随着LLM技术应用及落地,数据库需要提高向量分析以及AI支持能力,向量数据库及向量检索等能力“异军突起”,迎来业界持续不断关注。简单来说,向量检索技术以及向量数据库能为 LLM 提供外置的记忆单元,通过提供与问题及历史答案相关联的内容,协助 LLM 返回更准确的答案。
不仅仅是LLM,向量检索也早已在OLAP引擎中应用,用来提升非结构化数据的分析和检索能力。ByteHouse是火山引擎推出的云原生数据仓库,近期推出高性能向量检索能力,本篇将结合ByteHouse团队对向量数据库行业和技术的前沿观察,详细解读OLAP引擎如何建设高性能的向量检索能力,并最终通过开源软件VectorDBBench测试工具,在 cohere 1M 标准测试数据集上,recall 98 的情况下,QPS性能已可以超过专用向量数据库。
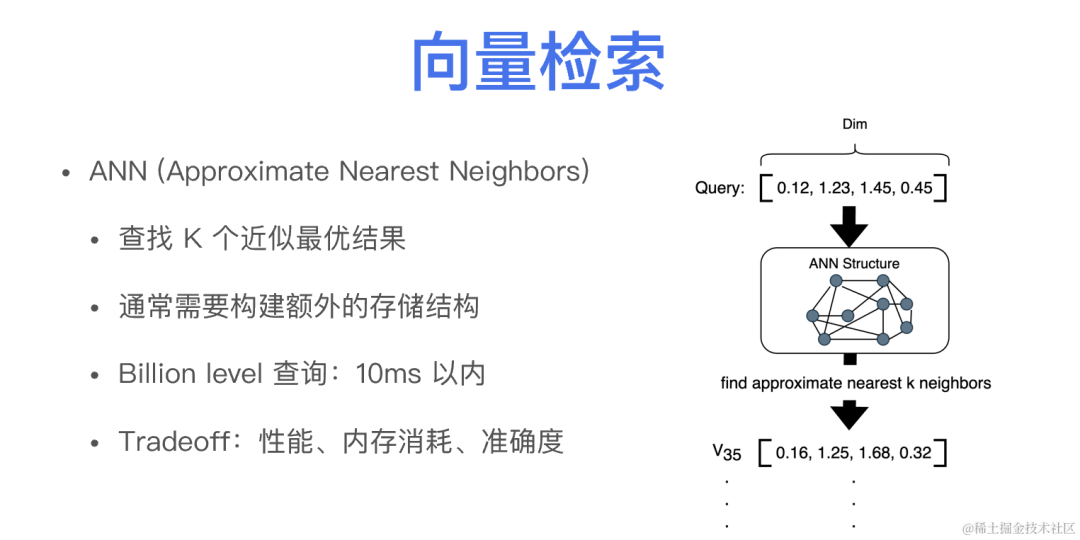
向量检索现状分析
向量检索定义
对于诸如图片、视频、音频等非结构化数据,传统数据库方式无法进行处理。目前,通用的技术是把非结构化数据通过一系列 embedding 模型将它变成向量化表示,然后将它们存储到数据库或者特定格式里。在搜索过程中,通过相同的一个模型把查询项转化成对应的向量,并进行一个近似度的匹配就可以实现对非结构化数据的查询。
在技术原理层面,向量检索主要是做一个 K Nearest Neighbors (K最近邻,简称 KNN) 计算,目标是在N个D维的向量的库中找最相似的k个结果。
在数据量较大场景,KNN 计算通常代价比较大,很难在较短时间内返回结果,此外,在很多场景,用户并不需要绝对精确的相似结果。因此,在真正在使用向量检索时,通常会使用相似最近邻搜索,即 ANN 的方式来替代 KNN,从 k 个绝对最近似结果变成 K 个近似最优结果,以牺牲一定准确度的前提,得到更短的响应时间。
LLM与向量检索
由于大模型的训练数据有限,在针对一些最近的消息或者特定领域信息的查询来说,通常结果不准确。为了提升检索的准确性,一种比较常见的处理方式是将想搜索的信息的相关文档进行文本处理,并通过 embedding 模型将向量写入到向量数据库里后,把问题通过相同的 embedding 模型转化为向量进行近似度搜索,得到问题的相似知识作为 prompt,连同问题一起提交给大模型处理,最终得到更准确的答案。
向量检索的四种算法(索引)
向量检索算法基于其存储结构大致可分为四种。
第一种是 Table-based,典型算法如 LSH。 第二种是 Tree-based,是把向量根据相似度去构造成一个树的结构。 第三种是 Cluster-based,也称为 IVF(Inverted File),把向量先进行聚类处理,检索时首先计算出最近的 k 个聚类中心,再在这些聚类中心中计算出最近的 k 个向量。这种索引的优点是构建速度快,因为构建时只需要多一个 training 的过程。相比于其他常用索引(主要是 Graph-based 索引),只需要额外存储倒排表和聚类中心结构,所以内存额外占用比较少。但也存在相应的缺点,由于每次查询要把聚类中心里面所有的向量都遍历一遍,所以它的查询速度受维度信息影响较大且高精度查询计算量比较大,计算开销大。这类索引通常还会结合一些量化算法来使用,包括 SQ、PQ等。 第四种是Graph-based, 把向量按照相似度构建成一个图结构,检索变成一个图遍历的过程。常用算法是HNSW。它基于关系查询,并以构建索引时以及构建向量之间的关系为核心,而主要技术则是highway和多层优化方式。这种算法的优点是查询速度快、并发性能好;而缺点则表现为构建速度慢、内存占用高。
目前实际场景中,使用较多的方法主要是后面的两种,即 Cluster-based 和 Graph-based。
如何构建向量数据库
