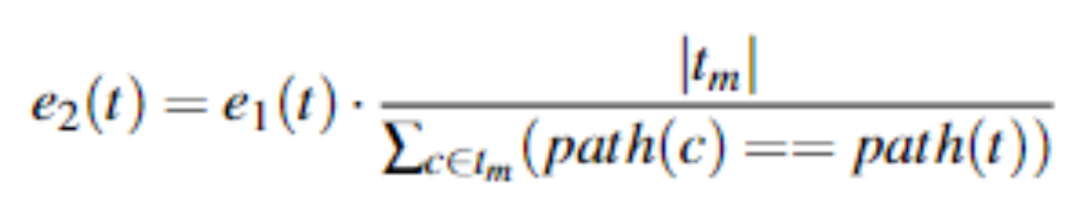
基本信息
原文名称:Stateful Greybox Fuzzing
原文作者:Jinsheng Ba;Marcel Bohme;
Zahra Mirzamomen等
原文链接:https://www.usenix.org/conference
/usenixsecurity22/presentation/ba
发表期刊:USENIX Security Symposium,2022
开源代码:https://github.com/bajinsheng/SGFuzz
一、引言
如果某个漏洞只有在特定状态下才能显现,那么模糊测试工具需要输入一系列特定的事件才能引导协议进入该状态,从而触发漏洞。这类漏洞称之为“状态相关漏洞”。在测试协议实现时,我们往往缺乏一份详尽的正式规范可以参考。缺乏对协议深入了解的情况下,模糊测试工具难以发掘这些状态相关的漏洞。因此,一个主要的挑战是如何在没有明确协议规范的情况下对状态空间进行全面覆盖。对于有状态的软件系统进行模糊测试时,需要整合一套能够识别状态的策略。这种状态识别可能是通过手动指导完成的,也可能基于自动化分析得出的。
在这篇论文的研究中,假设对状态识别的手动注解是可以避免的,具体而言,依赖于一种程序直觉,即协议实现中的状态变量通常体现为枚举类型,其取值(状态名)是由命名常量决定的。在对最广泛使用的开源协议实现的前50名分析中,作者发现每一种实现都采用了带有命名常量的状态变量(如 INIT、READY 等容易理解的命名),以表征当前的状态。基于此,作者提出一种自动识别这些状态变量,并追踪模糊测试过程中赋予它们的值的序列,以此构造一张探索状态空间的“路线图”。
二、概述
SGFuzz是一种状态灰盒模糊测试方法,专为测试需要处理复杂状态逻辑的协议实现而设计。该方法的核心在于自动识别和跟踪协议中的状态变量,这些变量通常以枚举类型出现,反映了协议的不同状态。通过监测这些状态变量在程序执行过程中的变化,SGFuzz能够构建出一个状态转换树(STT),这是一个动态生成的结构,它描绘了协议实现的状态空间地图。
利用STT,SGFuzz的模糊测试算法可以更智能地选择输入种子,优先考虑那些可能增加状态空间覆盖的种子输入。这种方法不仅提高了模糊测试的效率,而且能够更深入地覆盖状态空间,从而增加发现潜在漏洞的机会。
实验结果证明,SGFuzz在多个开源协议实现中成功地发现了新的漏洞。此外,与基准模糊测试器LIBFUZZER相比,SGFuzz在状态转换序列的覆盖方面表现出色,显示了其在状态空间探索方面的优势。
三、离线状态变量识别
状态变量是用来追踪程序中的当前状态,它们通常被定义为枚举类型或通过预处理器指令(如#define)定义的命名常量。在现有技术中,通常需要手动编写代码以从服务器响应中提取状态信息,但作者提出了一种全自动的方法来识别这些变量。通过比较协议规范和实现中的状态,开发者能够保持它们之间的直接映射。状态转换通过为状态变量分配新的命名常量来实现,而基于状态的逻辑则通过使用条件判断结构,如switch或if语句,来实现。作者特别指出,状态变量的识别是通过搜索枚举类型的变量来完成的,因为枚举类型允许将一系列的命名常量与特定的数值相关联。
如表1中所见,并非所有枚举类型的变量都是状态变量。第二类是代表所有可能的响应或错误代码的枚举类型。第三类是代表所有可能的配置选项的配置变量的枚举类型。然而,在实践中,这种启发式方法仍然非常有效。响应和错误代码变量已经被的AFLNET间接用于状态识别。配置变量通常只在服务器启动时(即在开始记录每个消息序列的状态转换之前)或会话开始时被赋值一次。如果在会话开始时记录配置变量,它们会出现在每个状态转换序列的开头,并且永远不会被识别为“稀有”的状态,所以对构建状态转换树(STT)的影响并不大。
表1 枚举类型的变量分类及其对状态转换树的影响
四、状态转换树数据结构
状态转换树(State Transition Tree,STT)被描述为一种数据结构,用于表示程序执行期间输入序列所经历的状态转换。STT的每个节点代表程序执行过程中状态变量的一个值。节点之间的边表示状态变量值的变化,即状态转换。从全局角度来看,树有一个根节点代表初始状态,从根节点到叶节点的每条路径代表程序执行过程中的一个独特的状态转换序列。STT是在模糊测试期间逐渐构建的,所有观察到的状态变量值序列都存储在同一个STT中,这样就可以表示整个已经被模糊测试探索过的状态空间。如图1,对于HTTP2协议的实现,STT将记录从接收请求头(RECV_HEADERS)到接收请求体(RECV_BODY)、发送响应头(SEND_HEADERS)、发送响应体(SEND_BODY)直到流结束(END_STREAM)的状态转换。如果请求中有格式错误的数据,状态将直接转换到流结束状态(END_STREAM),如STT的左侧分支所示。另一种情况是请求体为空,这时会经过右侧分支,绕过接收请求体状态(RECV_BODY)。STT通过记录状态变量在程序执行过程中被赋予的值序列来构建,从而捕获了状态转换的顺序。
