差异评估
原论文中统计了各个模型在各个漏洞类型上的最佳表现,其中深绿色为正确分类漏洞代码(分类TP)的数量,浅绿色为正确分类修补后代码(分类TN)的数量,白圆为正确推理/解释漏洞代码(推理TP)的数量,黑点为正确推理/解释修补后代码(推理TN)的数量:
图9:全部模型在不同漏洞种类上的最佳表现
虽然在笔者看来并不明显,但原论文据此认为,大多数模型难以对修补后(没有漏洞)的代码进行正确分类,并导致许多误报。
这个结论与我们此前进行的其它实验类似,当时的实验认为LLM在告警评估中具有高估风险等级的倾向。
4.5
其他
原论文中还进行了很多维度的分析,本文仅提取其中关键结论如下:
1. 代码难度影响:
a) LLM通常在简单的类别中表现更好。
b) 具体而言,LLM不熟悉库函数的安全事件,也难以处理复杂的多函数多变量数据流模式。
2. 数据增强影响:
a) LLM的抗扰动能力很差。
b) 即使是微不足道的数据增强(如添加空格和换行),也会导致所有LLM得出错误的答案。
3. 真实案例的表现:
a) 与4.4中的结论一致,论文认为LLM不擅长处理现实世界中的CVE漏洞,并产生较多误报。
b) 原论文还指出,在现实场景中,Few-Shot方法并不起作用,LLM似乎难以从Prompt样例中归纳出有效的信息并将其适用于其他代码样本。
感兴趣的读者不妨去阅读原论文以了解更多信息。
五. 后记和展望
综上,与论文的标题一致,原论文认为当前的LLM在代码漏洞检测任务上并不可靠,即使是最先进的模型也一样。
但笔者对此持相反观点。使用过传统SAST工具(Fortify、CheckMarks等)的读者应该都知道,传统SAST方法的误报率非常之高,一份自动生成的代码审计报告经过人工验证后,其中真正能够构成风险的条目往往十不存一。即使是在添加了扰动(数据增强)的情况下,LLM也只产生了26%的错误,这足以证明使用LLM进行代码漏洞检测的可行性之高。
此外,原论文中还指出,目前缺少“有漏洞的代码->无漏洞的代码”的漏洞修复数据集,如果LLM能够有效地生成这些数据,将有利于相关下游任务的方法改进。
更多前沿资讯,还请继续关注绿盟科技研究通讯。
如果您发现文中描述有不当之处,还请留言指出。在此致以真诚的感谢~
参考文献
[1] Saad Ullah, Mingji Han, Saurabh Pujar, et al. Can Large Language Models Identify And Reason About Security Vulnerabilities? Not Yet[J/OL]. cs.CR, 2023, 2023, abs/2312.12575. https://doi.org/10.48550/arXiv.2312.12575.
内容编辑:创新研究院 吴复迪
责任编辑:创新研究院 舒展
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
关于我们
绿盟科技研究通讯由绿盟科技创新研究院负责运营,绿盟科技创新研究院是绿盟科技的前沿技术研究部门,包括星云实验室、天枢实验室和孵化中心。团队成员由来自清华、北大、哈工大、中科院、北邮等多所重点院校的博士和硕士组成。
绿盟科技创新研究院作为“中关村科技园区海淀园博士后工作站分站”的重要培养单位之一,与清华大学进行博士后联合培养,科研成果已涵盖各类国家课题项目、国家专利、国家标准、高水平学术论文、出版专业书籍等。
我们持续探索信息安全领域的前沿学术方向,从实践出发,结合公司资源和先进技术,实现概念级的原型系统,进而交付产品线孵化产品并创造巨大的经济价值。
长按上方二维码,即可关注我
如有侵权请联系:admin#unsafe.sh