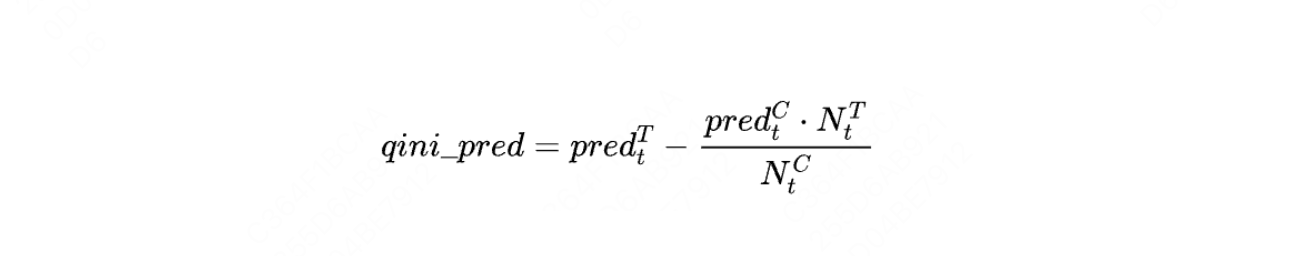
1. 业务背景
近年来,因果推断在商品定价、补贴、营销等领域得到广泛应用并取得了显著的业务效果提升,例如用户增长、活动营销等业务场景。这些领域的共性是需要“反事实推断能力”,传统机器学习算法更关注预测问题,而因果推断提供了更佳的反事实推断能力。以营销活动为例,我们不仅需要知道当前优惠券金额下,订单数是多少(预测问题),还要知道在改变金额的情况下,订单数会发生怎样的变化(反事实问题)。
常见的因果建模方法主要包含Meta-Learner、深度表征学习和Tree-Base算法三大类。其中以因果树为代表的Tree-Base算法泛化性强,适用于多种业务场景。相较于Meta-Learner,树模型建模流程简单;相较于深度表征学习,树模型特征处理和调参过程简单并且具备极强的可解释性。
开源社区涌现出了微软的EconML和DoWhy,Uber的CausalML,以及因果森林作者的grf-lab等等众多优秀开源项目,但这些项目均为单机实现,不能满足工业场景下亿级样本的模型训练、评估、解释分析。Meta-Learner和深度表征学习可以轻松借助XGBoost、LGBM、Spark MLlib、Tensorflow等开源工具支持海量数据,但是这些项目都不支持因果树相关的Tree-Base算法的分布式训练。
具体来说,XGBoost、LGBM、Spark Random Forest等树模型是为解决预测问题而提出的经典算法实现,而因果树算法引入了新的训练理论以及因果理论独有的干预变量、工具变量等概念。这意味着我们并不能通过对现有分布式树模型的简单改造,来实现因果理论下树模型的分布式训练,而是需要充分理解各类单机因果树算法的原理之后,选择合适的分布式编程范式高效地实现出来。
为了解决上述问题,美团履约平台技术部对开源项目进行了精细梳理,集各家之所长实现了一套高性能的分布式因果森林框架,在半小时内即可完成亿级样本100棵树的训练,突破了单机开源项目仅支持百万级样本的瓶颈。并经过复杂的抽象设计,最终实现通过自定义损失函数即可支持各类因果森林算法的能力,极大提升了框架的扩展性。
除此之外,美团履约平台技术部还在因果效应评估、观测数据去偏等方面建设了大量高效实用的分布式工具。本文将重点为大家分享如何设计实现一个分布式的因果森林算法,以及因果效应评估方面的经验技巧,将我们在分布式因果推断领域的一些探索和内部的实践经验分享给大家。

2. 分布式因果森林框架
因果森林算法的提出引发了Tree-Base算法应用于因果建模的研究热潮,众多学者相继在因果森林的基础上提出了多种多样的改进算法。监督学习领域的树模型有众多优秀的开源分布式实现,例如Xgboost、LightGBM、Spark Random Forest等等。
但是开源的因果树模型分布式实现基本处于空白状态。因果树算法引入了新的训练理论(比如Honesty Tree)并且因果树的分裂还依赖于干预变量、工具变量,这导致我们无法通过对现有分布式树实现做简单来更改来实现。因此,我们立足于论文,充分调研并借鉴业内优秀的开源实现,最终设计实现了一套高性能的分布式框架,并能提供统一的Serving方案。
借助这套框架,新增因果森林类算法只需要专注于损失函数设计即可,完全不必考虑分布式的工程实现。截止到目前,我们已经实现了四种因果森林算法,能够灵活支持多维连续treatment和及工具变量,半小时内即可完成亿级样本100棵树的训练。下面我们将从技术选型与框架设计、性能优化、Serving实现这几个方面为大家介绍这套框架。
2.1 技术选型与框架设计
单机树模型的工程实现可以概括为:遍历所有潜在的切分点并计算分裂指标(损失函数),取指标指标最佳的分裂点分裂,不断分裂树节点直到满足退出条件。而分布式环境下每台机器只包含部分样本,分布式环境下任何全局指标计算都会带来极大的通讯成本,因此需要选择合适的分布式架构帮助我们计算分裂指标。
