Ios系统的内核内存分配器是目前笔者见到的最为安全的内存分配器,没有之一。
1.1 放弃FIFO设计
首先苹果公司抛弃了内存分配器的LIFO这种结构设计,后进先出是栈的结构,对于刚释放的内存会优先让它分配出去,操作系统讲究程序局部性原理,也就是最近使用的内存很可能会最近再次被使用。这种设计有助于提高内存分配器的性能。但是很多漏洞攻击程序会利用这个特点,精心的控制内存布局,这几乎是每个内核堆攻击必然要使用的技巧。苹果公司为了安全直接放弃了LIFO的设计, 我们在zalloc源码中,可以见到如下注释:
我们先看下cache的架构:
一个zone的cache包含两大块结构,第一为左侧的zc_alloc和zc_free magazine,一个专门用来分配内存,一个专门用来释放内存。右侧为cpu的本地仓库depot,它是一个单向链表,链接着数个空闲的magazine。
static void *zalloc_cached(zone_t zone, zone_stats_t zstats, zalloc_flags_t flags,vm_size_t esize){zone_cache_t cache;cache = zpercpu_get(zone->z_pcpu_cache);if (cache->zc_alloc_cur == 0) {if (__improbable(cache->zc_free_cur == 0)) {return zalloc_cached_slow(zone, zstats, flags, esize, cache);}zone_cache_swap_magazines(cache);}return zalloc_cached_fast(zone, zstats, flags, esize, cache, NULL);}
首先判断zc_allo这个magazine是否为空,不为空就从这里划走一个element。如果为空,则会判断zc_free这个magazine,如果它不为空,就将它们俩进行交换。
static voidzone_cache_swap_magazines(zone_cache_t cache){uint16_t count_a = cache->zc_alloc_cur;uint16_t count_f = cache->zc_free_cur;zone_element_t *elems_a = cache->zc_alloc_elems;zone_element_t *elems_f = cache->zc_free_elems;z_debug_assert(count_a <= zc_mag_size());z_debug_assert(count_f <= zc_mag_size());cache->zc_alloc_cur = count_f;cache->zc_free_cur = count_a;cache->zc_alloc_elems = elems_f;cache->zc_free_elems = elems_a;}
只对指针和对应element数据进行了交换。
在看下cache free的过程:
static voidzfree_cached(zone_t zone, struct zone_page_metadata *meta, zone_element_t ze){zone_cache_t cache = zpercpu_get(zone->z_pcpu_cache);if (cache->zc_free_cur >= zc_mag_size()) {if (cache->zc_alloc_cur >= zc_mag_size()) {return zfree_cached_slow(zone, meta, ze, cache);}zone_cache_swap_magazines(cache);}uint16_t idx = cache->zc_free_cur++;if (idx >= zc_mag_size()) {zone_accounting_panic(zone, "zc_free_cur overflow");}cache->zc_free_elems[idx] = ze;}
如果zc_free保存的element过多,则调用zone_cache_swap_magazines和zc_alloc进行交换,否则放回zc_free magazine里。
分配内存时,直接从zc_alloc里分配, 释放时一直会放回zc_free magzine里,可以说分配和释放几乎避开了FIFO的特性,相互不打扰。但是为什么说是几乎呢,因为逻辑中还有swap两个magazione的情景,但是对于漏洞利用来讲也会增加不少难度。
1.2 meta和element分离设计
1.2.1 bsd与linux
除了windows,其他几大操作系统内核bsd、linux、xnu都使用基于solaris slab的结构设计。对于一个chunk,它的管理结构meta和chunk里的element在设计上,每个os却不一样,对于bsd来讲,它的设计是最糟糕的,meta管理结构直接放在了element的后面:
对于小块item, slab这种设计属于严重的安全错误设计,slab header放在所有item的最后,如果最后一个item发生溢出,就可以直接覆盖slab header里的数据结构。
struct uma_slab {uma_keg_t us_keg; /* Keg we live in */...}Slab header结构为struct Uma_slab,它的第一个成员是us_keg。struct uma_keg {LIST_HEAD(,uma_zone) uk_zones; /* Keg's zones */...}
