Today, most browsers integrate security services that attempt to protect users from phishing att 2024-2-21 01:49:35 Author: textslashplain.com(查看原文) 阅读量:33 收藏
Today, most browsers integrate security services that attempt to protect users from phishing attacks: for Microsoft’s Edge, the service is Defender SmartScreen, and for Chrome, Firefox, and many derivatives, it’s Google’s Safe Browsing.
URL Reputation services do what you’d expect — they return a reputation based on the URL, and the browser will warn/block loading pages whose URLs are known to be sources of phishing (or malware, or techscams).
Beyond URL reputation, from the earliest days of Internet Explorer 7’s phishing filter, there was the idea: “What if we didn’t need to consult a URL reputation service? It seems like the browser could detect signals of phishing on the client side and just warn the user if they’re encountered.“
Client-side Phishing Detection seems to promise a number of compelling benefits.
Benefits
A major benefit to client-side detection is that it reduces the need for service-side detonation, one of the most expensive and error-prone components of running an anti-phishing service. Detonation is the process by which the service takes a URL and attempts to automatically detect whether it leads to a phishing attack. The problem is that this process is expensive (requiring a fleet of carefully secured virtual machines to navigate to the URLs and process the resulting pages) and under constant attack. Attackers aim to fool service-side detonators by detecting that they’re being detonated and cloaking their attack, playing innocent when they know that they’re being watched by security services. Many of the characteristics that attackers look for to cloak against detonators (evidence of a virtual machine, loading from a particular IP range, etc) can’t work when client-side detonation is performed, because the attackers must show their uncloaked attack page to the end-user if they hope to steal their credentials.
Beyond detonation improvements, browser vendors might find that client-side phishing detection reduces other costs (fewer web service hits, no need to transfer large bloom filters of malicious sites to the client). In the URL Reputation service model, browser vendors must buy expensive threat intelligence feeds from security vendors, or painstakingly generate their own, and must constantly update based on false positives or false negatives as phishers rapidly cycle their attacks to new URLs.
Beyond the benefits to the browser vendors, users might be happy that client-side detection could have better privacy properties (no web service checks) and possibly faster or more-comprehensive protection.
So, how could we detect phish from the client?
Clientside ML
Image Recognition
One obvious approach to detecting a phishing site is to simply take a screenshot the page and compare it to a legitimate login site. If it’s similar enough, but the URL is unexpected, the page is probably a phish. Even back in 2006, when graphics cards had little more power than an Etch-a-Sketch, this approach seemed reasonably practical at first glance.
Unfortunately, if the browser blocks fake login screens based on image analysis, the attacker simply needs to download the browser and tune their attack site until it no longer triggers the browser’s phishing detectors. For example, a legitimate login screen:

…is easily tuned by an attacker such that it no longer trips the clientside detection, while looking equivalent to the vast majority of humans:

Even more subtle changes might work; the field of adversarial ML studies how to confuse image processing models as in this wild example:

However, humans are busy, distracted, and easily fooled, such that attackers don’t even need to be especially clever. Here are two real-world phishing attacks that lured user’s passwords despite not looking much like the legitimate login screen:


Text and Other Metadata
If image processing is too prone to false negatives or has too high a computational cost on low-end devices, perhaps we might look at evaluating other information to recognize spoofing.
For example, we can extract text from the title and body of the page to see whether it’s similar to a legitimate login page. This is harder than it sounds, though, because it’s trivial to add text to a HTML page that is invisible to humans but could trip up an extraction algorithm (white-on-white, 1 pixel wide, hidden by CSS, etc). Similarly, an attacker might pick synonyms (Login vs. Sign In, Inbox vs Mailbox, etc) such that the text doesn’t match but means the same thing. An attacker might use multiple character sets to perform a homoglyph spoof (e.g. using a Cyrillic O instead of a Latin O) so that text looks the same to a human but different to a text comparison algorithm. An attacker might use Z-Order or other layout tricks to make text appear in the page in a particular order that differs from the order in the source code. Finally, an attacker might integrate all or portions of text inside carefully-positioned graphics, such that a text-only processor will fail to recognize it.
Making matters more complicated, many websites are dynamic, and their content can change at any time in response to users’ actions, timers, or other factors. Any recognition algorithm must decide how often to run — just on “page load”, or repeatedly as the content of the page changes? The more expensive the recognition algorithm, the more important the timing becomes for performance reasons.
For tech scam sites, image and text processing suffer similar shortcomings, but API observation holds a bit more promise. Most tech scam sites work by abusing specific browser functions, so by watching calls to those functions we may be able to develop useful heuristics to detect an attack-in-progress and do deeper checks for additional evidence. The MalwareBytes security extension uses this approach.
Given the challenges of client-side recognition (false positives, false negatives, and attacker tuning), what else might we do?
Keystrokes
One compelling approach is to just wait for the user to enter their password in the wrong place. While it sounds ridiculous, this approach has a lot of merit — it mitigates (to varying degrees) false positives, false negatives, and attacker tuning all at once.
Way back in 2006, Microsoft explored this idea and ended up filing a patent (Client side attack resistant phishing protection):

