
2024-3-14 00:18:29 Author: securityboulevard.com(查看原文) 阅读量:13 收藏

With the explosion of large language model (LLM) use, everyone is rushing to apply LLMs to their specific industry and it’s the same for information security. While LLMs have a huge range of applications in the security domain, we’re going to focus on one specific use case: answering questions about files downloaded from a command and control (C2) agent.
Full disclosure: I’m not a ML/AI/LLM/prompt/etc. engineer, I’ve just enjoyed learning about these topics and building some implementations! I’m sure there are countless mistakes made and lots of possible improvements — I’m open to any/all feedback.
If you want an LLM to answer questions about information it wasn’t trained on (e.g., internal tradecraft guides or documents downloaded from a target network), there are a few options. You can “fine-tune” a model over your existing document stores. “Large language model (LLM) fine-tuning is the process of taking pre-trained models and further training them on smaller, specific datasets to refine their capabilities and improve performance in a particular task or domain.” TL;DR this encompasses constructing a dataset that is used for abbreviated training runs of an existing model, which allows the model to internalize information about the data you fine-tuned it on. Fine tuning models of reasonable size requires some decent resources, and has to be performed for each new set of documents.
Alternatively, you can use an architecture known as retrieval-augmented generation (RAG). I’ll get into specific details shortly, but as a general overview; RAG involves taking a set of (text) documents, chunking them up into pieces, and indexing them in a specific way. When someone asks a question, the question is used to query/retrieve your indexed text (again, in a specific way), which is then stuffed into a prompt that is fed to an LLM. This lets you use off-the-shelf LLMs to answer questions from text contained in your private documents. There are countless articles and guides on building RAG pipelines.
Chat over private documents? Nemesis has private documents! We’ve actually had lots of plumbing in place for a while to help support a RAG pipeline over text extracted and indexed in Nemesis. I talked a lot of these modifications in a previous Twitter thread but I’ll go into more details here. This post will cover specifics about our implementation, as well as the release of RAGnarok: a proof-of-concept local chatbot frontend.
Building a Nemesis RAG Pipeline
We have to cover a bit of technical background on natural language processing (NLP) so the architecture makes sense. If you don’t care, you can skip ahead to the Summoning RAGnarok section to see everything in action.
RAG makes use of something called “vector embeddings’’ for text in order to perform its text retrieval. Pinecone has a great explanation here; but at a high level, vector embeddings are fixed length arrays of floats that specially-trained language models (i.e., embedding models) generate. These models take text input of up to a specific context length (most commonly 512 tokens, more on tokens in the On Local Large Language Models section) and output a fixed length embedding vector (e.g., dimensions of 384, 512, 768, 1024, etc). As Pinecone states, “But there is something special about vectors that makes them so useful. This representation makes it possible to translate semantic similarity as perceived by humans to proximity in a vector space.” This means that the more similar two texts are, the closer their vectors will be. From Pinecone’s example, the vector for “Look how sad my cat is.” will be more similar to the one for “Look at my little cat!” than “A dog is walking past a field.” Since the vectors from an embedding model exist in the same hyperspace, we can use existing distance measures like cosine similarity to efficiently measure how “close” two vector vectors are to each other. This means we can use algorithms like k-nearest neighbors to find vectors similar to one we’re searching for.