因此,对于分布式因果森林框架,我们关心三个问题:第一,如何计算因果树的分裂指标(损失函数);第二,如何求潜在分裂点;第三,选用何种分布式编程架构。在此基础上进一步抽象整合,就可以实现不同树模型共用一套分布式框架的目标。
从论文出发
为了深入了解因果森林类算法,我们仔细阅读了因果森林论文以及其作者Susan Athey的另一篇在因果领域有重要影响力的《Generalized Random Forests》论文。Susan Athey认为随机森林本质上是一种自适应的最近邻算法(KNN),也就是通过对样本空间的递归划分从而找到距离该样本点最近的K个点(落入同一个叶子节点)来表示该点的值。而因果森林算法本质上是随机森林算法在因果推断领域的一种特殊应用。
因果森林和传统分类、回归森林一样采用了二叉的CART树(Classification And Regression Tree)作为基模型。与分类和归回问题相同,特征值仅用于样本划分而不参与分裂指标的计算。不同之处在于,分类和回归问题仅研究预测观测值Y,而因果建模需要研究treatment、instrumental variable等变量与观测值Y之间的关联。此外,多维连续treatment是学界的热门研究方向。因此,相较于分类和回归问题,因果推断需要在样本表示上做出相应调整。
因果森林论文提出honestyTree的概念:将样本分成growSet和predictionSet两个部分,growSet用于树的生长,predictionSet用于prediction值的计算。在论文《Generalized Random Forests》中证明了最小化子节点评估值与真实值之间的误差等价于最大化左右节点间的异质性,并对CART树的生长过程做了更加广义的抽象,将其分解成labeling step和regression step两步。Susan Athey的单机C++开源项目grf-lab中将这两种观点融合在一起,把树的生长定义为relabeling/splitting/prediction三个步骤。
综上,我们可以得出一些指导方案设计的结论:
- 因果森林本质上是CART树Bagging算法在因果建模领域的特殊应用。因此CART树相关的论文和开源项目都可以广泛借鉴。
- 不同于CART树,因果树的样本表示需要做相应抽象,根据不同算法灵活支持单维treatment多维treatment和工具变量。
- 因果树的支持honestyTree,可以将树的生长拆分为relabeling/splitting/prediction三个步骤,根据不同算法灵活实现。
Pre-sorted Algorithm Or Histogram-based Algorithm ?
主流CART树模型求分裂点的实现有两种方式,以早期XGBoost为代表的预排序算法,以LightGBM和SparkRandomForest为代表的直方图算法(目前XGBoost也提供了直方图算法的实现)。
- 预排序算法:对每一个特征的所有取值排序,依次遍历这些值计算分裂指标,取指标最佳的分裂点将节点分裂为左右子节点。
- 直方图算法:直方图的主要思想是将连续特征离散化到最大k个桶中,同时构造一个宽度为k的直方图。在遍历样本时,以离散化值为索引在直方图中累积统计量。遍历每个特征的每个分桶计算分裂指标,取指标最佳的分裂点将节点分裂为左右子节点。


相较于预排序的实现,直方图算法的时间复杂度由$O(data*features)$降低为$O(bin*features)$,同时离散化后的特征内存占用更低,并且可以通过直方图作差的方式(父节点直方图减去左节点直方图)进一步降低计算量。受限于篇幅,预排序算法与直方图算法的差异这里不再赘述。最终我们选择了直方图算法方案,这也意味着需要在框架中采样计算直方图和特征离散化的环节。
AllReduce Or MapReduce ?
