2024-1-29 10:39:24 Author: mp.weixin.qq.com(查看原文) 阅读量:6 收藏
近期,SIGGRAPH Asia 2023(The 16th ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia)会议在澳大利亚悉尼举办。来自火山引擎多媒体实验室三维视频团队的论文成功入选、并在大会上做展示汇报:
Live4D: A Real-time Capture System for Streamable Volumetric Video (https://dl.acm.org/doi/10.1145/3610543.3626178)
该论文介绍了一种可传输的实时体积视频解决方案:Live4D。该技术利用了深度学习和计算机视觉技术,通过将多个摄像机的图像进行同步处理,重建出捕获对象带有纹理信息的网格模型,将其进行压缩编码传输后分发给各个客户端进行渲染显示。
Live4D可以根据应用场景和精度需求配置不同数量和位置的双目RGB相机,能以更低的成本实现体积捕获系统,并能够实时地将重建出的数据发送给用户;同时还支持互动和沉浸式体验,用户可以通过与视频进行互动,获得更加身临其境的体验。该技术在全息通信、虚拟现实、增强现实和远程教育等领域具有广泛的应用前景。
技术挑战
体积视频可以看做是传统视频的升级。传统视频播放每秒30帧的画面,而体积视频则播放每秒30个3D模型。因此,观众可以自由选择从任意视角、任意距离(6 degrees of freedom,即6Dof)观看体积视频中的内容;可以在手机或电脑屏幕上观看、也可以通过VR/AR眼镜观看。
当前已有的一些体积视频方案,其场景设置需要上百个相机同时捕获数据,成本高昂且大部分实时重建方案效果仍有较大瑕疵。
Live4D解决方案
三维数据的获取
在实验配置中,技术团队使用了10组双目RGB相机来同步捕获全身数据,以此来获取实验数据。为了获取相机视角下的深度信息,团队采用了基于深度学习的双目立体匹配方法,这是目前常用的方法之一。由于现有的方法在耗时和质量上不能完全满足技术团队的要求,团队基于RAFT-Stereo[1] 对其进行了蒸馏训练,以此来获取实时推理中更准确的深度。同时,技术团队还利用TensorRT和自定义的CUDA算子对整个框架进行加速,以此来达到所需的时间和精度。
为了进一步提升人脸区域的深度精度,在双目立体匹配中,技术团队设计了一种基于强化感兴趣区域 (Region of Interest, ROI)的方法来更精细地获取该区域的深度信息,并将其与原先图像进行融合,以得到质量更高的深度图。技术团队还设计了背景抠图和深度置信度检测的方法,将背景和不可信的深度进行过滤,以此来得到最终的深度图,并将其与对应的RGB一起送入后续的重建流程。
| 无ROI | ||
|---|---|---|
| 强化ROI |
TSDF重建与补全
获取多个视角的RGB和深度图后,技术团队在空间中构建一个容器,离散化分割成更小的体素。为了获取更精细的结果,需要大量且细小的体素,但身体等非ROI区域会浪费较多空间和计算资源。因此,团队采取了层级式的数据结构,让ROI区域有更细粒度的体素分布,而在其他区域每个体素可以有更大的物理尺寸。这样可以在减少资源消耗的情况下增加ROI区域的细节表达。
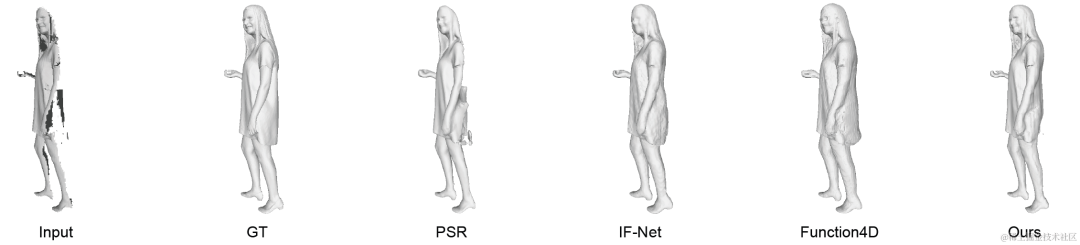
技术团队将多个视角的深度图反投到容器中,将其转换为截断符号距离,并通过多视角融合和几何一致性校验等方式,将这些深度图转换为基于截断符号距离的表示,即截断符号距离场(Truncated Signed Distance Field, TSDF)。由于视角稀疏、观测模型存在自遮挡等问题,重建出的TSDF场存在很多缺失。因此,技术团队提出了一种基于TSDF Volume的补全方法,利用在构造的数据集中预训练好的三维深度神经网络,快速地对缺失的区域进行补全。相比于其他基于Occupancy的方法,该团队的方法拥有更好的补全效果,并且相比于Function4D[2] 等提取图片信息处理的方案来说,该团队提出的方法速度也有所提升。
非刚性追踪
体积视频和视频一样,也需要追求其时域稳定性。由于体积视频每一帧实际上是一个包含贴图的三维网格模型,因此技术团队利用非刚性追踪 (Non-Rigid Tracking) 的方法来保持三角形网格在时序上的一致性。
