2024-3-5 18:19:53 Author: mp.weixin.qq.com(查看原文) 阅读量:6 收藏
无参视频质量评估 (Blind Video Quality Assessment,BVQA) 在评估和改善各种视频平台并服务用户的观看体验方面发挥着关键作用。当前基于深度学习的模型主要以下采样/局部块采样的形式分析视频内容,而忽视了实际空域分辨率和时域帧率对视频质量的影响,随着高分辨率和高帧率视频投稿逐渐普及,特别是跨分辨率/帧率视频转码档位画质评估场景中,这种影响变得更加不可忽视。在本文中,我们提出了一种模块化 BVQA 模型,以及一种训练该模型以提高其模块化性的方法。我们的模型包括基础质量预测模块、空域矫正模块和时域矫正模块,分别显式地响应视频质量的视觉内容和失真、空域分辨率和时域帧率变化情况。我们用提出的模块化BVQA模型在专业生成的内容和用户生成的内容视频数据库上进行了大量实验。实验表明,我们的质量模型实现了优于当前方法或相近的性能。此外,模块化的模型为分析现有视频质量数据库的空间和时间复杂性提供了机会。最后,我们的 BVQA 模型可以轻量高效地添加其他与质量相关的视频属性,例如动态范围和色域作为额外的矫正模块。
背景
多年来,研究人员从心理物理学和感知研究中收集了大量证据,证明更高的空域分辨率和更高的帧速率对视频主观画质有积极的影响。具体而言,感知质量取决于视频内容,特别是空域和时域复杂性。针对这些主观发现,早期的知识驱动的BVQA模型直接将空域分辨率和帧速率参数作为压缩视频质量预测的输入的一部分。尽管这种方法非常简单,但这些视频属性参数与内容和失真无关,因此它们与感知的视频质量不太相关。
基于卷积神经网络(CNN)的数据驱动的 BVQA 方法面临的计算问题十分明显。它们几乎没有尝试评估全尺寸视频,主要原因是计算复杂度很高,尤其是在处理高分辨率和帧速率的视频时,面临的挑战更大。此外,由于视频质量数据集规模较小,许多基于 CNN 的 BVQA 方法依赖于对象识别任务的预训练模型,这些模型通常需要小且固定大小的输入。因此,视频需要在空域上调整大小,并在时域上进行二次采样。在空域中处理视频的传统方法如图1所示,在时域中处理视频的传统方法如图2所示。
图 1. 在空域视图中处理视频的传统方法。(a) 代表来自 Waterloo IVC 4K 的具有相同内容但不同空域分辨率的两个视频。(b) 在不保持宽高比的情况下调整视频大小,与视频质量相关的局部纹理可能会受到影响。(c) 调整视频大小,同时保留纵横比并将其裁剪为固定大小,无论实际空域分辨率如何,都会产生几乎相同的输入。(d) 裁剪视频会缩小视野并导致不同空域分辨率的内容覆盖范围不同。
图.2 来自 LIVE-YT-HFR 的两个视频序列,具有相同的内容,但是时域帧率不同。当根据帧速对帧进行二次采样时,生成的帧是相同的。此外,高达 120 fps 的极高帧速率对端到端 VQA 模型提出了重大挑战。
方法