图1 从HTTP2协议的实现中提取的状态转换树
五、构建状态转换树
构建STT的过程包括在编译时使用Python脚本插桩,将runtime调用注入协议实现的二进制文件中,以便在状态变量赋予新值时捕获状态转换。这样,在模糊测试期间,runtime组件可以记录状态变量值的变化,逐步构建出STT。STT是一个全局数据结构,它捕获并共享所有模糊生成输入序列中状态变量值的序列。多线程环境下,runtime使用互斥锁保护更新STT的代码,以防止并发问题。为了有效管理STT的大小,提供了限制单次执行中状态重复的最大数量的选项。如果某条路径上的状态重复超过设定的限制,该路径上随后的状态转换将被忽略,从而使得在模糊测试期间,状态转换能够以树的形式而非图的形式进行管理。
关于SGFuzz插桩时的Python脚本,SGFuzz使用一个独立的Python脚本作为插桩组件,该脚本是静态的,不依赖于任何编译器基础设施。该脚本使用正则表达式在协议实现的代码中查找所有状态变量被赋予新值的指令,并在每个指令之前注入一个调用runtime的函数。注入的函数将状态变量的名称和命名常量的值传递给runtime,runtime根据这些信息逐渐构建状态转换树。为了使插桩更灵活和准确,该脚本还提供了一个选项,允许用户屏蔽一些从离线状态变量识别中提取出的变量。作者没有使用LLVM来插桩,是因为在LLVM中间语言(LLVM-IR)中,枚举值将被整型常数值所取代。
六、Stateful Greybox Fuzzing Algorithm
SGFuzz在运行时递增地构建STT,并按照以下方式使用它:
1.生成的输入如果能增加STT的覆盖率,则添加到种子库中。
2.在种子库中,SGFuzz优先考虑那些有更大潜力增加STT覆盖率的种子。
3.在选定的种子中,SGFuzz优先处理与新添加的STT节点关联的字节,这些节点有更大的潜力增加STT的覆盖率。
如图2所示,算法1展示了该模糊测试算法的一般工作流程。作者将这一算法实现在LIBFUZZER中,并将模糊器命名为SGFuzz。从一个初始种子库T开始,直到达到超时或用户中止测试活动,以下步骤会不断重复。首先,SGFuzz根据能量分布E采样t,这代表了种子库中每个种子被选中的可能性(choose_next)。然后对选中的种子t进行变异(mutate),以生成新的输入t'。接下来在t'上执行协议实现并更新STT。如果t'导致崩溃,SGFuzz返回导致崩溃的输入;否则,如果t'执行了新的代码分支或新的STT节点(is_interesting),则将t'添加到种子库T中,若不是则丢弃t'。每当添加新的STT节点时,SGFuzz识别输入t'中对新STT节点覆盖贡献的字节(identify_bytes),并更新当前种子库中所有种子ti ∈ T的能量Eti(assign_energy)。在算法1中,作者更改的LIBFUZZER部分用红色高亮显示。
图2 算法1-Stateful Greybox Fuzzing Algorithm
(1)状态覆盖反馈
将生成输入添加到种子语料库中,这些输入将STT中的新节点用作原始分支覆盖反馈的扩展(算法1中的is_interesting)。其基本原理是最大化STT数据结构的覆盖率,从而最大化状态空间的状态覆盖率。STT中的每个新节点代表当前状态变量值序列中的新值,表示在当前状态转移序列下的新状态。与代码覆盖引导的灰盒模糊测试一样,会增加状态覆盖的输入也会被添加到种子语料库中。
(2)能量调度
将更多的能量分配给具有更大潜力导致新状态的种子(算法1中的assign_energy)。与优先考虑执行稀有代码块的输入相比,作者的算法还将更多的能量分配给执行与有效协议行为相对应的有效状态转换的种子。首先,作者将更多的能量分配给在STT中遍历很少访问的节点的种子。作者在STT中的每个节点上设置一个名为hit-count的属性,以记录遍历该节点的输入次数。作者预计STT中hit-count较低的节点在其“邻域”中有更多的未探索状态。在给定STT的情况下,作者认为属于STT的节点n如果其hit-count低于整体平均水平,则是稀有的。
