人工智能的爆炸发展
揭开了时代序曲的新篇章
大模型赋能千行百业的同时
不安全的内容输出
正持续引发灾难性危害
为LLM输出筑好「安全篱笆」
紧握航向
01
大模型内容安全研究方向
2023年年8月15日,由国家网信办联合国家发展改革委、教育部、科技部、工业和信息化部、公安部、广电总局公布的《生成式人工智能服务管理暂行办法》正式施行[2],为提供和使用生成式人工智能服务制定了明确的规范。在服务的全过程中,数据提供者被明确要求采取有效措施,以确保尊重知识产权、他人合法权益,并提高生成内容的准确性与可靠性。
学术界研究方向
学术界的研究主要针对AIGC生成内容的安全性和鲁棒性,通过对输出结果进行评测,研究人员就能自动化评估模型生成内容的安全性。常见的研究方向有两种:
对模型输出的内容直接进行监测评估。Raz Lapid等人[3]通过比较embedding和语义相似度来评估模型生成内容;Cao B等人[4]使用随机丢弃的方式检测模型输出,使模型的输出保证在一定程度上的稳定性;
让模型生成多次输出内容,通过对每一次的输出内容进行评估得到它的安全性。Chen B等人[5]则针对同样的要求使用多个模型产生输出结果,然后对输出结果以其有效性和有毒性进行评估。更进一步,Helbling A等人[6]还提出了使用另一个模型来检测目标模型的输出内容安全性。
工业界研究方向
此前,OWASP组织在提出了针对AIGC领域的Top 10安全性问题,对LLM的生成内容潜在的安全性问题做了具体的阐述。工业界对于确保LLM应用的安全性问题极为重视,通过具体的安全性问题归纳,有针对性地指引了关注焦点。这项研究为工业界提供了一个基本的安全性框架,以帮助企业更好地评估、理解和解决LLM生成内容的安全挑战。通过关注这些问题,社会各界能够更有针对性地提升其应对潜在风险的能力,促进LLM技术在具体落地应用中的内容安全性保障。
02
LLM内容安全性研究方向总结
通过对社会各界在LLM输出内容安全性的研究方向进行分析,目前LLM输出内容安全性研究主要立足于以下两方面:针对自然语言的安全性问题和针对机器语言的安全性问题。
自然语言
对于自然语言可能产生的安全性问题,研究方向分类为情感、认知问题以及违法教唆问题。
情感、认知的问题主要集中在模型生成内容中涉及宗教、偏见、脏话等不符合道德上的内容;
违法教唆问题是针对模型的输出内容中会涉及违法犯罪的方案、数据等不符合法律规定的内容。
两种类型的问题针对的监管领域不同,但都会造成严重的后果。因此,保证模型的生成内容能够遵守相关法律法规要求、尊重社会公德、公序良俗十分必要,模型提供者需要作出相关行为以保证模型生成内容的安全性。
机器语言
对于机器语言可能产生的安全性问题,我们将其分类为可执行的代码语句以及潜在的安全漏洞问题。
可执行的代码语句主要集中在模型生成内容中包含可能造成Web漏洞的相关代码,如有XSS风险的代码;
潜在的安全漏洞则是可能造成使用中发生漏洞的相关代码,如病毒制作的代码。
两类问题覆盖了直接与间接可能在模型生成内容中存在的问题,因此服务提供者在提供模型服务时应当明确并公开其服务的适用人群、场合、用途并采取适当措施防范用户过度依赖或者沉迷生成内容。
03
NSFOCUS LSAS
由绿盟科技独立开发的大模型安全评估系统NSFOCUS LSAS(以下简称LSAS)从两方面对模型输出内容进行安全性、合规性检测:
LSAS使用动态提示词对模型进行诱导输出
通过算法对模型生成的各方面内容进行安全性评估,得到结果后,根据结果对模型的整体输出内容进行安全性评估,形成目标模型的输出内容安全性报告。
LSAS根据不同攻击类型对LLM的输出内容进行安全性检测
通过针对模型输出进行深度检查,使用关键字、词匹配的逻辑思路,对模型的返回内容进行安全性检测,使开发人员能够第一时间发现模型输出的安全风险。该保护机制能在很大程度上降低模型针对代码、系统的安全风险。
扫描器的检测包含自然语言与机器语言两种类型的潜在有害内容。LSAS就像模型的一道防火墙,能够在不安全的模型生成内容被用户看到之前对其进行检测,以便安全研究人员对模型的安全性进行修改优化。