工业界主流的分布式机器学习架构有AllReduce、ParameterServer、MapReduce三种,其中AllReduce性能最高(ParameterServer架构也可以和AllReduce结合,为了方便讨论,这里不再细究)。
| 架构 | 实现 | 性能 | 代表框架 |
|---|---|---|---|
| AllReduce | C++ | 最优 | XGBoost、微软LightGBM、谷歌Tensorflow |
| ParameterServer | C++ | 居中 | 谷歌Tensorflow (PS模式)、Tencent Angel,主要应用在深度学习领域 |
| MapReduce | Java/Scala | 一般 | Spark MLlib、H2O (Uplift Random Forest) |
因为XGBoost内建了一个AllReduce框架RABIT可以直接复用,因此我们迅速拟定了两个调研方向——复用XGBoost的AllReduce高性能实现和Spark MapReduce实现。
| 方案 | 架构 | 明细 | 性能 | 技术栈 | 开发难度 | 测试难度 | 支持的样本量级 |
|---|---|---|---|---|---|---|---|
| 方案1 | AllReduce | XGB RABIT + Spark | 高 | C++和Scala | 高 | 高 | 百亿 |
| 方案2 | MapReduce | Spark | 一般 | Scala/Java | 较高 | 较高 | 十亿 |
由于履约使用的样本量在几千万级别,综合考虑开发测试成本和训练性能后,我们最终选择了MapReduce方案。
框架设计
综合上文的分析,我们为分布式因果森林框架设计了4个模块:

- 训练入口与参数模块:抽象出Abstract CFEstimator用来整合树模型的通用参数,新增算法继承此类后添加专属参数即可作为对应算法的训练入口。
- 样本转换模块:负责采样构建直方图与特征离散化,上文中单维treatment多维treatment、工具变量、观测值y的转换也封装在此模块中。
- 森林生长模块:框架的核心模块,使用MapReduce实现。包含随机森林需要的树采样、特征采样,同时实现honesty。抽象出relabeling/splitting/predcition这几个接口,不同的算法按需实现树的生长逻辑,并以此为基石抽象损失函数接口。
- 模型保存和serving模块:抽象出统一的树模型保存和加载方案。
2.2 性能优化
在选定MapReduce+直方图的方案后,我们迅速将目光锁定在同样使用直方图算法的Spark RandomForest算法上(以下简称SparkRF)。我们在SparkRF上快速实现了一版分布式因果森林框架,并进一步实现了Generalized Causal Forests算法。
但是测试过程中我们发现,随着总节点数的增加,跨节点通信量(也就是Shuffle)剧增,同时还非常容易溢出。为了支持更大规模的模型训练,我们从跨节点通信、内存占用、计算复杂度、剪枝以及CPU缓存命中优化等多个方面优化了整个框架。为了讲清楚我们优化逻辑,大家先来看看SparkRF是如何实现的。
SparkRF的实现
SparkRF整个实现过程可以概括为如下几个步骤:
(1)将全量样本离散化并cache到内存,这一步包含三部分:
- 采样collect到driver为每个特征等距分桶,得到潜在切分点split。
- 使用潜在切分点split,将每个样本的特征离散化,此时特征值从double被转换成int。
- 根据树采样比例,为每条样本生成标记数组(由int数组实现),标记这条样本用于哪棵树的生长。
(2)树的生长
- 将整个森林看做一张图,采用深度优先搜索待分裂的节点,一次迭代一组节点,由maxMemoryInMB参数控制节点数。
- 根据样本的标记数组,计算每个样本在每个节点的每个split下的直方图(统计信息)。
- 通过reduceByKey算子,将同一个待分裂节点的所有split下的直方图汇总到同一个worker中。
- 将待分裂节点的每个切分点直方图积分,例如feature0有3个切分点[a,b,c],积分后为[a, a+b, a+b+c],使用直方图作差,计算左右子节点增益,获取最佳切分点。
- 将待分裂节点的最佳切分点collect回driver,完成森林的生长。
- 使用rdd cache记录样本所属节点id(由useNodeIdCache参数控制)或广播模型。
- 持续迭代直到达成退出条件。