首先,一个向量数据库需要具备向量类型数据和向量索引的存储与管理相关功能,包括增删改查等数据维护功能,另外,对于向量检索性能通常要求比较高。其次,向量检索通常需要与属性过滤等操作结合计算。最后,向量检索通常会与其他属性结合查询,比如以图搜图等场景,最终需要的,是相似的图片路径或文件。
构建向量数据库时,一种思路是以向量为中心,从底向上构建一个专用的向量数据库,这样的特点是,可以针对向量检索做特定的优化,能够保证较高的性能,缺点为缺乏复杂的数据管理和查询能力,通常需要结合其他数据库来使用。
另一种设计思路是基于现有的数据库和数据引擎增加向量检索相关扩展功能。优势是可以做到 all in one 的数据管理和查询支持,缺点为受现有架构的限制,很难做到较高的检索性能。
向量数据库的当前进展
向量数据库目前还处于一个快速发展的阶段,目前看有两个趋势,一个是以专用向量数据库为基础,不断添加更多复杂的数据类型支持以及更多的数据管理机制,比如存算分离、一致性支持、实时导入等。此外,查询上也在不断添加前后置过滤等复杂查询策略的支持。
第二种构建思路是数据库加向量检索扩展,继续去支持更多的向量检索算法,并且不断按照向量检索的需求,添加特殊的过滤策略、简化对应的执行计划。
以上两种构建思路都在向一个统一的目标去汇合,即带有高性能向量检索,与完备数据管理和查询支持的数据库形态。这也是 ByteHouse 在设计向量检索相关功能时,主要考虑的一个目标。
ByteHouse的高性能向量检索方案
ByteHouse是火山引擎研发的云原生数据仓库产品,在开源ClickHouse引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资源利用率方面都有巨大的提升。
此外,ByteHouse还支持了向量检索、全文检索、地理空间数据检索等功能。
ByteHouse 作为一款高性能向量数据库的底座的优势在于,其具备比较完备的 SQL 语法支持,高性能的计算引擎,以及比较完备的数据管理机制和丰富的数据表引擎,能够支持不同场景。
为了达到更高的向量检索性能,ByteHouse 基于向量为中心的设计思路,构建了一条高效的向量检索的执行路径,同时,引入了多种常用的向量检索算法,以满足不同场景的向量检索需求。
设计方案
主要设计思路
在 Query 执行过程中,针对向量检索相关查询,从语法解析到执行算子进行了短路改造,同时,引入特殊的执行算子,减少计算冗余与 IO 开销。 添加了专用的 Vector Index 管理模块,包含 向量检索库、向量检索执行器、缓存管理、元数据管理等组件。 存储层添加 Vector Index 相关读写支持,每个 data part 维护一个 Vector Index 持久化文件。
基本使用方式
实际使用时,在建表时可以加一个 Index 的定义,包含索引名称、向量列、以及索引类型信息。
数据导入支持多种方式,比如基于 Kafka 的实时导入,insert file,python SDK 等。
基本查询是一个定式:select 需要的列信息,增加一个 order by + limit 的指令。查询支持与标量信息结合的混合查询,以及针对 distance 的 range 查询。
遇到的挑战
在添加高性能向量检索功能过程中,ByteHouse 主要克服以下三大难点:
读放大问题
根本原因:ByteHouse 中,当前最小的读取单元是一个 mark,即便通过 Vector Index 查询得到结果是有行号信息的,但是在真正读取的时候仍需要转成对应的 mark id 传给下层存储层读取。
优化:
1.把向量检索的计算进行了前置处理。