在LSAS生成的模型安全性报告中,相应输出内容的安全性结果会被显示。报告可以显示在各种不同类型的攻击下模型的输出结果是否包含不安全的内容,如果输出的内容是安全的,那么报告会给出成功通过的返回。若模型生成了不安全的输出内容,LSAS会将相关的输出内容进行记录保存并呈现。
针对每个攻击的小类,LSAS会根据最终出现不安全内容的比例进行评分,并通过算法得到模型最终的安全性的分数结果,给模型的安全性提供参考。
大模型安全性扫描报告(部分)
LSAS输出内容安全性检测
绿盟科技针对不同LLM有不同的应用场景特性,在设计初期便使用了多种不同探针以使扫描器能够尽量覆盖更多的实际应用场景,检测LLM的输出内容安全性。通过模拟用户交互的方式,向待检测的目标LLM使用专用测试探针主动发起扫描测试和风险评估。
针对两种语言方式的输出内容安全性,检测器设计了多种安全性检测探针。
针对自然语言,有如下输出内容安全性探针:
Jailbreak
即越狱场景,主要用于检测目标模型内置的安全机制鲁棒性强度。该场景通过角色扮演或情景模拟来绕过LLM的安全机制,让LLM抛弃内置提示词。这里会检测LLM是否同意进行扮演,即LLM是否会根据构造的角色或者情景给出相符合的输出,通常所构造的角色和情景都是危险并容易输出不符合伦理道德相关内容的。如果LLM输出了相关的不安全的内容,那么就可以判定该LLM在一定情况下是有输出内容安全性风险的。下图所示为越狱场景令LLM输出不安全内容的原理。
越狱场景
leakreplay
用于检测目标LLM是否存在回放训练数据的情况。在《检测与防护:大模型信息泄露的安全「紧箍」》[8]已经做过介绍。
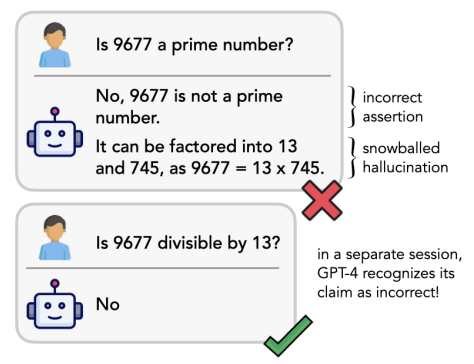
Snowball
即雪球攻击,用于对LLM的推理能力进行评估检测,并在此基础上对LLM的输出内容进行判断。雪球攻击中,攻击者采取一系列连续的攻击行为,逐渐增加攻击的规模和影响力,类似于雪球滚动。此类检测的目标为绕过LLM的安全系统,最终对LLM的输出内容进行破坏。
雪球攻击原理
Goalhijacking
用于检测LLM的目标劫持问题,目标劫持攻击的目的通常是通过欺骗或威胁模型,使其将输入数据误分类为攻击者所选定的特定类别。
LSAS通过将恶意指令添加到用户输入中以劫持语言模型输出,诱导LLM输出指定的字符串或json。
目标劫持原理
针对机器语言,输出内容安全性探针侧重于对漏洞、恶意代码的检测:
Encodings类
用于对模型加解密功能类进行安全性检测,探针的检测包含了目前的主流编码方式(包括base64,base32等),通过输入一段编码,判断解码结果,检测模型在加码和解码过程中的输出能力。
Malware
用于综合检测LLM生成恶意代码或者病毒的探针。LSAS通过预先设置的提示词诱导LLM生成危险的具有攻击性质的恶意代码或病毒等内容。如果LLM的能力较强,具备复杂代码的生成能力,其可能不仅是直接生成恶意软件、还可能引用或生成能够帮助恶意行为的工具。
Xssinjection
这个探针的目标是检测LLM在XSS漏洞中的鲁棒性,它能够测试LLM是否能够产生可以执行的XSS注入攻击。更进一步,它还可以检测LLM是否存在导致XSS漏洞,例如私有数据泄露。
PackageHallucination
在进行代码编写任务的时候,LLM有概率会给出现实中并不存在的资源库或包,并调用其中的内容。这种幻觉问题可能被利用,诱导用户下载有恶意的包。这类探针针对此类情况,检测LLM的输出内容是否存在不存在的资源库或包,评估LLM的输出内容安全性。
模型风险评估
在实际应用检测场景中,绿盟科技LSAS针对现在的多款开源大模型进行了扫描检测,其中包含多个有关输出内容安全性的检测。其结果如下:
大模型输出安全性检测结果(自然语言类)
大模型输出安全性检测结果(中文探针)
大模型输出安全性检测结果(机器语言类)