Uk_zones结构为:
struct uma_zone {uma_ctor uz_ctor; /* Constructor for each allocation */uma_dtor uz_dtor;}
结构体成员uz_ctor和uz_dtor为每个zone在创建和销毁时调用的析构函数指针,exploit程序一般都会替换这两个函数指针,使其指向shellcode地址。Slab header放在最后,使堆溢出攻击变得更加简单。
而因为linux内核则对基进行了改进,把slab header放在了最前面。我们在设计内存分配器时就要避免这种糟糕的设计,同时管理结构体中函数指针的定义一定要做到最少,防止被exploit程序滥用。
1.2.2 xnu的分离设计
Xnu在8000版本中,将meta与element做了分离设计:
一个zone的基本管理结构为struct zone_page_meta:
struct zone_page_metadata {union {struct {zone_id_t zm_index : 10;uint16_t zm_guarded : 1;uint16_t zm_inline_bitmap : 1;zm_len_t zm_chunk_len : 4;};uint16_t zm_bits;};union {#define ZM_ALLOC_SIZE_LOCK 1uuint16_t zm_alloc_size; /* first page only */struct {uint8_t zm_page_index; /* secondary pages only */uint8_t zm_subchunk_len; /* secondary pages only */};uint16_t zm_oob_offs; /* in guard pages */};union {uint32_t zm_bitmap; /* most zones */uint32_t zm_bump; /* permanent zones */};union {struct {zone_pva_t zm_page_next;zone_pva_t zm_page_prev;};vm_offset_t zm_pgz_orig_addr;struct zone_page_metadata *zm_pgz_slot_next;};};
一个struct zone_page_metadata管理一个PAGE_SIZE大小的虚拟内存。内存子系统在初始化时会申请一块足够大的内存用来管理所有的物理内存。每个page_metadata通过双向链表链接起来。我们看到前面cache中的magazione结构体保存的elements就是从metadata里分配的。一个虚拟地址vaddr右移PAGE_SIZE即可得到metadata数组的索引。
每个meta又挂接在zone的几个队列里:
zone_pva_t z_pageq_empty; /* populated, completely empty pages */zone_pva_t z_pageq_partial;/* populated, partially filled pages */zone_pva_t z_pageq_full; /* populated, completely full pages */zone_pva_t z_pageq_va; /* non-populated VA pages */
z_pageq_empty为空队列, z_pageq_partial为半满队列, z_pageq_full为全满队列,z_pageq_va为备用队列。每个基于slab的内存管理器都会前三个队列。
__header_always_inline voidzalloc_import(zone_t zone, zone_element_t *elems, zalloc_flags_t flags,vm_size_t esize, uint32_t n){do {vm_offset_t page, eidx, size = 0;struct zone_page_metadata *meta;if (!zone_pva_is_null(zone->z_pageq_partial)) {meta = zone_pva_to_meta(zone->z_pageq_partial);page = zone_pva_to_addr(zone->z_pageq_partial);} else if (!zone_pva_is_null(zone->z_pageq_empty)) {meta = zone_pva_to_meta(zone->z_pageq_empty);page = zone_pva_to_addr(zone->z_pageq_empty);zone_counter_sub(zone, z_wired_empty, meta->zm_chunk_len);} else {zone_accounting_panic(zone, "z_elems_free corruption");}zone_meta_validate(zone, meta, page);vm_offset_t old_size = meta->zm_alloc_size;vm_offset_t max_size = ptoa(meta->zm_chunk_len) + ZM_ALLOC_SIZE_LOCK;do {eidx = zone_meta_find_and_clear_bit(zone, meta, flags);elems[i++] = zone_element_encode(page, eidx);size += esize;} while (i < n && old_size + size + esize <= max_size);vm_offset_t new_size = zone_meta_alloc_size_add(zone, meta, size);if (new_size + esize > max_size) {zone_meta_requeue(zone, &zone->z_pageq_full, meta);} else if (old_size == 0) {/* remove from free, move to intermediate */zone_meta_requeue(zone, &zone->z_pageq_partial, meta);}} while (i < n);}
分配内存时首先从z_pageq_partial半满队列分配,如果它为空,则再从z_pageq_empty队列分配。如果分配完后,meta里的elements用完,则挂接到z_pageq_full, meta全满队列,否则挂接到z_pageq_partial半满队列里。
注意每个队列的类型为zone_pva_t:
typedef struct zone_packed_virtual_address {uint32_t packed_address;} zone_pva_t;
它是一个32字节的结构体,保存的是meta的索引。每个队列的header是放在内核__DATA section里。
队列header指向第一个meta,每个meta有通过双向链表链接起来。
__header_always_inline voidzone_meta_queue_push(zone_t z, zone_pva_t *headp,struct zone_page_metadata *meta){zone_pva_t head = *headp;zone_pva_t queue_pva = zone_queue_encode(headp);struct zone_page_metadata *tmp;meta->zm_page_next = head;if (!zone_pva_is_null(head)) {tmp = zone_pva_to_meta(head);if (!zone_pva_is_equal(tmp->zm_page_prev, queue_pva)) {zone_page_metadata_list_corruption(z, meta);}tmp->zm_page_prev = zone_pva_from_meta(meta);}meta->zm_page_prev = queue_pva;*headp = zone_pva_from_meta(meta);}
通过zone_meta_queue_push将一个meta挂接到队列里。
__header_always_inline struct zone_page_metadata *zone_meta_queue_pop(zone_t z, zone_pva_t *headp){zone_pva_t head = *headp;struct zone_page_metadata *meta = zone_pva_to_meta(head);struct zone_page_metadata *tmp;zone_meta_validate(z, meta);if (!zone_pva_is_null(meta->zm_page_next)) {tmp = zone_pva_to_meta(meta->zm_page_next);if (!zone_pva_is_equal(tmp->zm_page_prev, head)) {zone_page_metadata_list_corruption(z, meta);}tmp->zm_page_prev = meta->zm_page_prev;}*headp = meta->zm_page_next;meta->zm_page_next = meta->zm_page_prev = (zone_pva_t){ 0 };return meta;}
通过zone_meta_queue_pop将meta移出队列。
我们看到xnu通过这种精妙的设计彻底将meta与element分离出来,能有效的提高攻击难度。
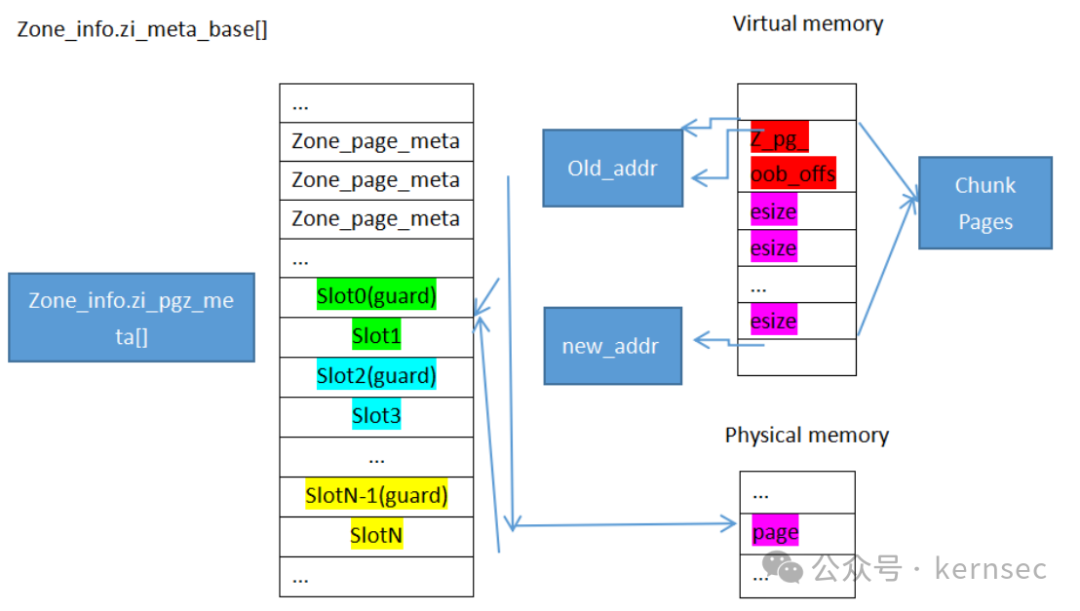
1.3 有趣的Guard page设计
几乎每个内存管理器都会有Guard page,而xnu的设计更加有趣。本来申请一个meta后会返回它的虚拟地址,但是xnu会在另一个区域里分配两个连续的meta,它会概率性的在这个Meta后面加入一个guard page,这个page只有虚拟内存,没有映射对应的物理内存,因此一旦meta溢出,就会发生page fault。而前面的meta将虚拟地址映射为原先申请的meta的物理地址,也就是double mapping,然后将新的meta地址返回。
先看下它的架构:
内存子系统在初始化时会从meta_base里划出一块内存,用作有guard page需求的zone。