可以看到,Spark的实现除了直方图,还有不少精妙的地方。例如在每次可训练的总结点数有限的情况下,深度优先搜索相较于广度优先搜索更倾向于快速完成单棵树的训练,从而减少后续训练需要广播的树模型。篇幅所限,下面将主要为大家介绍分布式因果森林框架在内存占用方面的优化。
减少Cache体积
从上文可以看出,SparkRF使用int来表示最大分桶个数,而lightGBM使用无符号byte来存储,支持最多256个分桶。我们认为128个分桶足以支撑因果森林的业务需要,所以使用了有符号byte来表示分桶,相比int内存占用减少至1/4。
前文中提到,SparkRF为每个样本创建了一个标记数组。例如训练一个2棵树的森林,这个标记数组为[4,0],这表示此样本在tree0有放回采样4次,在tree1未被使用。此外,框架需要支持honestyTree,也就意味着需要另一个标记数组记录样本在growSet还是predictionSet。考虑到无放回采样足以覆盖绝大部分场景,并且为了不引入第二个标记数组,我们最终选择了BitSet实现。每棵树最多使用2个bit,1个bit表示是否是该树的样本,1个bit表示是否是honesty样本。当关闭honesty或者不使用下采样时,每棵树只需要1个bit,内存占用最多减少至1/32。
支持更大模型广播
上文中提到,SparkRF每一轮迭代调用reduceByKey之前都需要计算出哪些样本属于待分裂的节点,Spark通过useNodeIdCache参数提供了两种策略:
- 策略一:每次迭代将树模型跟随闭包广播到各个worker节点通过predict获取节点id。
- 策略二:使用RDD[Array[Int]]类型来缓存当前样本隶属于每棵树的哪个节点(例如训练100棵树,则创建长度为100的int数组,每一个元素记录了此条样本在对应下标的树模型中的叶节点编号)。
从源代码中我们发现,策略二每一轮迭代都会卸载上一轮持久化的nodeIdCache,再创建一个新的nodeIdCache持久化到内存。以1亿条样本100棵树的森林举例,每一轮迭代就是1亿个长度为100的int数组的创建与垃圾回收。实际测试中我们也发现策略二的效率不如方案一高。那么策略一又如何呢?
SparkRF在每一轮迭代中能够训练的最大节点数由maxMemoryInMB控制,我们希望通过增大这个参数来减少迭代次数。但随着树或树深的增加,往往陷入增大该参数就导致树模型广播到worker溢出的尴尬境地。经过对SparkRF源码分析,我们发现每个LearningNode都会存储当前节点、左子节点、右子节点的直方图,最终实现在一套通用框架下计算出每个节点的增益、纯度、预测值等等属性,但这导致了3倍的内存占用。
考虑到因果森林honestyTree原则,叶节点prediction值的计算使用predictionSet,因此生长过程中每个节点全都带着growSet的直方图是完全没有意义的。因此我们优化了树的生长逻辑,每个节点仅保留自身的直方图,对于已分裂的节点则清除直方图。以二叉满树为例,叶节点约占整棵树节点的1/2,结合直方图从3倍冗余到1倍存储,这一优化使树模型直方图的内存占用下降到原本的1/6,极大降低了模型体积。
BenchMark
经过一系列优化,最终实现了百棵树亿级样本小时级训练的目标。
| 样本量 | 特征数量 | 树棵树 | 最大树深 | 资源配置 | Generalized Causal Forest算法 | Continuous Causal Forest算法 |
|---|---|---|---|---|---|---|
| 1亿 | 127 | 100 | 8 | 400*(7core16g) | 29min | 17min |
备注:不同森林算法的复杂度不同,跨节点通讯量不同,总耗时会存在明显的差异。
2.3 Serving实现
因果森林本质上是随机森林算法的变种,由一棵棵彼此独立的二叉因果树构成,每棵树由innerNode和leafNode构成。其prediction的逻辑非常简单,每棵因果树单独predict获取leafOutput向量,森林中所有树预估的leafOutput向量求均值即可得到森林的输出值。因此,整个树模型的结构其实非常清晰,innerNode存储特征split信息,leafNode存储输出向量。除此之外还包含gain、impurity、count等属性用于计算特征重要性。
模型serving除了性能还需要考虑模型离线存储体积、模型的内存占用、模型字段的扩展性。结合因果树的特点,就需要特别注意leafOutput向量的实现。以下表中的场景为例,使用float数组大约就需要500*409640 4 byte / 1024/ 1024 = 312.5mb,而List则需要约4倍内存,正因如此我们快速放弃了简单快捷的Protobuff方案。