This vector indexing and search is the crux of a basic RAG pipeline:
- Split input documents into chunks of text under our embedding model’s context window (often 512 tokens)
- Pass each text chunk through an embedding model to produce a vector embedding for that piece of text
- Store the vector/text pair in a vector database
- When a user asks a question, pass that question through the same embedding model to produce a vector embedding
- Query the vector database for the k (this is adjustable) vectors closest to the question vector, and return the text associated with each vector
- Stuff the text snippets into a LLM prompt of the form “Based on the following context, answer this question…”
Pinecone also has a good diagram summarizing this process:
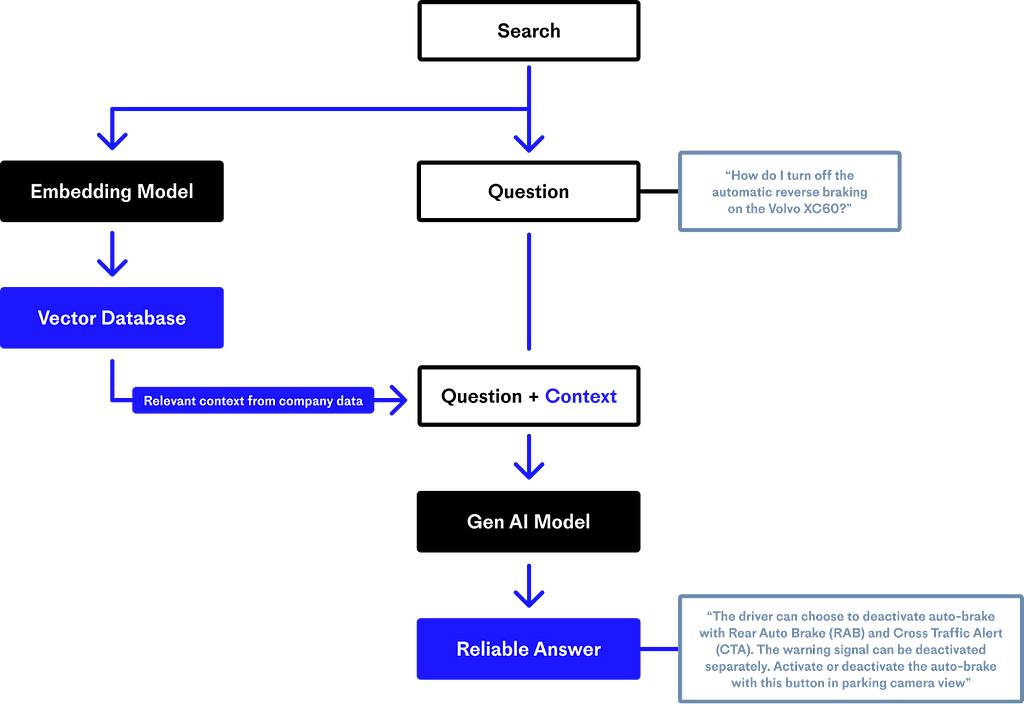
This is basic retrieval-augmented generation.
One thing we realized when implementing some of these components in Nemesis is that the language model used (more on this in the next section) is arguably not the most important part of the architecture. The answer of an LLM is only as good as the context you feed it, meaning the indexing and retrieval parts of the pipeline are actually more important. We’re now going to detail various decisions we made with Nemesis and how this affects the efficacy of the entire system.
First up is the embedding model itself. HuggingFace actually has a leaderboard for embedding models called the Massive Text Embedding Benchmark (MTEB) Leaderboard, so let’s just pick the best model to use, right?

While Nemesis can scale with the infrastructure you run it on, by default we aim to support a 12GB RAM, three core local Minikube instance (k3s hopefully soon!). This means that we can’t effectively run most of the embedding models listed on MTEB and have to aim smaller, which unfortunately translates to “not as effective”. We also have the situation where we might end up chunking/indexing very large text files, so we have to balance the time it will take to generate the embeddings with RAM/CPU consumption as well. After a lot of experimentation, we ended up using TaylorAI’s gte-tiny embedding model, which has a 512 token context window and 384 dimensional vector space.

Next up is the vector database where we store everything. This one was an easy choice, as we already had Elasticsearch deployed in Nemesis, which handles vector search quite well. It also has a lot of optimized traditional(-ish) search capabilities, including fuzzy search and a similarity module that performs a type of search called BM25 (more info on that here if you’re interested, and I know you are). Why do this? As our friends at Pinecone yet again describe, “Vector search or dense retrieval has been shown to significantly outperform traditional methods when the embedding models have been fine-tuned on the target domain. However, this changes when we try using these models for “out-of-domain” tasks.” TL;DR vector search works well for many things, but uncommon terms will cause vector search to often perform worse than BM25.
And this brings us to the next decision: how to exploit both traditional text search and vector embedding search to get the best of both worlds.
