投稿作者:c4rt1y(信安之路的老朋友)
爬虫(crawler)和反爬虫(anti-crawler)技术之间的对抗是一场持续的猫鼠游戏。爬虫是自动化的网络机器人,它们浏览互联网上的网站,以收集信息和数据。而反爬虫技术则是网站管理员用来阻止或限制爬虫收集数据的技术和策略。
爬虫技术
爬虫技术的目的是高效地收集网络上的信息。以下是一些常见的爬虫技术:
用户代理伪装:通过修改HTTP请求的用户代理字符串,爬虫可以伪装成不同的浏览器或设备,避免被简单的用户代理过滤器识别。
IP代理:使用代理服务器或VPN,爬虫可以更换IP地址,避免因为来自同一IP地址的大量请求而被封禁。
请求频率控制:通过限制请求的频率,爬虫可以模仿正常用户的行为,以减少被检测的机会。
分布式爬虫:使用多台机器或云服务来分散请求,使得跟踪和封禁变得更加困难。
header 信息和 Cookie的管理:合理设置HTTP header 信息和 Cookie,以模拟真实用户的行为。
动态网页抓取:使用工具如 Selenium 或 Puppeteer 来执行 JavaScript,可以抓取动态加载的内容。
反爬虫技术
反爬虫技术旨在识别和阻止不受欢迎的爬虫。以下是一些常用的反爬虫策略:
用户代理分析:检查用户代理字符串,拦截已知的爬虫或不正常的用户代理。
IP 地址监控:监控来自单一IP地址的请求频率,如果超过一定限额,则封禁该IP。
验证码:使用图形或文本验证码来阻止自动化的请求。
动态令牌:网页加载时生成动态令牌,并在后续请求中验证,以防止爬虫模拟请求。
行为分析:分析用户行为,如鼠标移动、点击模式等,以识别非人类行为。
内容和链接混淆:故意在页面中添加一些陷阱链接或信息,当爬虫尝试访问这些内容时,被识别并封禁。
限制头部信息:要求合法请求必须包含某些特定的头部信息,例如正确的 Referer 或 Cookies。
前端JS加密:对前端请求数据的 JS 代码进行加密,增加分析难度,从而提升数据爬取的难度
对抗策略
适应性:爬虫开发者需要不断更新他们的策略,以适应新的反爬虫措施。
机器学习:使用机器学习算法来更好地模仿人类行为,或者识别反爬虫的模式。
协议级别的混淆:通过 TLS/SSL 层面的混淆来隐藏爬虫流量。
爬虫和反爬虫之间的对抗是一个动态平衡,随着技术的发展,双方都在不断进化。网站管理员希望保护其内容和用户数据不被滥用,而数据科学家和市场分析师等职业可能需要收集网站数据以进行合法的分析和研究。因此,这场对抗往往也涉及到法律、伦理和隐私的问题。
本文将以分析获取某企业网站的企业名称为例,分析其反爬策略,编写自动脚本,完成自动化。
1、分析数据请求过程
打开页面,发现是返回数据加密,字段为 encrypt_data:
2、定位关键文件
方法一:Initiator中发现文件
方法二:搜索按钮
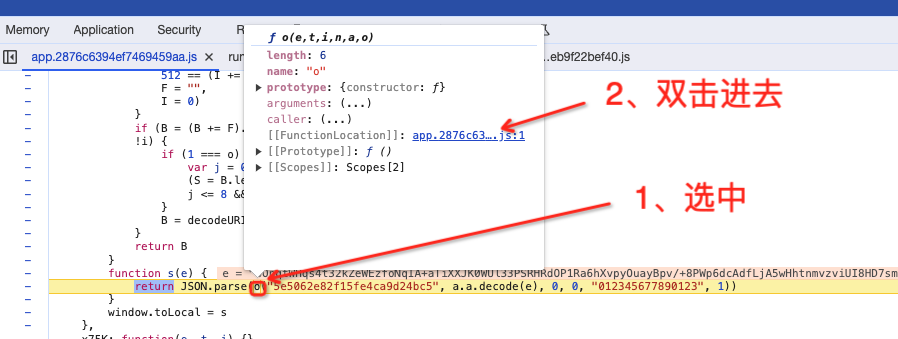
3、调试代码
单步到此处
4、分析代码
核心代码为如下内容
function s(e) {return JSON.parse(o("5e5062e82f15fe4ca9d24bc5", a.a.decode(e), 0, 0, "012345677890123", 1))}
查找 o() 函数信息
将 o() 函数缩小,然后整行复制
解决扣代码问题 a.a.decode() 其实就是 decode:
双击进去,找到 decode,同时发现,存在多个变量:
最终的解密的 js 代码已上传星球,有需要的可以直接前往获取,测试效果如图:
5、将 JS 代码转为 python 脚本
使用浏览器的调试功能,将请求的数据包复制为 curl 命令:
接下来将复制的 curl 命令导入到 postman 中:
最后选择要转换到脚本语言类型,最后复制代码即可:
最终测试代码已上传星球,有需求的直接前往获取,效果如图:
本文仅作为技术交流之用,严禁用户非法用途!
如有侵权请联系:admin#unsafe.sh