2024-3-5 18:19:53 Author: mp.weixin.qq.com(查看原文) 阅读量:10 收藏
项目主页:https://ingra14m.github.io/Deformable-Gaussians/
论文链接:https://arxiv.org/abs/2309.13101
代码:https://github.com/ingra14m/Deformable-3D-Gaussians
单目动态场景(Monocular Dynamic Scene)是指使用单眼摄像头观察并分析的动态环境,其中场景中的物体可以自由移动。单目动态场景重建对于理解环境中的动态变化、预测物体运动轨迹以及动态数字资产生成等任务至关重要。
随着以神经辐射场(Neural Radiance Field, NeRF)为代表的神经渲染的兴起,越来越多的工作开始使用隐式表示(implicit representation)进行动态场景的三维重建。尽管基于NeRF的一些代表工作,如D-NeRF,Nerfies,K-planes等已经取得了令人满意的渲染质量,他们仍然距离真正的照片级真实渲染(photo-realistic rendering)存在一定的距离。我们认为,其根本原因在于基于光线投射(ray casting)的NeRF管线通过逆向映射(backward-flow)将观测空间(observation space)映射到规范空间(canonical space)无法实现准确且干净的映射。逆向映射并不利于可学习结构的收敛,使得目前的方法在D-NeRF数据集上只能取得30+级别的PSNR渲染指标。
为了解决这一问题,我们提出了一种基于光栅化(rasterization)的单目动态场景建模管线,首次将变形场(Deformation Field)与3D高斯(3D Gaussian Splatting)结合实现了高质量的重建与新视角渲染。实验结果表明,变形场可以准确地将规范空间下的3D高斯前向映射(forward-flow)到观测空间,不仅在D-NeRF数据集上实现了10+的PSNR提高,而且在相机位姿不准确的真实场景也取得了渲染细节上的增加。
该研究的论文《Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction》已被计算机视觉顶级国际学术会议 CVPR 2024接收。值得一提的是,该论文是首个使用变形场将3D高斯拓展到单目动态场景的工作,并且在公开数据集上取得了SOTA结果。
相关工作
动态场景重建一直以来是三维重建的热点问题。随着以NeRF为代表的神经渲染实现了高质量的渲染,动态重建领域涌现出了一系列以隐式表示作为基础的工作。D-NeRF和Nerfies在NeRF光线投射管线的基础上引入了变形场,实现了鲁棒的动态场景重建。TiNeuVox,K-Planes和Hexplanes在此基础上引入了网格结构,大大加速了模型的训练过程,渲染速度有一定的提高。然而这些方法都基于逆向映射,无法真正实现高质量的规范空间和变形场的解耦。
3D高斯泼溅是一种基于光栅化的点云渲染管线。其CUDA定制的可微高斯光栅化管线和创新的致密化使得3D高斯不仅实现了SOTA的渲染质量,还实现了实时渲染。Dynamic 3D高斯首先将静态的3D高斯拓展到了动态领域。然而,其只能处理多目场景非常严重地制约了其应用于更通用的情况,如手机拍摄等单目场景。
研究思想
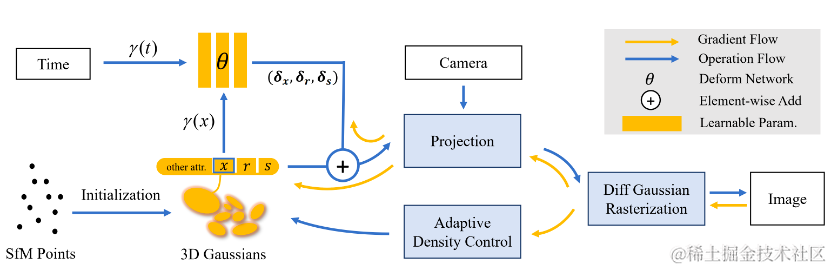
Deformable-GS的核心在于将静态的3D高斯拓展到单目动态场景。每一个3D高斯携带位置,旋转,缩放,不透明度和SH系数用于图像层级的渲染。根据3D高斯alpha-blend的公式我们不难发现,随时间变化的位置,以及控制高斯形状的旋转和缩放是决定动态3D高斯的决定性参数。然而,不同于传统的基于点云的渲染方法,3D高斯在初始化之后,位置,透明度等参数会随着优化不断更新。这给动态高斯的学习增加了难度。