pgz_init(void){for (size_t i = 0; i < 2 * pgz_slots + 1; i += 2) {zone_info.zi_pgz_meta[i].zm_chunk_len = ZM_PGZ_GUARD;}for (size_t i = 1; i < pgz_slots; i++) {zone_info.zi_pgz_meta[2 * i - 1].zm_pgz_slot_next =&zone_info.zi_pgz_meta[2 * i + 1];}for (uint32_t slot = 0; slot < pgz_slots; slot++) {(void)pmap_enter_options_addr(kernel_pmap, pgz_addr(slot), 0,VM_PROT_NONE, VM_PROT_NONE, 0, FALSE,PMAP_OPTIONS_NOENTER, NULL);}}
注意上述函数将slot的虚拟地址暂时都映射到物理地址0上。
在内存分配时,调用pgz_protect实施前述的guard保护。
__attribute__((noinline))static vm_offset_tpgz_protect(zone_t zone, vm_offset_t addr, zalloc_flags_t flags, void *fp){kern_return_t kr;uint32_t slot;if (!pgz_slot_alloc(&slot)) {return addr;}vm_offset_t new_addr = pgz_addr(slot);pmap_paddr_t pa = kvtophys(trunc_page(addr));kr = pmap_enter_options_addr(kernel_pmap, new_addr, pa,VM_PROT_READ | VM_PROT_WRITE, VM_PROT_NONE, 0, TRUE,(flags & Z_NOWAIT) ? PMAP_OPTIONS_NOWAIT : 0, NULL);if (__improbable(kr != KERN_SUCCESS)) {pgz_slot_free(slot);return addr;}struct zone_page_metadata tmp = {.zm_chunk_len = ZM_PGZ_ALLOCATED,.zm_index = zone_index(zone),};struct zone_page_metadata *meta = pgz_meta(slot);os_atomic_store(&meta->zm_bits, tmp.zm_bits, relaxed);os_atomic_store(&meta->zm_pgz_orig_addr, addr, relaxed);pgz_backtrace(pgz_bt(slot, false), fp);return new_addr + (addr & PAGE_MASK);}
pgz_slot_alloc函数从zi_pgz_meta里选取一个slot,一个slot是由两个meta组成。 pgz_addr函数从这个slot中提取新的虚拟地址,kvtophys函数从老的虚拟机地址里提取对应的物理地址,pmap_enter_options_addr将新的虚拟地址重新映射到刚才提取到的物理地址中,形成了一个双映射。而后面的guard page虽然由虚拟地址,但是没有映射到对应的物理地址上,因此访问guard内的内存就会产生page fault。
注:ios16 beta并没有开启此保护。
1.4 Readonly保护
Zone提供了一个只读内存的功能,当一些数据在初始化后,基本就不会在改变的时候,就可以将其放入readonly内存区域,然后通过ppl进行写保护。
Zone提供了3个接口用于操作只读内存。
1.4.1 zalloc_ro_mut
__attribute__((noinline))voidzalloc_ro_mut(zone_id_t zid, void *elem, vm_offset_t offset,const void *new_data, vm_size_t new_data_size){zalloc_ro_mut_validate_src(zid, elem, (vm_offset_t)new_data,new_data_size);pmap_ro_zone_memcpy(zid, (vm_offset_t) elem, offset,(vm_offset_t) new_data, new_data_size);}
zalloc_ro_mut函数用于将指定内存拷贝到只读内存,pmap_ro_zone_memcpy函数请求的是ppl中对应的服务函数, 我们以最新的ios16为例进行逆向分析。
pmap_ro_zone_memcpy_ppl ; DATA XREF:MOV X20, X4MOV X22, X3MOV X23, X2MOV X21, X1MOV X25, X0ADD X24, X2, X1MOV X0, X24 ; va + offsetBL kvtophys_nofail
首先调用kvtophys_nofail将va + offset转为物理地址pa。
MOV X19, X0 ; paADRP X8, #vm_first_phys@PAGELDR X8, [X8,#vm_first_phys@PAGEOFF]ADRP X9, #vm_last_phys@PAGELDR X9, [X9,#vm_last_phys@PAGEOFF]CMP X8, X0CCMP X9, X0, #0, LSB.LS loc_FFFFFFF008498A94 ; vm_first_phys < pa < vm_last_phys