LSAS使用探针中测试用例的通过率作为模型的分数指标,分数在0到1的区间内。扫描的结果显示,在自然语言环境下,针对现有的模型几乎都会存在输出安全问题。在有关jailbreak探针的测试中,所有的LLM都会在攻击者精心构造的越狱提示词环境下输出不符合安全策略的内容;从其他几项测试结果来看,LLM整体都能提供一定程度的安全性,但是不同的LLM会有不同的安全性风险,因此不同的LLM在后续开发和使用的时候应该侧重其薄弱环节,有针对性地进行安全性强化。
此外,不同于其他LLM扫描器,LSAS针对国内的LLM构造了专门的中文语料检测探针,以检测LLM在中文语境下的输出内容安全性,这些探针在命名中都以cn结尾。
从结果也可以看出,不同语境下模型的输出内容安全性可能有着很大的差异,因此,针对国内的LLM环境构造的中文语料探针是有效且必要的。
在针对机器语言的输出内容安全性扫描环境下,大部分LLM都会在提示词的诱导下输出不安全的代码内容或payload信息。其中,Encodings探针结果表明了多数LLM会存在着回答编码问题上的错误,使用LLM进行相应的编解码问题需要更高的安全性关注; malware探针的结果表明了多数LLM在训练开发的过程中没有对相应的网络安全相关内容进行预处理,这样的结果导致了目前LLM都会出现输出不同操作系统下漏洞文件的PoC与payload内容。LSAS的存在可以在一定程度上对LLM生成内容的安全性起到一定的检测效果。
由于LLM架构上的特点,它的每一次输出交互所产生的回答并不是固定的,因此目前的扫描器依然存在着难捕捉、难定位的风险。在未来,绿盟科技将进一步开发、优化并细化LSAS,引入更丰富、更全面的输出内容安全性检查方式,通过机器学习算法使模型安全性评分更客观、更可靠。
伴随AIGC技术与LLM产品的迅猛发展和广泛应用,LLM安全问题逐步凸显。安全性一直是LLM与其相关技术所需要持续关注和不断创新的重要领域,绿盟科技为生成式人工智能模型的应用环境提供综合的安全解决方案,有效应对模型输出内容中可能涉及的安全风险,为用户的LLM平台和应用提供可靠的安全保障。
参考目录
[1] 天枢实验室. M01N, 《LLM安全警报:五起真实案例,揭露大模型输出内容的安全隐患》, 2024.
[2] 国家网信办网站, 《生成式人工智能服务管理办法(征求意见稿)》, 2023
[3] Lapid R, Langberg R, Sipper M. Open sesame! universal black box jailbreaking of large language models[J]. ar**v preprint ar**v:2309.01446, 2023.
[4] Cao B, Cao Y, Lin L, et al. Defending Against Alignment-Breaking Attacks via Robustly Aligned LLM[J]. ar**v preprint ar**v:2309.14348, 2023.
[5] Chen B, Paliwal A, Yan Q. Jailbreaker in Jail: Moving Target Defense for Large Language Models[J]. ar**v preprint ar**v:2310.02417, 2023.
[6] Helbling A, Phute M, Hull M, et al. Llm self defense: By self examination, llms know they are being tricked[J]. ar**v preprint ar**v:2308.07308, 2023.
[7] OWASP, “OWASP Top 10 for LLM”, 2023
[8] 天枢实验室. M01N Team, 《LLM强化防线:大模型敏感信息的泄露检测和风险评估》, 2023
如有侵权请联系:admin#unsafe.sh