作为字节跳动在离线混部场景中最核心的调度系统,Gödel 提供丰富的资源 QoS 管理能力,可以统一调度在线和离线应用,极大提升资源利用率。
自 2014 年开源以来,Kubernetes 迅速成为容器编排领域内的事实标准,字节跳动基础架构团队也早早确定了以 Kubernetes 为底座构建私有云平台。
在过去的几年里,随着字节跳动各业务线的高速发展,公司内部的业务种类也越来越丰富,包括微服务、推广搜(推荐/广告/搜索)、机器学习与大数据、存储等,支撑业务发展所需的计算资源体量也在飞速膨胀。
早期字节跳动的在线业务和离线业务有独立的资源池,业务之间采用分池管理。为了应对重要节日和重大活动时在线业务请求的爆炸性增长,研发团队往往要提前做预案,将部分离线业务的资源拆借到在线业务的资源池中。
虽然这种方法可以应对一时之需,但不同资源池之间的资源拆借流程长、操作复杂、效率很低。同时,独立的资源池会导致在离线业务之间混部成本很高,资源利用率提升的天花板也非常有限。所以,基础架构团队希望能使用同一套系统来统一调度和管理在离线业务,实现资源并池,在提升利用率和资源弹性的同时,优化业务成本和体验,降低运维压力。
字节跳动在离线混部统一调度
增强 Kubernetes Default Scheduler
自 2018 年起大规模使用 Kubernetes 之后,字节跳动一直在优化 Kubernetes 各个组件的功能和性能。随着 2019 年推广搜业务的容器化,原生 Kubernetes 调度器逐渐无法满足业务发展的需求——
功能上,我们需要更细粒度的资源调度能力,更灵活的抢占策略;性能上,原生 Kubernetes default Scheduler 在 5000 节点的集群规模下,调度吞吐只能勉强达到 10 Pods/s,经常造成业务升级卡单,远远无法满足要求。
基于此,我们对 Kubernetes Default Scheduler 做了比较大的优化,主要如下:
【功能】扩展非原生资源调度能力,支持内存带宽,网络带宽等多种资源调度;
【功能】支持微拓扑调度;
【功能】重构抢占实现,提供抢占框架,支持插件化扩展抢占策略能力。
【性能】优化 Scheduler cache 到 Snapshot 数据同步实现,抽象,拆分数据存储,进一步贯彻“增量更新”理念;
【性能】调度结果缓存,降低重复计算,提高效率;
【性能】抢占实现优化,重新组织抢占相关数据结构,抢占过程中及时剪枝,降低无效计算量。
通过上述一系列的优化,我们很好地支持了字节跳动内部的推广搜业务容器化项目:调度吞吐相比原生调度器提升了几十倍;在一万节点规模的生产集群中,调度吞吐可以稳定到达 300 Pods/s。
Gödel Scheduler
从 2020 年开始,字节跳动启动在离线融合项目,希望可以通过并池进一步提高资源利用率,同时提升资源流转效率、降低运维成本。
在项目早期,基础架构团队就计划用一套调度系统管理在离线业务,真正做到统一调度。由于离线业务的调度需求比较复杂,与在线业务差别比较大,吞吐要求也很高;加上 Kubernetes 原生调度器是基于 Pod 调度,对更上一级 “Job” 级别的调度语义支持能力有限;同时由于原生调度器是单体调度器,性能优化的天花板也较低,比较难满足部分批式计算任务的需求——我们决定基于 Kubernetes 系统自研分布式调度器:Gödel Scheduler。
Gödel Scheduler 是一个能统一调度在线和离线业务的分布式调度器,能在满足在离线业务功能和性能需求的前提下,提供良好的扩展性和调度质量。
Gödel Scheduler 具备如下主要特点:
基于 K8s Scheduler,结合乐观并发思想,把最耗时的应用到节点匹配(filtering and scoring)操作放在 scheduler 组件,可以并发执行,提高大规模集群调度吞吐;