接着判断物理地址pa是否在合法地址范围内。
CBZ X22, loc_FFFFFFF008498A78 ; new_data == NULLCBZ X20, loc_FFFFFFF008498A78 ; new_data_size == 0
判断new_data是否为空, new_data_size是否为0。
MOV X0, X25MOV X1, X21MOV X2, X23MOV X3, X22MOV X4, X20BL pmap_ro_zone_validate_element ; (zid, va, offset, new_data, new_data_size)
调用pmap_ro_zone_validate_element函数做参数检查,在稍后会详细分析。
MOV X0, X19MOV X1, X21MOV X2, X20BL pmap_ro_zone_lock_phy_page ; (pa, va, offset)MOV X0, X19 ; vm_offset_tBL _ml_static_ptovirt_0MOV X1, X22 ; __srcMOV X2, X20 ; __nBL _memmove ; (pa, new_data, new_data, size)
可以看到,ppl直接使用memmove将目标内存拷贝进va对应的物理内存。Ppl并没有做请求来源的验证,这导致攻击者可以利用rop等技术直接调用此服务函数,将readonly内存改写为其他的内容。
接着, 我们在仔细分析pmap_ro_zone_validate_element函数。
pmap_ro_zone_validate_element ; CODE XREF: pmap_ro_zone_bzero_ppl+6C↑pADDS X8, X3, X4B.CS loc_FFFFFFF0084946E0 ; new_data + new_data_size < new_dataMOV X3, X4B pmap_ro_zone_validate_element_dst ; (zid, va, offset, new_data_size)
首先判断new_data + new_data_size是否溢出,然后调用pmap_ro_zone_validate_element_dst。
pmap_ro_zone_validate_element_dst ; CODE XREF:ADRL X9, zone_ro_elem_sizeADD X8, X9, W0,UXTW#3LDR W8, [X8,#4] ; elem_size = zone_ro_elem_size[zid]ADRL X10, zone_info.zi_ro_rangeADD X11, X10, #8LDP X10, X11, [X10] ; x10 = start; x11 = endCMP X10, X1CCMP X11, X1, #0, LSB.LS loc_FFFFFFF008494928 ; x10 < va < x11
判断va是否在合法地址范围内,Readonly内存是从zone_info.zi_ro_range专有内存块分配的。
MOV W10, W0LSL X10, X10, #3LDR W9, [X9,X10] ; elem_size1 = zone_ro_elem_size[zid << 3]AND W10, W1, #0x3FFF ; va &= 0x3fffMOV W11, #0x4000SUB W10, W11, W10 ; va = 0x4000 - vaMUL W10, W9, W10 ; va *= elem_size1CMP W10, W9C.CS loc_FFFFFFF008494928 ; va > elem_size1
判断va是否跨page。
UBFX X9, X1, #0xE, #0x20 ; ' ' ; index = (uint43_t)(va >> 0xe)ADRP X10, #qword_FFFFFFF0077ED1D0@PAGE ; zone_info.zi_meta_baseLDR X10, [X10,#qword_FFFFFFF0077ED1D0@PAGEOFF]LSL X9, X9, #4LDRH W9, [X10,X9]AND W9, W9, #0x3FF ; zm_index = (zone_info.zi_meta_base[index << 4] & 0x3ff)CMP W9, W0B.NE loc_FFFFFFF008494928 ; meta->zm_index != zid
判断va对应的Meta指向的zm_index是否与参数zid相等。
SUB X9, X8, X2CMP X9, X3C.CC loc_FFFFFFF0084948D0 ; elem_size - offset > new_data_sizeCMP X8, X2B.LS loc_FFFFFFF0084948FC ; elem_size < offsetLDP X29, X30, [SP,#0x30+var_s0]ADD SP, SP, #0x40 ; '@'RETAB
1.4.2 zalloc_ro_mut_atomic
__attribute__((noinline))uint64_tzalloc_ro_mut_atomic(zone_id_t zid, void *elem, vm_offset_t offset,zro_atomic_op_t op, uint64_t value){value = pmap_ro_zone_atomic_op(zid, (vm_offset_t)elem, offset, op, value);return value;}
1.4.3 zalloc_ro_clear
