背景
随着相关技术和应用的发展,比如超高清屏幕、虚拟现实(VR)等沉浸式体验的增加,用户对超高分辨率图像和视频的需求变得越来越强烈。在这些场景中,图像的质量和清晰度对于提供最佳的用户体验至关重要。超高分辨率不仅能提供更清晰、更真实的视觉效果,还能在一定程度上增强人们的互动和沉浸感,在一些VR场景中我们需要8K甚至16K的才可以满足需求。然而要生成或者处理这些超高分辨率的内容,对算力的要求也是与日增长,对相关算法提出了挑战。
超分辨率是一个经典的计算机底层视觉问题,该问题要解决的是通过低分辨率的图像输入,获得高分辨率的图像输出。目前该领域的算法模型主要是有CNN以及Transformer两大类别,考虑到实际的应用场景,超分的一个细分领域方向是算法的轻量化。在上述提到的超高分辨率的场景,超分算法的算力消耗问题变得尤为关键。基于此,本文提出了一种名为CAMixerSR的超分框架,可以做到内容感知,通过对Conv和Self-Attention的分配做到计算量的大幅优化。
论文地址:http://arxiv.org/abs/2402.19289
方法
我们在对内容进行分块并且根据处理的难易程度分成了简单、中等、困难三个类型,并且使用不同FLOPS的计算单元,Conv以及SA +Conv两种类型进行比较,发现对于简单的模块我们可以利用较少的FLOPS进行计算,并且可以得到较为不错的PSNR结果,只有在中等以及困难的分块内容中,SA+Conv的效果优势才较为明显。通过这个实验我们发现,如果对内容进行分块并且动态调整优化处理策略,有可能在保持性能的同时,大幅降低FLOPS。
上图是我们方案的整体流程图,可以看到,我们的方案分成了三个部分,包括Predictor模块,Self-Attention模块以及Convolution模块。其中的Predictor模块是基于局部条件以及全局条件以及对应的线性位置编码函数,通过该模块,我们可以输出Offsets Maps、Mixer Mask、Spatial Attention、Channel Attention, 这些信息在Self-Attention模块以及Convolution模块的后续计算中进行使用。CAMixerSR中网络的主体模块是基于SwinIR-light进行优化。对于复杂区域,我们使用offsets map来进行更高效的attention计算,并且将输入和V分成了简单和困难两种分块,从而得到对应的Q和K,并且将他们分别进行计算,得到attention部分的V。Convolution模块我们使用depth-wise进行计算,将Self-Attention的结果合并后即可得到我们最后的输出结果。
实验
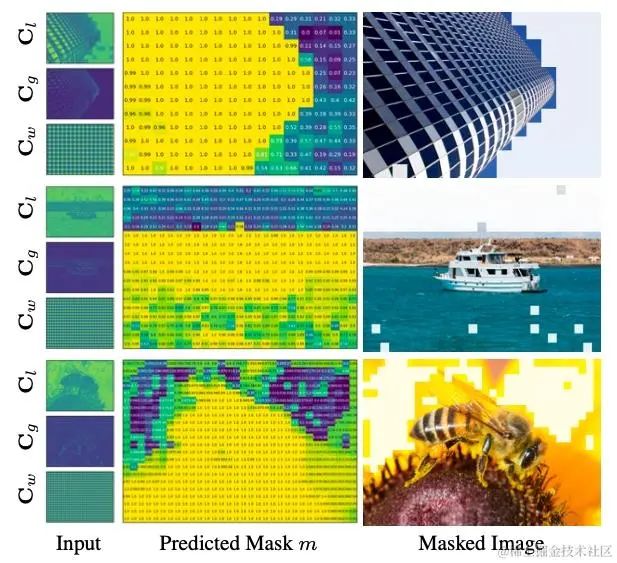
图2显示了我们的Predictor模块的输出结果,可以看到在很多的场景里,不同的区域内容有较为大的差异,并且我们的算法可以精准预测出分块的类型。
表2和表3是CAMixerSR与之前高性能超分在超高分辨率数据集上做的实验对比,我们可以看到,在多个数据集(F2K、Tesk2K、Tesk4K、Tesk8K)上,相比经典的Transformer based超分方案SwinIR-light,CAMixerSR都有比较大的优势,在经过我们的方案优化后,可以做到PSNR接近的情况下节约将近一半的FLOPS以及参数量Params。
除了超大分辨率的场景,我们的方案在一些通用场景下同样有不错的性能优势,表3中我们在一些常见的超分测试集上和一些常见的高性能超分方案进行了测试。
球面内容是一个重要的超高分辨率场景,我们在两个全景超分数据集上进行了测试,甚至不需要通过球面数据集进行训练,仅进行测试的情况下同样发现我们的方案在PSNR效果以及性能上都超过了过去的方案。在这项实验中可以表明CAMixserSR在沉浸式场景有比较大的收益潜力。
火山引擎多媒体实验室简介
火山引擎多媒体实验室是字节跳动旗下的研究团队,致力于探索多媒体领域的前沿技术,参与国际标准化工作,其众多创新算法及软硬件解决方案已经广泛应用在抖音、西瓜视频等产品的多媒体业务,并向火山引擎的企业级客户提供技术服务。实验室成立以来,多篇论文入选国际顶会和旗舰期刊,并获得数项国际级技术赛事冠军、行业创新奖及最佳论文奖。
火山引擎是字节跳动旗下的云服务平台,将字节跳动快速发展过程中积累的增长方法、技术能力和工具开放给外部企业,提供云基础、视频与内容分发、大数据、人工智能、开发与运维等服务,帮助企业在数字化升级中实现持续增长。
如有侵权请联系:admin#unsafe.sh