One approach to this is something called reciprocal rank fusion (RRF). Basically, RRF lets you combine two ranked lists that have different score magnitudes (e.g., -10–10 for text search and 0–1 for vector similarity), and it’s actually quite simple. Each document in each list is given a rank score of 1/(rank + k), where rank is its place on the list (i.e., 5 if it’s the 5th item) and k is a constant usually set to a value of 60 (why 60? math stuffz, maybe?). If any document appears in both lists, the scores are added together (e.g., if it’s ranked 5th on one list and 10th in the other, the score is 1/(5+60) + 1/(10+60) = 0.02967; then the list of unique documents is reranked based on the fused scores).
This makes a bit more sense with a complete example:
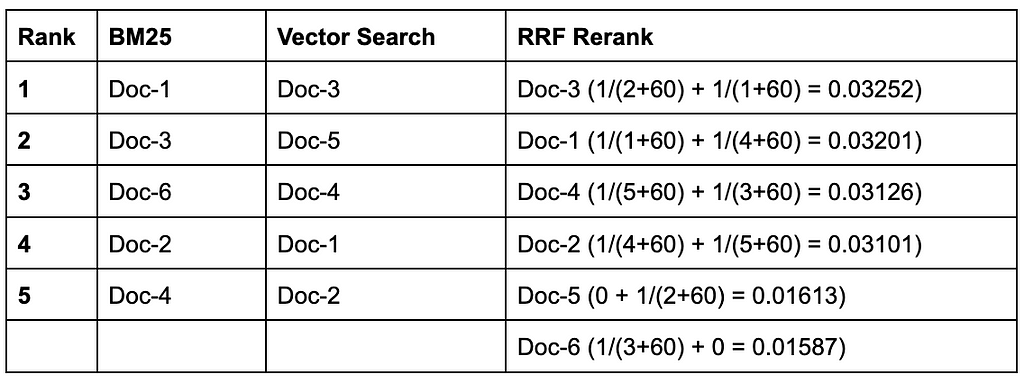
The nlp container for Nemesis implements this RRF strategy, which is used in the Document Search page of the dashboard when “Use Hybrid Vector Search” is selected:
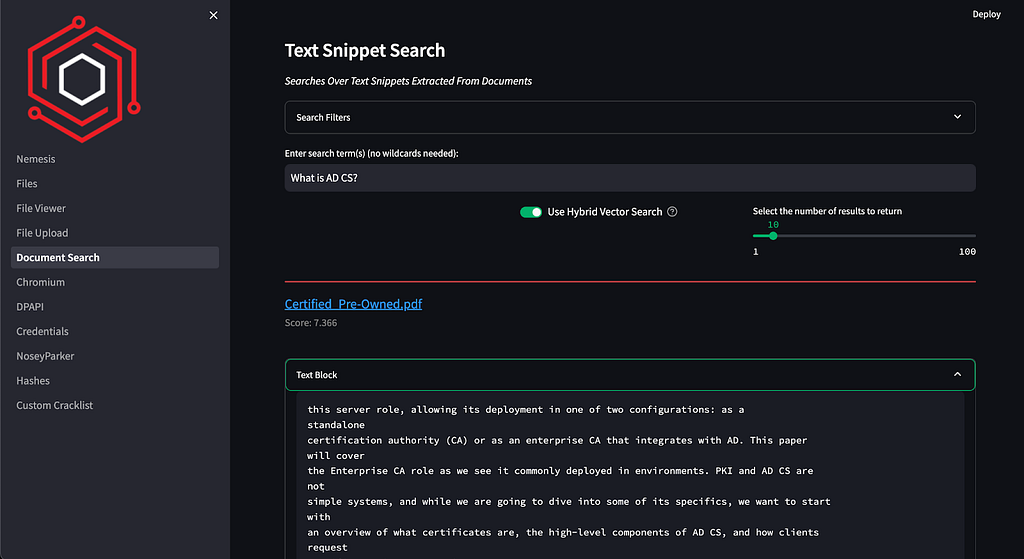
This seems to be a good approach and lets us get X top results from exploiting both vector embedding search and Elastic’s optimized traditional(-ish) text search. However, there’s another addition we can throw on top of all of this that can make things even more effective: reranking.