为了可靠地评估具有丰富内容和失真多样性以及多种空域分辨率和帧速率的数字视频质量,我们提出了一种模块化 BVQA 模型。我们的模型由三个模块组成:基础质量预测模块、空域矫正模块和时域矫正模块,分别响应视频质量中的视觉内容和失真、空域分辨率和帧速率变化。基础质量预测模块将一组稀疏的空域下采样关键帧作为输入,并生成一个标量作为质量分数。空域矫正模块依靠浅层 CNN 来处理实际空域分辨率下关键帧的拉普拉斯金字塔,并计算缩放和移位参数来校正基础质量得分。类似地,时域矫正模块依靠轻量级 CNN 以实际帧速率处理以关键帧为中心的空域下采样视频块,并计算另一个缩放和移位参数以进行质量得分校正。为了增强模型的模块化,我们在训练期间引入了 dropout 策略。在每次迭代中,我们以预先指定的概率随机丢弃空域和/或时域整流器。这种训练策略鼓励基础质量预测模块作为 BVQA 模型独立运行,并且在配备矫正模块时会表现更好。
图3. 所提出模型总体结构。基础质量预测模块采用一组稀疏的空域下采样关键帧作为输入,生成表示为 的基础质量值。空域矫正模块采用从实际空域分辨率的关键帧导出的拉普拉斯金字塔,计算缩放参数 和移位参数 来校正基础质量。时域校正模块利用以实际帧速率的关键帧为中心的视频块的特征来计算另一个缩放参数 和移位参数 以进行质量校正。空域和时域矫正模块可以使用模块化方法协同组合,其中利用尺度参数的几何平均值和移位参数的算术平均值。
实验结果
为了评估空域整流器的性能,我们采用了 BVI-SR和 Waterloo IVC 4K,重点研究不同空域分辨率对视频质量的影响。为了评估时域整流器的有效性,我们利用 BVI-HFR和 LIVE-YT-HFR,它们专门用于分析不同帧速率对视频质量的影响。这四个数据集都是PGC(Professionally-Generated Content,专业生成的内容)数据集。我们还使用八个 UGC (User-Generated Content,用户生成的内容)数据库进一步验证了我们提出的模型的普遍性。这些数据库包含各种内容类型、视觉扭曲、空域分辨率和时域帧率。表1 中提供了这些数据库的全面介绍。
PGC数据集结果
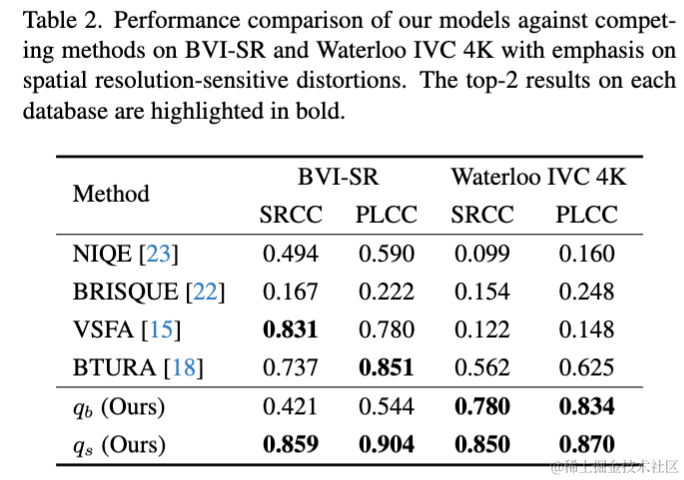
表2和表3展示了4个PGC数据集的结果。可以看出空域矫正模块和时域矫正模块可以分别有效地感知空域分辨率和时域帧率对视频质量带来的影响,并很好地对基础质量分数进行矫正。
UGC数据集结果
表4和表5展示了8个UGC数据集的结果。可以看出两个矫正模块的集成显着增强了八个 UGC 数据库的性能,与当前最优模型相比也展示了具有竞争力的结果。此外,包含这两个矫正模块可以实现有效的泛化,证明它们对提高预测视频质量有突出贡献。此外,我们的模型的模块化设计提供了对常见 UGC 数据库中主要失真类型的全面理解。
多媒体实验室简介
火山引擎多媒体实验室是字节跳动旗下的研究团队,致力于探索多媒体领域的前沿技术,参与国际标准化工作,其众多创新算法及软硬件解决方案已经广泛应用在抖音、西瓜视频等产品的多媒体业务,并向火山引擎的企业级客户提供技术服务。实验室成立以来,多篇论文入选国际顶会和旗舰期刊,并获得数项国际级技术赛事冠军、行业创新奖及最佳论文奖。
火山引擎是字节跳动旗下的云服务平台,将字节跳动快速发展过程中积累的增长方法、技术能力和工具开放给外部企业,提供云基础、视频与内容分发、大数据、人工智能、开发与运维等服务,帮助企业在数字化升级中实现持续增长。
如有侵权请联系:admin#unsafe.sh