voidzalloc_ro_clear(zone_id_t zid, void *elem, vm_offset_t offset, vm_size_t size){pmap_ro_zone_bzero(zid, (vm_offset_t)elem, offset, size);}pmap_ro_zone_bzero_ppl ; DATA XREF:BL pmap_ro_zone_validate_element ;MOV X0, X19MOV X1, X21MOV X2, X20BL pmap_ro_zone_lock_phy_pageMOV X0, X19 ; vm_offset_tBL _ml_static_ptovirt_0MOV X1, X20 ; size_tBL _bzero
逻辑与前面类似,只是调用了bzero。
1.5 SAD_FENG_SHUI
如前述,正常分配内存时zone只会返回一个meta结构,但是苹果公司为了增加堆elemments的风水布局,大量使用了随机化技术, 对某些zone,会概率性的生成N(<64)个meta结构,对zone进行了空间扩展,增加了漏洞利用难度。
static voidzone_allocate_va_locked(zone_t z, zalloc_flags_t flags){pages = chunk_pages;guards = 0;runs = 1;#if ZSECURITY_CONFIG(SAD_FENG_SHUI)if (!z->z_percpu && zone_submap_is_sequestered(zsflags)) {pages = atop(ZONE_CHUNK_ALLOC_SIZE);runs = (pages + chunk_pages - 1) / chunk_pages;runs = zalloc_random_uniform32(1, runs + 1);pages = runs * chunk_pages;}static_assert(ZONE_CHUNK_ALLOC_SIZE / 4096 <= 64,"make sure that `runs` will never be larger than 64");#endif
不启用SAD_FENG_SHUI时,meta不使用guard,zone使用的chunk_page不变。开启后,zone的chunk_page会随机变为N倍大小,runs为随机生成的N个meta数目。
#if ZSECURITY_CONFIG(SAD_FENG_SHUI)if (z->z_percpu) {rnum = zalloc_random_uniform32(0, 4 * 128);guards = rnum >= 128;} else if (!zsflags.z_pgz_use_guards && !z->z_pgz_use_guards) {vm_offset_t rest;rnum = zalloc_random_uniform32(0, ZONE_GUARD_SPARSE);guards = (uint32_t)ptoa(pages) / ZONE_GUARD_SPARSE;rest = (uint32_t)ptoa(pages) % ZONE_GUARD_SPARSE;guards += rnum < rest;} else if (ptoa(chunk_pages) >= ZONE_GUARD_DENSE) {rnum = zalloc_random_uniform32(65, 129);guards = runs * rnum / 128;} else {vm_offset_t rest;rnum = zalloc_random_uniform32(0, ZONE_GUARD_DENSE);guards = (uint32_t)ptoa(pages) / ZONE_GUARD_DENSE;rest = (uint32_t)ptoa(pages) % ZONE_GUARD_DENSE;guards += rnum < rest;}assert3u(guards, <=, runs);guard_mask = 0;if (!z->z_percpu && zone_submap_is_sequestered(zsflags)) {uint32_t g = 0;guard_mask |= 1ull << (runs - 1);g++;if ((rnum & 3) == 0) {lead_guard = true;g++;}if (guards > g) {guard_mask |= zalloc_random_bits(guards - g, runs - 1);} else {guards = g;}} else {assert3u(runs, ==, 1);assert3u(guards, <=, 1);guard_mask = guards << (runs - 1);}
上述代码根据zone的类型不同,概率性的判断是否要使用guard page。
if (lead_guard) {meta[0].zm_index = zone_index(z);meta[0].zm_chunk_len = ZM_PGZ_GUARD;meta[0].zm_guarded = true;meta++;}
判断是否需要填入前缀guard page。