在本次研究中,我们创新性地提出了变形场与3D高斯联合优化的动态场景渲染框架。我们将COLMAP或随机点云初始化的3D高斯视作规范空间,随后通过变形场,以规范空间中3D高斯的坐标信息作为输入,预测每一个3D高斯随时间变化的位置 和形状参数 。利用变形场,我们可以将规范空间的3D高斯变换到观测空间用于光栅化渲染。这一策略并不会影响3D高斯的可微光栅化管线,经过其计算得到的梯度可以用于更新规范空间3D高斯的参数。此外,引入变形场有利于动作幅度较大部分的高斯致密化。这是因为动作幅度较大的区域变形场的梯度也会相对较高,从而指导相应区域在致密化的过程中得到更精细的调控。即使规范空间3D高斯的数量和位置参数在初期也在不断更新,但实验结果表明,这种联合优化的策略可以最终得到鲁棒的收敛结果。大约经过20000轮迭代,规范空间的3D高斯的位置参数几乎不再变化。
在真实场景中,我们发现真实场景的相机位姿往往不够准确,而动态场景更加剧了这一问题。这对于基于神经辐射场的结构来说并不会产生较大的影响,因为神经辐射场基于多层感知机(MLP),是一个非常平滑的结构。但是3D高斯是基于点云的显式结构,略微不准确的相机位姿很难通过高斯泼溅得到较为鲁棒地矫正。因此为了缓解这个问题,我们创新地引入了退火平滑训练(Annealing Smooth Training,AST)。该训练机制旨在初期平滑3D高斯的学习,在后期增加渲染的细节。这一机制的引入不仅提高了渲染的质量,而且大幅度提高了时间插值任务的稳定性与平滑性。
图2展示了该研究的流程图,详情请参见论文原文。
结果展示
该研究首先在动态重建领域被广泛使用的D-NeRF数据集上进行了合成数据集的实验。从图3的可视化结果中不难看出,Deformable-GS相比于之前的方法有着非常巨大的渲染质量提升。
我们方法不仅在视觉效果上取得了大幅度的提高,定量的渲染指标上也有着对应的支持。值得注意的是,我们发现D-NeRF数据集的Lego场景存在错误,即训练集和测试集的场景具有微小的差别。这体现在Lego模型铲子的翻转角度不一致。这也是为什么之前方法在Lego场景的指标无法提高的根本原因。为了实现有意义的比较,我们使用了Lego的验证集作为我们指标测量的基准。
我们在全分辨率(800x800)下对比了SOTA方法,其中包括了CVPR 2020的D-NeRF,Sig Asia 2022的TiNeuVox和CVPR2023的Tensor4D,K-planes。我们的方法在各个渲染指标(PSNR、SSIM、LPIPS),各个场景下都取得了大幅度的提高。
我们的方法不仅能够适用于合成场景,在相机位姿不够准确的真实场景也取得了SOTA结果。如图5所示,我们在NeRF-DS数据集上与SOTA方法进行了对比。实验结果表明,即使我们的方法没有对高光反射表面进行特殊处理,我们依旧能够超过专为高光反射场景设计的NeRF-DS,取得了最佳的渲染效果。
虽然MLP的引入增加了渲染开销,但是得益于3D高斯极其高效的CUDA实现与我们紧凑的MLP结构,我们依旧能够做到实时渲染。在3090上D-NeRF数据集的平均FPS可以达到85(400x400),68(800x800)。
此外,该研究还首次应用了带有前向与反向深度传播的可微高斯光栅化管线。如图6所示,该深度也证明了Deformable-GS也可以得到鲁棒的几何表示。深度的反向传播可以推动日后很多需要使用深度监督的任务,例如逆向渲染(Inverse Rendering),SLAM与自动驾驶等。
火山引擎多媒体实验室简介
火山引擎多媒体实验室是字节跳动旗下的研究团队,致力于探索多媒体领域的前沿技术,参与国际标准化工作,其众多创新算法及软硬件解决方案已经广泛应用在抖音、西瓜视频等产品的多媒体业务,并向火山引擎的企业级客户提供技术服务。实验室成立以来,多篇论文入选国际顶会和旗舰期刊,并获得数项国际级技术赛事冠军、行业创新奖及最佳论文奖。
火山引擎是字节跳动旗下的云服务平台,将字节跳动快速发展过程中积累的增长方法、技术能力和工具开放给外部企业,提供云基础、视频与内容分发、大数据、人工智能、开发与运维等服务,帮助企业在数字化升级中实现持续增长。
如有侵权请联系:admin#unsafe.sh