两层调度语义抽象(Unit 和 Pod)和二级调度框架实现:提供更灵活的“批”调度能力,更好支持离线业务的同时,可以进一步提高调度吞吐和提升系统扩展性 (扩展后的框架可以更好地处理一些特殊场景);
丰富的功能和优秀的性能,满足在线,离线(批,流)和训练等业务需求,真正做到统一调度;
兼容 Kubernetes 生态,可以替换 K8s Scheduler;
由于性能以及架构优化,在 framework interface 上与 K8s Scheduler 不完全一样,但扩展性不受影响,也可以像 Kubernetes 一样实现 scheduling plugin;
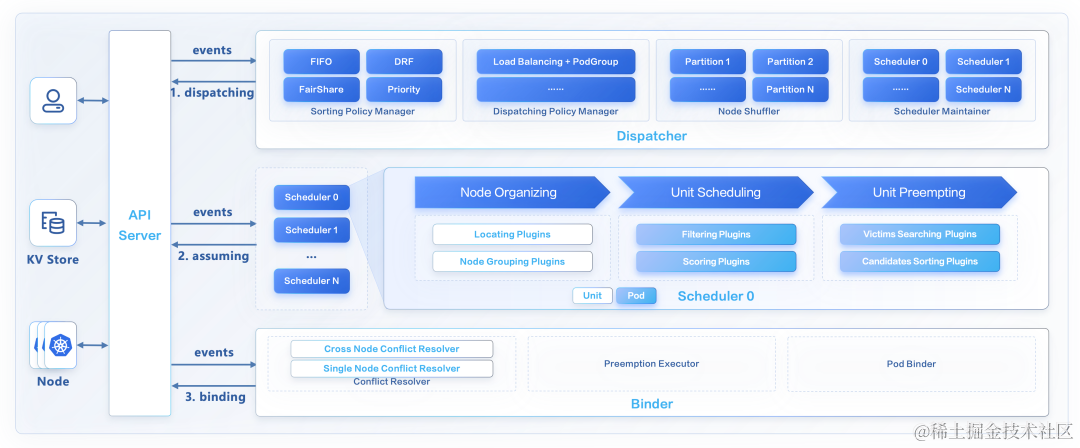
Gödel Scheduler 的架构如下图所示:
可以看到,Gödel Scheduler 由三个组件组成:Dispatcher、Scheduler 和 Binder。其中,Scheduler 组件是多实例,乐观并发调度, Dispatcher 和 Binder 则是单实例。
Dispatcher
Dispatcher 主要负责应用排队,应用分发,节点分区等工作。它主要由几个部分构成:Sorting Policy Manager、Dispatching Policy Manager、Node Shuffler、Scheduler Maintainer 和 Reconciler。其中:
Sort Policy Manager:主要负责对应用进行排队,现在实现了 FIFO, DRF/FairShare (没上线生产环境) 排队策略,未来会添加更多排队策略,如:priority value based 等;
Dispatching Policy Manager:主要负责分发应用到不同的 Scheduler 实例,现阶段是默认策略:LoadBalance,未来会增强该功能,做成插件化配置模式;
Node Shuffler:主要负责基于 Scheduler 实例个数,对集群节点进行 Partition 分组,每个节点在一个 Partition 里面,每个 Scheduler 实例对应一个 Partition,Scheduler 调度的时候会优先选择自己 Partition 节点,没有合适的情况下,才会去找其他 Partition 的节点。如果 Node 增删或者 Scheduler 个数变化,会基于实际情况重新分配节点;Partition 规则现在是基于 Scheduler 个数平均分配,未来会增强,Partition 策略可配置;
Scheduler Maintainer:主要负责对 Scheduler 实例状态进行维护,包括 Scheduler 实例健康状况、负载情况、Partition 节点数等;
Reconciler:主要负责周期性的检查 Pod、Node、Scheduler、SchedulingUnit 等状态,修正错误状态,查漏补缺。
Scheduler
Scheduler 主要负责为应用做出具体的调度和抢占决策,但是不真正执行(执行者是 Binder)。它由两级框架组成:Unit scheduling framework 和 Pod scheduling framework。整个调度过程主要分为三大部分:Node Organizing、Unit Scheduling 和 Unit Preempting。
Node Organizing:基于一些规则过滤节点减少后面流程计算量,以及为节点进行排序,为了更快调度上或者获得更好的调度质量。主要有两类插件:
Locating plugins:基于应用,过滤掉不符合要求节点,比如:Local PV,DaemonSet Pods,Resource Reservation, Rescheduling 等,共同点是:可以基于应用信息,过滤掉大部分节点,减少后面流程计算量,提升调度吞吐;