When I joined Google’s Chrome team in 2016, I learned that Google had built and fully deployed a Password Alert extension (open-source) on its employee desktops, such that if you ever typed your Google password into a non-Google Login page, the extension would leap into action. One afternoon, I was distracted while logging into a work site and accidentally switched focus into a different browser window while typing my password. I barely taken my finger off the final key before the browser window was taken over by a warning message and an email arrived in my inbox noting that my password had been automatically locked out because I had inadvertently leaked it. While this extension worked especially well for Google Accounts, available variants allow organizational customization such that an enterprise can force-deploy to their users and trigger reporting to backend APIs when a password reuse event is discovered. The enterprise can then either lock the user’s account or the target site can be added to an allowlist of legitimate login pages.
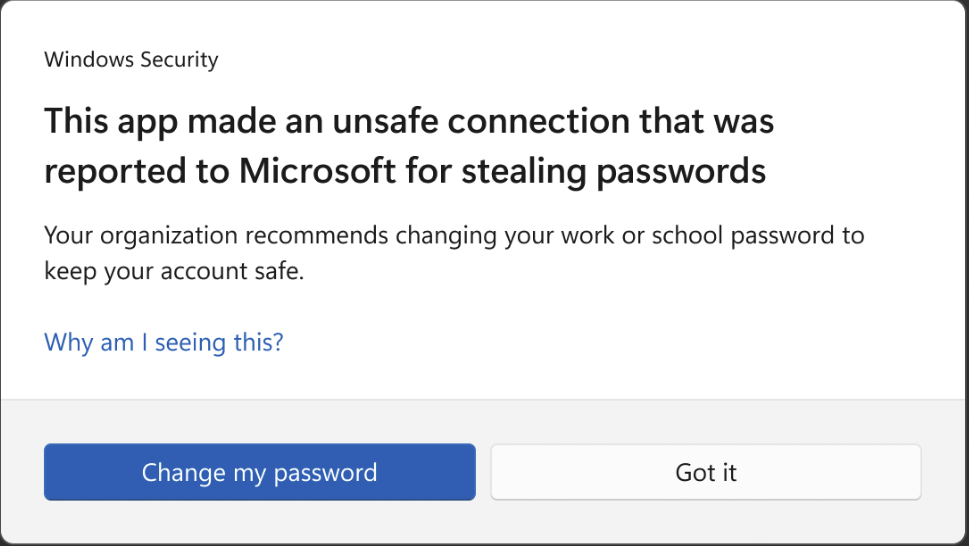
In 2022, Microsoft took our 2006 idea to the next level with the Enhanced Phishing Protection (EPP) feature of Windows 11 22H2. EPP goes beyond the browser such that if you type your Windows login password anywhere in Windows (any browser, any chat window, any note-taking app, etc), Defender SmartScreen evaluates the context (what URL was loaded, what network connections are active, etc) and either warns you of your unsafe activity or suggests changing your password:


Enterprises who have deployed Defender Endpoint Protection receive alerts in their security.microsoft.com portal and can further remediate the threat.
The obvious disadvantage of the “Wait for the bad thing to happen” approach is that it may not protect patient 0 — the first person to encounter the attack. As soon as the victim has entered their password, we must assume that the bad guy has it: Attackers don’t need to wait for the user to hit Enter, and in many cases would be able to guess the last character if the phishing detector triggered before it was delivered to the app. The best we can do is warn the user and lockdown their account as quickly as possible, racing against the attacker’s ability to abuse the credential.
In contrast, Patient-N and later are protected by this scheme, because the first client that observes the attack sends its “I’ve been phished from <url>” telemetry to the SmartScreen service, which adds the malicious URL and blocks it from subsequently loading in any client protected by that URL reputation service.
Conclusions
Attackers and Defenders are engaged in a quiet and ceaseless battle, 24 hours a day, 7 days a week, 366 days a year (Happy leap year!). Defenders are building ingenious protections to speed discovery and blocking of phishing site, but attackers retain strong financial motivation (many billions of dollars per year) to develop their own ingenious circumventions of those protections.
Ultimately, the war over passwords will only end when we finally achieve our goal of retiring this centuries-old technology entirely — replacing passwords with cryptographically strong replacements like Passkeys that are inherently unphishable.
Stay safe out there!
-Eric
PS: Of course, after we get rid of passwords, attackers will simply move along to other attack techniques, including different forms of social-engineering. I hold no illusions that I’ll get to retire with the end of passwords.
如有侵权请联系:admin#unsafe.sh