for (uint32_t run = 0, n = 0; run < runs; run++) {bool guarded = (guard_mask >> run) & 1;for (uint32_t i = 0; i < chunk_pages; i++, n++) {meta[n].zm_index = zone_index(z);meta[n].zm_guarded = guarded;}if (guarded) {meta[n].zm_index = zone_index(z);meta[n].zm_chunk_len = ZM_PGZ_GUARD;n++;}}
循环N次设置每个meta部分结构。
#if ZSECURITY_CONFIG(SAD_FENG_SHUI)if (__improbable(zone_caching_disabled < 0)) {return zone_scramble_va_and_unlock(z, meta, runs, pages,chunk_pages, guard_mask);}#endif__attribute__((noinline))static voidzone_scramble_va_and_unlock(zone_t z,struct zone_page_metadata *meta,uint32_t runs,uint32_t pages,uint32_t chunk_pages,uint64_t guard_mask){struct zone_page_metadata *arr[ZONE_CHUNK_ALLOC_SIZE / 4096];for (uint32_t run = 0, n = 0; run < runs; run++) {arr[run] = meta + n;n += chunk_pages + ((guard_mask >> run) & 1);}for (uint32_t i = runs - 1; i > 0; i--) {uint32_t j = zalloc_random_uniform32(0, i + 1);meta = arr[j];arr[j] = arr[i];arr[i] = meta;}zone_lock(z);for (uint32_t i = 0; i < runs; i++) {zone_meta_queue_push(z, &z->z_pageq_va, arr[i]);}z->z_va_cur += z->z_percpu ? runs : pages;}
zone_scramble_va_and_unlock函数将每个meta随机进行了置换。
经过一些列操作后, 本来只会分配一个meta, 现在会随机扩展为N个meta,第一个meta前面可能带有guard page, 随后每个meta后面,也可能随机带有guard page,并且虽有meta都进行了随机置换。
除此之外,每个meta对应的element前面还有一个可选的空余区域z_pgz_oob_offs, 以下函数用于总一个zone中取走一个element。
static vm_offset_tzone_element_addr(zone_t z, zone_element_t ze, vm_offset_t esize){vm_offset_t offs = zone_oob_offs(z);return offs + zone_element_base(ze) + esize * zone_element_idx(ze);}
z_pgz_oob_offs是在zone初始化时计算出来的。
zone_tzone_create_ext(const char *name,vm_size_t size,zone_create_flags_t flags,zone_id_t zid,void (^extra_setup)(zone_t)){#if ZSECURITY_CONFIG(SAD_FENG_SHUI)if (flags & ZC_PGZ_USE_GUARDS) {z->z_pgz_oob_offs = (uint16_t)(alloc -z->z_chunk_elems * z->z_elem_size);}#endif}
实际上是把空余的区域利用起来。
#if ZSECURITY_CONFIG(PGZ_OOB_ADJUST)void *zone_element_pgz_oob_adjust(struct kalloc_result kr, vm_size_t elem_size){vm_offset_t addr = (vm_offset_t)kr.addr;vm_offset_t req_size = MAX(roundup(kr.size, KALLOC_MINALIGN), KALLOC_MINALIGN);vm_offset_t end = addr + elem_size;vm_offset_t offs;if (req_size == elem_size ||(end & PAGE_MASK) ||!zone_meta_from_addr(addr)->zm_guarded) {return kr.addr;}offs = elem_size - req_size;zone_meta_from_addr(end)->zm_oob_offs = (uint16_t)offs;return (char *)addr + offs;}#endif
zone_element_pgz_oob_adjust是在kalloc_zone时进行初始化。
除了上述两个防护措施, zone在每次从meta中获取element索引时,也使用了一定的随机化手段。