Node Grouping plugins:为通过 Locating plugins 的节点进行分组,比如:基于节点剩余资源量进行分组,或者基于 Job level affinity 里面的拓扑信息进行节点分组等,为的是能更快调度上或者获得更好的调度质量。
Unit scheduling:基于应用请求,对通过 Node Organizing plugins 的节点进行匹配筛选和打分,类似 K8s Scheduler framework,Unit scheduling 阶段也有两类插件:
Filtering plugins:基于应用请求,过滤掉不符合要求的节点;
Scoring plugins:对上面筛选出来的节点进行打分,选出最合适的节点。
Unit Preempting:如果 Unit scheduling 阶段没有合适的节点直接调度,则会进入抢占阶段,该阶段会尝试为待调度应用去抢占正在运行的应用实例,看是否有合适节点可以摆放。该阶段也有两类插件:
Victim Searching:遍历集群节点,尝试搜索 victims (被抢占应用),看是否能找到节点和 victims;
Candidates Sorting:如果上面步骤找到了合适的节点和 victims,则会为这些 victims 进行排序(节点粒度),选出最合适的节点和 victims。
Binder
Binder 主要负责乐观冲突检查,执行具体的抢占操作(删除 victims),进行应用绑定前的准备工作,比如动态创建存储卷等,以及最终执行绑定操作。它主要由 ConflictResolver、PreemptionOperator 和 UnitBinder 三部分组成。
ConflictResolver:主要负责并发冲突检查,一旦发现冲突,立即打回,重新调度。Conflict resolver 有两大类:Cross node conflict resolver 以及 Single node conflict resolver。
Cross node conflict resolver: 负责检查跨节点冲突,比如:某个拓扑域调度限制是否仍然能满足等,由于该节点跨节点,Binder 必须串行执行;
Single node conflict resolver: 单节点内冲突检查,比如:节点资源是否仍然足够等,该节点检查的逻辑限制在节点内部,所以不同节点的检查可以并发执行(unit 内 pods 调度到不同节点)。
PreemptionOperator:如果没有冲突,同时应用需要抢占,则执行抢占操作,删除 victims,等待最终调度;
UnitBinder:主要负责绑定前准备工作,比如:创建 volume 等,以及执行真正的绑定操作。
现在的版本,Binder 里面还集成了一个 PodGroup controller 实现,负责维护 PodGroup 的状态以及生命周期,后期会从 Binder 里面移除,独立成一个 Controller。
落地成果与 Roadmap
在过去两年里,Gödel Scheduler 已在字节跳动内部大规模落地,提供丰富的调度语义和功能,包括但不限于 Gang、Job level affinity、微拓扑调度、丰富的排队策略、抢占策略以及调度策略等,它高效稳定地支撑着抖音、今日头条等内部多种复杂业务的运行。
除了架构优化以外,我们还基于以前优化 Kubernetes 原生调度器的经验,对 Gödel Scheduler 的实现进行了更深度的性能优化。结合内部优化过的 Kubernetes 系统,Gödel 调度器单分片吞吐可达 2000+ Pods/s, 多分片可达 5000+ Pods/s。基于此,我们也在不断提升单集群规模,目前字节跳动内部最大的线上单集群规模已经达到20000+ 节点、100w+ Pods。