其中hits(n)返回节点n的命中次数。path(t)表示在STT中由输入t遍历的节点集合。给定语料库T中的输入t,能量调度将能量e1(t)分配给t,其等于在t上程序执行过程中访问的稀有节点比例乘以t的原始能量之积再与t的原始能量相加,其中e'(t)是t的原始能量。
将更多的能量分配给那些后代更可能通过STT采取不同路径的种子。并不是所有的状态转换都同样重要,而有效的状态转换更具吸引力。作者的直觉是,与预期协议行为相对应的有效状态转换通常很容易被突变到其他无效状态转换,这些转换代表了协议的错误处理。这也是以前的有状态灰盒模糊测试技术的挑战。因此,作者识别这种类型的种子并为其分配更多的能量。给定一个输入t和一个从t突变而来的输入tm集合,作者计算其后代中与path(t)遍历相同路径的倒数比例。作者将能量调度e2(t)扩展如下:
为了避免分配过多的能量,作者将能量调度e(t)限制在原始能量e'(t)的十倍以内(经验证明这个数字比其他数字更好)。
(3)模糊单个字节
对种子中可能对增加状态(STT)覆盖率影响更大的部分进行模糊测试。当选择输入种子进行突变时,根据字节的优先级选择要突变的单个字节。如果字节被认为对STT的覆盖范围的影响更大,则它们具有更高的优先级(算法1中的mutate和identify_bytes)。如果针对突变输入的程序执行触发STT中的新节点,因此,该输入首次导致新未访问节点被访问,它可能具有很大的潜力来增加状态空间的覆盖率。作者的想法是识别哪些字节在这种输入中的突变导致了STT覆盖率的增加。一旦确定,这些字节将被分配更高的优先级以进行选择。这使得模糊测试更加高效,因为它使新创建节点的“邻居”状态的早期探索成为可能,这些状态尚未被访问。给定输入t和一个从t衍生出的突变输入t',如果程序执行在输入t'上创建STT中的新节点,t'将保存在SGFuzz中。然后SGFuzz计算t和t'之间的字节差集diff(t,t'),并记录t'新添加的STT节点N。如果|N|> 0,将突变范围注释为Rt'=diff(t,t'),否则将Rt'设置为整个种子t'(算法1中的identify_bytes)。稍后,在选择t'进行模糊测试时(算法1中的mutate),只突变Rt'范围内的字节。如果没有带来任何有趣的行为(算法1中的is_interesting),将逐渐扩大Rt',直到它覆盖整个种子t'。这有助于构建一个高效的模糊测试活动。
七、实验设计及结果
从两个成熟的基准PROFUZZBENCH和FUZZBENCH中选择了8个目标程序进行实验,如表2所示。其中因为PROFUZZBENCH需要套接字通信,所以使用netdriver库使其适用于内存模糊器。遗憾的是,netdriver不支持UDP协议和fork系统调用,所以作者选择了PROFUZZBENCH中所有兼容内存模糊器的程序。
表2 用于比较的协议实现
作者将这个有状态的灰盒模糊测试方法集成到了LIBFUZZER中,并将其命名为SGFuzz。在实验中,SGFuzz与作为基准的LIBFUZZER以及AFLNET和IJON进行了对比。由于IJON不支持FUZZBENCH和PROFUZZBENCH,为了便于公平比较,作者在LIBFUZZER中重新实现了IJON,并移植了其注释功能ijon_push_state,以便IJON基于状态反馈。为了最大化IJON的好处,作者假定人工注释者会注释SGFuzz识别的相同状态变量。此外,AFLNET不支持FuzzBench。
所有的模糊测试器都使用等效的设置和构建过程集成到FUZZBENCH和PROFUZZBENCH中。所有模糊测试器都提供相同的设置、环境、种子和资源。对于所有的模糊测试器,都启用了AddressSanitizer来检测内存损坏漏洞。PROFUZZBENCH使用gcov工具,FUZZBENCH使用llvm-cov工具,以15分钟间隔测量模糊测试活动中覆盖的边数量。
(1)实验1:测试状态转换覆盖率
平均而言,SGFuzz比LIBFUZZER多覆盖了33倍的状态转换序列,比IJON多15倍,比AFLNET多260倍。说明通过STT跟踪状态空间,SGFuzz能够覆盖更多的状态空间。
表3 20次23小时实验的平均状态转换覆盖率
(2)实验2:测试边覆盖率
平均而言,SGFuzz的边覆盖率比LIBFUZZER高2.20%,比IJON高4.41%,比AFLNET高38.73%。SGFuzz实现了比LIBFUZZER速度快2倍的相同边覆盖。
表4 20次23小时实验的平均边覆盖率(左)和平均达到覆盖率时间(右)
(3)实验3:测试识别状态的有效性
虽然平均32%的识别出的枚举类型变量不是实际状态变量,但在23小时构建的STT中平均99.5%的节点指的是实际状态变量的值。这可以通过 STT 跟踪变量值的变化来解释。