static vm_offset_tzone_meta_find_and_clear_bit(zone_t zone, struct zone_page_metadata *meta,zalloc_flags_t flags){zone_stats_t zs = zpercpu_get(zone->z_stats);vm_offset_t eidx = zs->zs_alloc_rr + 1;if (meta->zm_inline_bitmap) {eidx = zba_scan_bitmap_inline(zone, meta, flags, eidx);} else {eidx = zba_scan_bitmap_ref(zone, meta, eidx);}zs->zs_alloc_rr = (uint16_t)eidx;return eidx;}
zs->zs_alloc_rr是通过以下函数在zone初始化时设置。
static voidzone_early_scramble_rr(zone_t zone, zone_stats_t zstats){int cpu = cpu_number();zone_stats_t zs = zpercpu_get_cpu(zstats, cpu);uint32_t bits;bits = random_bool_gen_bits(&zone_bool_gen[cpu].zbg_bg,zone_bool_gen[cpu].zbg_entropy, ZONE_ENTROPY_CNT, 8);zs->zs_alloc_rr += bits;zs->zs_alloc_rr %= zone->z_chunk_elems;}
随机生成了一个0到z_chunk_elems的索引。
这里也可以看到, 只是在第一次分配element时使用了一个随机索引,后续会在次索引后继续连续分配!
1.6 zone不可合并
Linux的slab提供了让不同数据类型,但数据大小相同的slab合并一起使用。这将导致UAF漏洞非常容易利用。而IOS的zone是不允许有上述合并行为的。
static zone_tzone_create_find(const char *name,vm_size_t size,zone_create_flags_t flags,zone_id_t *zid_inout){if (flags & ZC_DESTRUCTIBLE) {/** If possible, find a previously zdestroy'ed zone in the* zone_array that we can reuse.*/for (int i = bitmap_first(zone_destroyed_bitmap, MAX_ZONES);i >= 0; i = bitmap_next(zone_destroyed_bitmap, i)) {z = &zone_array[i];if (strcmp(z->z_name, name) || zone_elem_size(z) != size) {continue;}bitmap_clear(zone_destroyed_bitmap, i);z->z_destroyed = false;z->z_self = z;zid = (zone_id_t)i;goto out;}}
zone_create_find选取之前已经分配好的一个zone,只有名字和大小都匹配才符合条件。
1.7 无处不在的安全检查
在zalloc内存分配器里,你会看到各种严格的参数和地址范围检查,这些检查势必带来一定的性能损耗,如果在linux社区肯定会有一群人跳起来职责你。再一次,苹果公司证明安全不影响性能。
zone_page_meta_accounting_panic(zone_t zone, struct zone_page_metadata *meta,const char *kind)zone_meta_double_free_panic(zone_t zone, zone_element_t ze, const char *caller)zone_accounting_panic(zone_t zone, const char *kind)zone_invalid_element_panic(zone_t zone, vm_offset_t addr, bool cache)zone_element_validate(zone_t zone, zone_element_t ze)zone_require_panic(zone_t zone, void *addr)zone_id_require_panic(zone_id_t zid, void *addr)zone_require(zone_t zone, void *addr)zone_id_require(zone_id_t zid, vm_size_t esize, void *addr)zba_chain_corruption_panic(struct zone_bits_chain *a, struct zone_bits_chain *b)zalloc_uaf_panic(zone_t z, uintptr_t elem, size_t size)panic_display_pgz_uaf_info(bool has_syms, vm_offset_t addr)zalloc_ro_mut_validation_paniczone_id_require_ro_paniczone_require_ro
如有侵权请联系:admin#unsafe.sh