| 树 | 树深 | 满树节点数 | 满树叶节点数 | 叶节点统计指标长度 |
|---|---|---|---|---|
| 500 | 12 | 8191 | 4096 | 40(例如ccf算法20维treatment下的输出) |
为什么要重视模型字段的扩展性呢?这是因为离线模型训练追求快速迭代而在线Serving追求稳定性。模型的扩展性好,不仅可以轻松做到新版本服务向下兼容老模型,还可以做到在不使用新特性的情况下,老版本服务向上兼容新模型,从而减少在线服务更新发版的次数。综合考虑以上因素以及对Spark的兼容性和对java serving生态的兼容性,我们设计了如下方案。
- 使用parquet文件格式存储模型文件。
- 字段扩展性:好,读取类似KV,模型文件可以随意扩展而不影响线上服务
- 模型内存体积:好,相较于protobuf,可以逐行读取转换为float数组而非Float List
- 模型存储体积:好,采用snappy算法压缩
- 字段平铺的方式存储树模型。相较于SparkRF的采用tree-node嵌套的方式,更利于字段扩展。虽然会带treeId等个别字段的冗余存储,但是列存储的压缩效率非常高,影响很小。
- 提供独立jar包cos-serving实现模型加载和prediction的功能,实现了离线模型训练升级而在线服务可以不升级的目标。
我们将离线模型的保存和加载逻辑抽象封装到了因果森林框架中,进一步增强了因果森林框架的扩展性,开发新森林算法时专注于将论文中树的生长逻辑实现即可。
3. 分布式因果效应评估
业内常见的因果效应评估手段主要评估ITE的序关系,例如qini score和auuc。但是存在如下三方面不足:
- 缺乏对数据和模型无偏性的校验
- 缺乏因果效应量级关系的评估,qini-score和auuc只能反应弹性的序关系
- 开源因果评估工具都是单机实现,仅支持百万级样本的计算
下文将为大家一一进行说明。
3.1 无偏性校验
无偏性校验分为数据无偏性和模型无偏性。
数据无偏性校验可以通过X⊥T验证。首先可以训练一个X->T的倾向性得分模型,如果倾向性得分模型的auc在0.5附近则说明X无法正确地预测T,也就是说X⊥T,此时数据无偏。例如,使用了post-treatmen特征会导致特征穿越,最终导致数据是有偏的,这时候使用X⊥T的校验工具可以快速帮我们排查出这一类问题。
模型无偏性校验使用ITE⊥T验证。首先用训练好的弹性模型在随机实验数据上预测ITE,接着对样本按照ITE升序排列后等频分桶,计算每个ITE分桶下实验组样本占比(下图的trtRatio曲线)。理想情况下,每个ITE分桶中实验组样本占比应该和随机试验中实验组样本占比一致,此时ITE正交于treatment。比如,随机实验中实验组比对照组为1比1,那么trtRatio就应该在1/2附近浮动。如果trtRatio比例不符合预期,我们就可以进一步去排查模型结构的问题。这项工具更是作为标准测试组件融入到分布式因果森林早期的开发过程中。


3.2 因果效应量级关系评估
因果效应的序关系和量级关系同样重要,只是将弹性的序关系学习准确而没有将弹性的量级关系学习准确,决策者无法预估该treatment对用户的影响程度。例如,将量级错误的弹性应用到运筹优化决策中,可能会导致无法满足重要约束从而无法求得可行解。针对弹性量级无法评估的问题,我们在原有的qini_curve基础上增加了qini_pred_curve_counterfactual和qini_pred_curve。
qini_curve及其扩展
qini_pred_curve_counterfactual:将每个样本按照模型预测的ITE降序排列,按照如下公式依次计算前t个样本的反事实qini_pred即可得到曲线。

- $pred_ite_t$ 代表前t个的样本ITE累加。
- $N_{t}^{T}$ 代表前t个样本中treatment组样本数量。
- $N_{t}^{C}$ 代表前t个样本中control组样本数量。
通过比较qini_pred_curve_counterfactual和qini_curve这两条曲线的重合程度和右端点纵坐标,我们可以观察出ITE的预估量级和真实量级是否一致。
qini_pred_curve:每个样本按照模型预测的ITE降序排列,按照如下公式依次计算前t个样本的qini_pred即可得到曲线。

- $pred_{t}^{T}$ 代表前t个的样本中treatment组样本预估outcome的累加。
