最近看到两个 C++ 关于 std::vector 的性能问题,感觉特别有意思,特写下本文记录一下。
std::vector 比 原生数组更慢吗?
问题原文可参考 StackOverflow 上的 Is std::vector so much slower than plain arrays?。
该问题提问时间较为久远,使用现在的编译器和CPU,本人的测试结果是 UseVector 比 UseArray 更快:
UseArray completed in 0.21 seconds UseVector completed in 0.166 seconds UseVectorPushBack completed in 1.002 seconds
但是,仅做简单的修改,会得到与问题类似的结论:
struct Pixel
{
Pixel() = default; // 或者删掉两个构造函数
Pixel(unsigned char r, unsigned char g, unsigned char b) : r(r), g(g), b(b)
{
}
unsigned char r, g, b;
};使用默认构造函数,或者删掉两个自定义构造函数后,新的测试结果为:
UseArray completed in 0.207 seconds UseVector completed in 0.325 seconds UseVectorPushBack completed in 1.002 seconds
可以看到,UseVector 就比 UseArray 更慢,这与原问主的结论是类似的。
那么 UseVector 慢的原因是什么呢?对比我们做的改动,可以看到慢是因为默认的构造函数会初始化rgb三个成员变量,使用空的构造函数能提升1倍的性能,比原生数组更快。
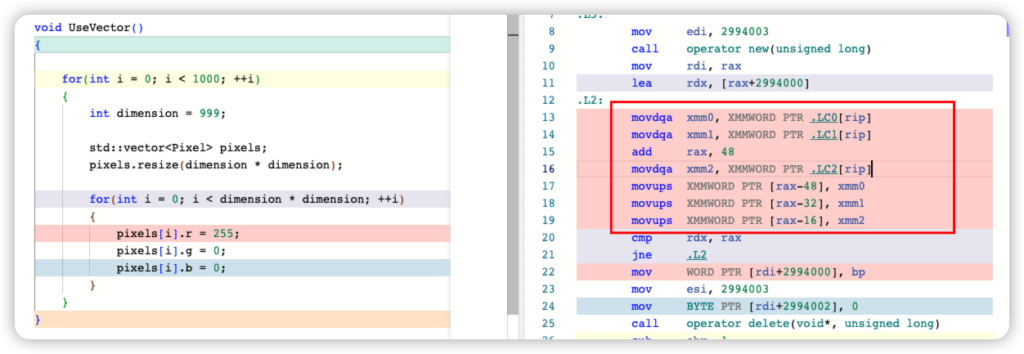
最后一个点是为什么 push_back 反而是最慢呢?原因是分配好空间后对 for循环使用了向量化(Vectorization)或者SIMD指令,而 push_back 需动态扩容导致无法向量化。在 Godbolt 上可以看到,开启 -O3 优化选项,编译器会使用向量化指令:
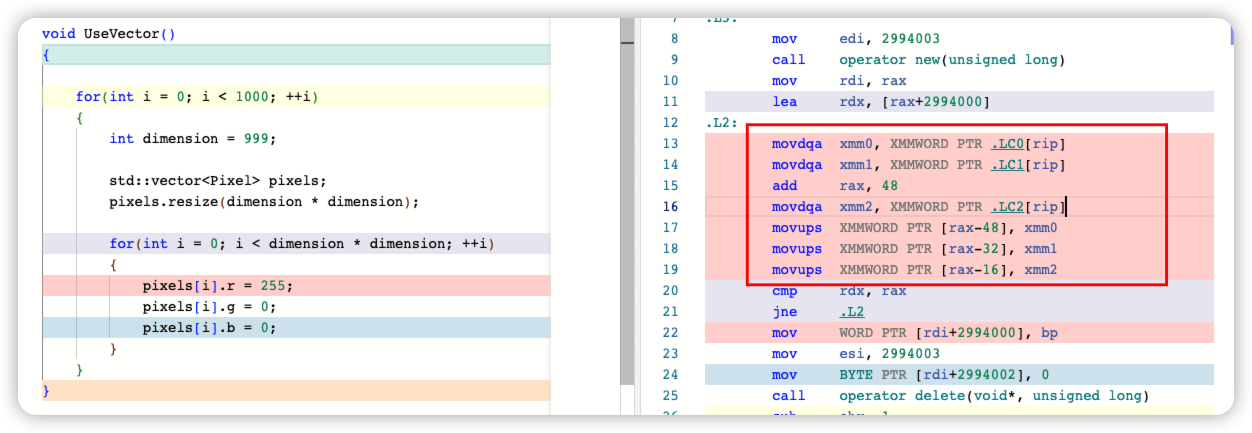
至此,可以总结出两个启示:
1. C++中推荐使用默认构造函数,但是对于性能场景,空的构造函数可能有更好的表现,当然需要根据测试数据说话;
2. SIMD指令对性能提升很大,在已知长度的场景,应该尽量先分配空间使得for循环能向量化。
std::vector 的 reserve 会导致性能大幅下降
之前的文章 vector的性能利器:reserve 提到过,对于大小已知的数组,应该尽量使用 reserve,避免后续内存分配和数据复制以提升性能。但是这个结论仅针对最终大小已知且 reserve 一次,多次 reserve 反而可能会导致程序性能严重下降。
正好在 SO 上也有一个类似的问题:Why are C++ STL vectors 1000x slower when doing many reserves?。在这个案例中,提前一次性 reserve 空间当然是性能最佳的情况。但是对于 Test 4,多次 reserve 却让程序慢了1000倍,这与我们在实践中得到的情况是相同的。
原因在于 reserve 和 resize 不同,reserve 会精确分配所需空间(如果小于当前size则不操作),而 resize 同 push_back,会预先分配更多的可用空间。因此在 Test 4中,执行了 10000 次的内存分配和数据复制,性能当然就极其糟糕了。
该案例的启示:
1. 最终大小已知的情况,一次性 reserve 或者 resize 性能最佳(同上例,resize 后能使用向量化会更佳);
2. 如果不确定最终大小,中间过程多次 reserve 反而可能会导致程序下降;
3. 初始的 reserve 总是有用的,能稍微提升性能;
4. 中间过程多次 reserve 会导致性能下降,该结论同样适用于 std::unordered_set、std::unordered_map 等容器。
总结
实践出真知,一个简单的 resize/reserve 也会导致程序的性能千差万别。