表5 [左]识别出的枚举类型变量(All)和实际状态变量(State)的数量,[右]23小时构建的STT中的节点(All)和状态相关节点(State)的数量
为了评估真实状态变量的状态覆盖情况,作者记录了实验中状态变量不同值的个数,如表6所示。平均而言,SGFuzz在23小时覆盖的不同状态变量值比LIBFUZZER多88.98%。
表6 23小时的实验中观察到的不同状态变量值的数量
(4)实验4:测试发现bug的有效性
平均而言,与LIBFUZZER和IJON相比,SGFuzz大约快2倍地暴露出具有状态的bug,而与AFLNET相比,则大约快155倍。此外,对于无状态的bug,SGFuzz相较于LIBFUZZER和IJON显示出轻微的优势,作者发现这些无状态的bug通常出现在与状态转换一起执行但不依赖于状态转换的函数中,例如,在状态转换之前必须执行的消息解析函数。作者的这个算法更有效地探索了状态空间,也促进了无状态bug的发现。
表7 20次23小时实验暴露现有bug的平均时间
八、SGFuzz和AFLNET的区别
1.SGFuzz是基于LIBFUZZER的状态灰盒模糊测试工具,而AFLNET是基于AFL的状态模糊测试工具。
2.SGFuzz使用枚举类型变量(包括响应码)来自动识别和捕获协议状态空间,而AFLNET需要手动编写协议驱动程序来从服务器响应中提取状态信息(响应码)。
3.SGFuzz使用状态转换树(STT)来捕获和探索协议状态空间,STT能够反映协议状态的细粒度变化,保留状态转换的顺序信息,而不是仅仅关注状态之间的可达性。STT能够更好地反映协议状态的动态变化。SGFuzz根据STT的覆盖情况来选择和变异种子,以及优先变异影响状态转换的字节。AFLNET则使用的是状态转换图(STG),它忽略了状态转换的顺序信息,只关注状态之间的可达性。STG能够更好地反映协议状态的静态结构。
4.SGFuzz能够在内存中运行协议实现,从而提高性能并累积隐式状态,而AFLNET需要在每次消息交换后重启协议实现,从而清除隐式状态。
参考文献
[1]libfuzzer-a ibrary for coverage-guided fuzz testing.https://llvm.org/docs/LibFuzzer.html, 2020.
[2]Michal Zalewski. American Fuzzy Lop (2.52b). http://lcamtuf.coredump.cx/afl, 2019.
[3]Cornelius Aschermann, Sergej Schumilo, Ali Abbasi, and Thorsten Holz. Ijon: Exploring deep state spaces via fuzzing. In IEEE Symposium on Security and Privacy, 2020.
[4]Cornelius Aschermann, Sergej Schumilo, Tim Blazytko, Robert Gawlik, and Thorsten Holz. Redqueen: Fuzzing with input-to-state correspondence. In NDSS, volume 19, pages 1-15, 2019.
[5]Joeri De Ruiter and Erik Poll. Protocol state fuzzing of tls implementations. In 24th USENIX Security Symposium, pages 193–206, 2015.
[6]Shuitao Gan, Chao Zhang, Peng Chen, Bodong Zhao, Xiaojun Qin, Dong Wu, and Zuoning Chen. Greyone: Data flow sensitive fuzzing. In 29th USENIX Security Symposium, pages 2577–2594, 2020.
[7]Roberto Natella and Van-Thuan Pham. Profuzzbench: A benchmark for stateful protocol fuzzing. In Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, 2021.
—END—
如有侵权请联系:admin#unsafe.sh