- $pred_{t}^{C}$ 代表前t个样本中control组样本预估outcome的累加。
qini_pred_curve和qini_pred_curve_counterfactual差异越大,模型偏差越大,也就是ITE与T不正交。我们以下图的案例来说明这三条曲线。


根据这些曲线的形状、覆盖面积、重合程度,我们可以得到如下的判断:
- 如果数据无偏,那么qini_pred_curve_counterfactual会和qini_pred_curve重合,反之则表示数据有偏,即ITE不独立于T。
- qini_pred_curve_counterfactual和qini_curve的右端点纵轴的差距,代表了弹性预估的量级和弹性真实的量级存的差距。
- label曲线的qini score>0.5,也就是label曲线有明显向下的趋势时,存在过拟合现象,即学到了负弹性。
- 如果弹性模型对于弹性序关系和弹性量级关系学习得非常准确,那么三条曲线会几乎重合在一起。
avgITE和ATE的对比
上文中提到的三项指标都是累计因果效应的评估,我们还想更有针对性地观察每个弹性分桶下预估因果效应和真实因果效应量级的差异,所以开发了avgITE和CATE的对比工具。
同样将样本按照模型预测的ITE降序排列,然后等频分桶,统计每个分桶内预估ITE的均值(下图的avgITE曲线)和CATE值(下图的cate曲线)。对比avgITE和CATE,可以评估出真实因果效应和预估因果效应量级的差异。
$$ avgITE = E(pred_y(X_i,T_i=1) - pred_y(X_i,T_i=0)) $$
$$ CATE = E(Y_i|T=1) - E(Y_i|T=0) $$

3.3 分布式评估体系
早期我们也使用了pandas实现的单机评估算法,当样本量增加到400w条以上时遇到了严重的单机瓶颈。为此,我们对上述评估指标全部做了分布式改造。排序类指标的实现有分桶积分和逐条积分两种实现思路。考虑到逐条积分会有更高的精度,最终选择了分布式环境下逐条积分的方案。
不仅如此,我们还使用Spark实现了带权重的分布式的因果效应评估,能够支持十亿样本的评估。此外我们还融入了评估预估y与观测值Y之间的差异的指标,包括mae/mse/rmse,并将这些指标封装到二元因果效应评估组件中。由于我们实现的部分因果森林算法能够输出多元treatment下预估的y,因此我们还进一步封装了多元因果效应(拆分成多个二元因果效应)评估功能。

4. 总结
经过两年持续迭代,我们实现的分布式因果推断工具包已经发展成集模型训练、评估、去偏、Serving于一身的综合型因果工具包。我们内部为这个项目命名为Causal On Spark,简称COS。目前这个项目也已经全部集成到图灵机器学习平台中。将来有机会我们会再次为大家分享美团履约技术团队在分布式因果推断领域的探索和实践经验。
5. 本文作者
立煌、子青、郑宸、琦帆、兆军,均来自美团到家事业群/履约平台技术部。
6. 参考资料
- [1] Wager S, Athey S. Estimation and inference of heterogeneous treatment effects using random forests[J]. Journal of the American Statistical Association, 2018, 113(523): 1228-1242.
- [2] Athey S, Tibshirani J, Wager S. Generalized random forests[J]. The Annals of Statistics, 2019, 47(2): 1148-1178.
- [3] Li, G., Chen, Q., & Usunier, N. (2017). LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS 2017), 3146-3154.
- [4] Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘16), 785-794.
- [5] 微软亚洲研究院:《开源 | LightGBM:三天内收获GitHub 1000 星》.
- [6] https://grf-labs.github.io/grf/index.html.
- [7] https://github.com/uber/causalml.
- [8] https://github.com/apache/spark.
如有侵权请联系:admin#unsafe.sh