最初的设计中,向量检索计算时需要每个 data part 首先做 Vector Search 加上其他列信息的读取,然后再去做后面的 order by + limit 得到最终的结果。这种做法相当于每个data part 要取 top k,它的读取的行数是 part 数量乘以 mark_size 乘以 top k。这里做的优化是将 Vector Search 计算前置,上推到 data part 的读取之前,首先执行所有 data part 的 Vector Search,获取全局的 topK 个结果,再分配到各个 data part 去做 read。这样可以实现 IO 从百万减到千的级别的降低,实际使用中整体性能实现了两倍以上的提升。
2.存储层的过滤。
把 row level 的查询结果往下推到存储层读 mark 的位置进行一些过滤,减少了反序列化的开销。
3.在 filter by range 场景进行优化。
基于主键查找如按天查找或者按 label 查找等场景,只对首尾 mark 进行了一个读取和过滤,降低过滤语句的执行开销。
构建资源消耗大
根本原因:相比于其他比较简单的索引,如 MinMax 等,向量索引构建时间更长,并且消耗资源更多。
优化:
在 Build Threads 和 Background Merge Tasks 做了并发限制。 构建过程中内存使用优化,把一些完全在内存里面进行的计算做成了 Disk-based,增加了 memory buffer 的机制。此优化主要是对 IVF 类型的索引进行的。
冷读问题
原因:使用索引需要 Index 结构载入内存,载入到内存后才能进行一些检索加速。
优化:
加入Cache Preload 支持。在服务启动和数据写入以及后台数据 merge 的场景可以自动地把新的 index load 到内存。另外,自动的 GC 会把 Cache 中过期数据自动回收。
最终效果
ByteHouse 团队基于业界最新的 VectorDBBench 测试工具进行测试,在 cohere 1M 标准测试数据集上,recall 98 的情况下,可以达到与专用向量数据库同等水平的性能。在 recall 95 以上的情况下,QPS 可以达到 2600 以上,p99 时延在 15ms 左右,具备业界领先优势。
性能评测
QPS:即评测在不断扩大并发度的前提下,它的QPS最终能达到多少。在同时用HNSW索引情况下,ByteHouse可以达到甚至超过 Milvus Recall:在精确度同等都是98的recall下,QPS才有意义 Load duration:即评测数据从外部添加到系统的时间,包括数据写入和 vector index built 的时间。整个过程包括数据写入和整体时间 ByteHouse 都比 Milvus 好一些。 Serial Latency P99:串行执行 1万条查询,P99 latency。这个 case 下 ByteHouse 要比 Milvus 性能差一些。主要原因是 ByteHouse IO 和 query 解析上仍有一些额外的开销,有很多需要优化的地方,对于小的查询还没有达到一个比较理想的状态。
不同索引评测
评测对象:IVFPQFS+Refine(SQ8)和HNSW。
IVFPQFS+Refine(SQ8) 优点:
在 recall 要求不高的前提下,内存占用资源比较少。(是HNSW的三分之一) 可以降低 refine 的精度,进一步减少内存占用 内存资源受限,写入场景频繁
痛点:
很难在高精度的场景下替换HNSW
未来计划
构建资源需求更少、性能更好的索引结构,比如 on-disk indices 的索引接入以及更好的压缩算法策略。 怎样更好地将向量检索和其他查询结果操作进行融合。比如:复杂过滤语句、基于UDF的Embedding计算融合以及全文检索支持 性能优化。如何与优化器结合,以及点查场景优化 易用性与生态。目前正在接入 langchain 等 LLM 框架,后续会进一步思考怎么样在大模型场景以及其他向量检索场景中做到更好的易用性。
如有侵权请联系:admin#unsafe.sh