技术团队基于嵌入形变关键点(Embedded Deformation Nodes (EDNodes))[3] 来表达重建物体表面整体的形变场(deformation field)。整个计算过程通过在GPU上使用LM(Levenberg-Marquard)算法来求解局部ICP问题来高效地计算。利用形变场,技术团队将每个体素拆分成的四面体 (Tetrahedra) 栅格,进行时域上的TSDF场的混合,来完成时域的均值滤波,使得隐表面重建在时域稳定。
另一个问题是如Fusion4D[4] 等tracking方法在前后帧运动差距过大时会出现tracking失败的情况,而出现这种情况会导致最终重建出的三角形网格有非常严重的错误。具体来说,技术团队会评估变形后的TSDF场与补全后的TSDF场之间的每个体素对齐误差,对于未对齐的voxel认为其是追踪失败的部份,对于这些voxel,团队更信赖补全的结果而不是tracking的结果。用这种融合方式,对于上述提到的运动差距过大导致追踪失败的场景也能有较好的结果。
纹理生成
纹理生成需要解决两个问题,一个是计算出网格模型表面任意一点的颜色;另外就是计算出三维网格到二维图像的映射,将计算出的颜色存放在二维图像上便于传输与图形管线的渲染。
首先是计算网格模型表面的颜色。技术团队使用多视图混合算法来计算纹理,综合考虑着色边界及法线方向来设计了一种混合权重,消除了多视角混合中的色差、接缝等纹理生成质量的问题。
同时技术团队设计了一个可并行的高效重参数化算法,通过对球面采样来预设正交投影方向,重建模型执行深度剥离(depth peeling)算法来划分可视层级。通过投影方向和可视层级来标记面片所属的标签。对所有面片的所有候选标签执行图割(Graph-cut)算法来划分网格模型表面的连通域。团队对网格模型构建半边结构,并实现并行带环信念传播(Loopy blief propagation)算法来优化求得近似最优解。对于所有连通域,技术团队使用平面重参数方法并将其映射并排列得到最终的纹理贴图。
压缩及传输
直接重建出的网格点面数量巨大,可达百万面片, 为了便于网络传输,减少带宽占用,需要对三维重建结果进行简化和压缩。除了简化的时候尽量保持原有的几何特征要求以外,在当前场景下,对简化算法的实时性,脸部等ROI区域的几何特征保持都有着要求。
团队开发了一套带ROI信息的GPU简化算法, 并行取多组边评估其二次方度量误差,选出每组中误差最小的边进行坍缩。同时提高ROI区域内的边的误差等级以减少ROI区域的简化损失。 Draco&H265压缩传输,网格信息同步于SEI中
采用Draco[5] ,利用连通性、量化、熵编码等手段,进一步对简化的mesh的面和点的信息压缩成二进制流。纹理贴图则采用H.265进行图像编码。技术团队将同步的网格信息存放在视频流的SEI中,复用现在的RTC管线就可以完成三维数据的传输。
| 帧率 | 整体带宽 | Mesh带宽 | 纹理带宽 | 算法延时 |
|---|---|---|---|---|
| ~30fps | 15~20Mbps | ~12Mbps | ~8Mbps | ~100ms |
应用落地和展望
该技术方案支持多种终端设备实时观看,有着广泛的落地前景,如基于3D电视实现全息通信,提升远程办公、远程交流的效率与沉浸感;如自由视角直播,加强主播与观众的联系,创造各种互动玩法;在文娱、教育等场景中也提供了新的媒体形式。
自由视角直播
全息通信
关于火山引擎多媒体实验室
火山引擎多媒体实验室是字节跳动旗下的研究团队,致力于探索多媒体领域的前沿技术,参与国际标准化工作,其众多创新算法及软硬件解决方案已经广泛应用在抖音、西瓜视频等产品的多媒体业务,并向火山引擎的企业级客户提供技术服务。实验室成立以来,多篇论文入选国际顶会和旗舰期刊,并获得数项国际级技术赛事冠军、行业创新奖及最佳论文奖。
Reference
[1] RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching, 3DV 2021
[2] Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors, CVPR 2021
[3] Embedded Deformation for Shape Manipulation, SIGGRAPH 2007
[4] Fusion4D: Real-time Performance Capture of Challenging Scenes, ToG 2016
[5] Draco, https://github.com/google/draco
如有侵权请联系:admin#unsafe.sh