经过内部多年反复验证,目前 Gödel 系统已达相对稳定状态。2023 年,云计算领域顶会 SoCC 接受了相关论文 Gödel: Unified Large-Scale Resource Management and Scheduling at ByteDance,并邀请研发团队在现场做了报告。(查看论文:https://dl.acm.org/doi/10.1145/3620678.3624663)
为了更好地回馈开源社区,我们也决定开源 Gödel Scheduler,为业界提供一种新的调度器方案。在离线业务云原生化、在离线业务融合等场景下,Gödel Scheduler 凭借优异的性能和丰富的调度语义,能为用户带来全新的云原生体验。
未来规划
未来,开源团队计划持续迭代 Gödel scheduler,提供更加丰富的功能和更好的扩展性,不断优化一些特殊场景下(比如高部署率,高抢占频率等)的调度吞吐。同时,通过重调度的方式,我们也希望解决调度性能和调度质量难兼顾的难题,在保证调度吞吐的基础上,大幅提升调度质量。我们也将注重生态建设,兼容适配业务主流的系统和框架。
调度质量提升:重调度
我们在实践中发现,调度器没有办法独立解决所有的问题。比如调度器没有办法在保证高性能的情况下,也取得比较好的调度质量。尤其是集群的状态在不断变化,调度器初次调度时给出的业务摆放位置在一段时间后可能变得不再合理。
针对这个问题,字节跳动内部的方案是让 Gödel Scheduler 优先满足业务对性能的要求,初次调度尽力而为。与此同时,我们设计并实现了重调度器 Gödel Rescheduler,用于在业务初次调度之后,根据当时的实际情况进一步改善业务和资源匹配,优化调度质量。
Gödel Rescheduler 是一个真正意义上的重调度器,除了驱逐不合理的任务摆放之外,还可以从全局视角出发,结合集群的当前状态,给出任务更合理的摆放位置,并和 Gödel Scheduler 一起,推动业务重调度、优化调度质量。
此外,Gödel Rescheduler 的 plugin 机制支持一系列可定制的重调度算法和策略(如:可降低资源碎片率的 Binpacking 算法,可提高资源均衡性,降低单机热点的 load balance 策略等),满足计算资源提供方和使用方在不同场景下的不同诉求。
调度功能丰富
Gödel Scheduler 开源团队计划开源更多调度功能,如资源预留、队列间资源管理能力等。
生态建设
未来,Gödel Scheduler 也将对接业界主流大数据和机器学习框架系统,提供使用样例和说明文档。
后续开源团队会在 GitHub 上传详细的 Roadmap 文档,欢迎感兴趣的开发者关注。
虽然 Gödel Scheduler 在字节跳动内部已经迭代多年,被多种场景验证过,但在通用性以及标准化上,它还有很大的提升空间。我们也衷心希望各位朋友加入 Gödel Scheduler 社区,一起把它做得更好!
项目地址:github.com/kubewharf/godel-scheduler
相关链接
[1] SoCC 2023 | Gödel:字节跳动在离线混部统一调度系统
[2] 字节跳动开源 Katalyst:在离线混部调度,成本优化升级
[3] 字节跳动开源 KubeAdmiral:基于 Kubernetes 的新一代多集群编排调度引擎
火山引擎云原生团队
火山引擎云原生团队主要负责火山引擎公有云及私有化场景中 PaaS 类产品体系的构建,结合字节跳动多年的云原生技术栈经验和最佳实践沉淀,帮助企业加速数字化转型和创新。产品包括容器服务、镜像仓库、分布式云原生平台、函数服务、服务网格、持续交付、可观测服务等。
如有侵权请联系:admin#unsafe.sh