There is another type of specialized language model known as rerankers, also known as cross-encoders. These models are trained to take two chunks of text and output a similarity score for the text pair. These models are not as powerful as a full LLM and are trained solely for this purpose. In a perfect world we would run the reranker against our question and every document in the database, but that would take an enormous amount of time. Instead, we can combine RRF and reranking:, an architecture that Microsoft appears to suggest based on real-world data.
So, to summarize the process:
- A user types a question
- We pass the question through the same gte-tiny embedding model that Nemesis uses
- We query Elasticsearch for the k closest vectors/texts to the user question, as well as performing traditional (fuzzy BM25) text search over the text field itself to also return k results
- We fuse the two lists of results together using reciprocal rank fusion and return the X top ranked results
- Finally, we can use a reranker to score the prompt and fused text snippets and rerank them with the new scores. We then use the top Y results in the prompt for the LLM
The second through fourth steps are performed in Nemesis itself and are done for the “Text Snippet” tab of the Document Search dashboard page. Since a reranker takes additional resources and is mainly useful in trimming down results to get our total text token count under the context window of the LLM, the fifth step is done in RAGnarok. We’re using an adapted version of a newer reranker (i.e., BAAI/bge-reranker-base) which we can use because it’s running on the RAGnarok side instead of within Nemesis itself. We’ll have a post in a few weeks on the “modification” process for this reranker.
By default, the k used internally is triple the number of requested results in order to cast a big net, and the default X in RAGnarok is 30. This means that 3*30=90 snippets are searched for by traditional search, 90 via vector search, the lists are fused with RRF, and we return the top 30 combined results. The reranker compares the user question to these 30 results and the top Y results (adjustable in settings) pieces of text are used depending if their similarity score(s) are greater than 0. These snippets are fed into a prompt to our local LLM.
The general idea is to cast a fairly wide net with the initial BM25/vector searches (which are efficient and fast), fuse the results and take top ranked documents using RRF to narrow the options (which is also very fast), and present a reasonable number of options to the more accurate (but slower) reranker to finalize our candidates for the LLM. And on that note…
On Local Large Language Models
So we just send everything to ChatGPT, right?

No. Please do not do this.
We can’t use many commercial services like OpenAI because of the lack of privacy guarantees, unless you use some commercial offerings with such promises. Specifically, data you input into most online AI services can/will be used for future model training and troubleshooting, meaning that submitted text can/will leak out of future models! As security professionals, we have to take the security and privacy of our customers’ data extremely seriously, so we can never send private data to an online model service unless there’s a contractual privacy agreement that meshes with existing client contracts!
So where does that leave us? We could pay for a professional privacy-guaranteed service, but this can start to snowball and add up over time. For example, at the time of this article, the prices for the Azure OpenAI professional API are:
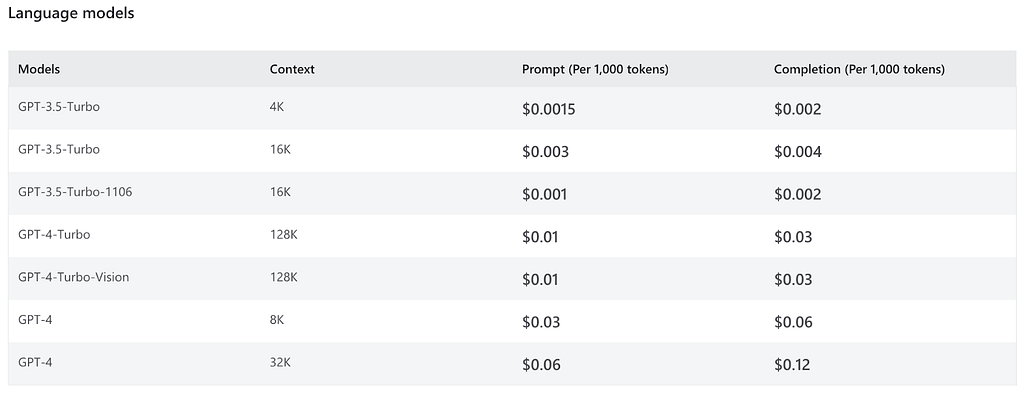
Tokens? LLMs calculate input now as words or sentences, but common sequences of text known as tokens. OpenAI has an example calculator here, but a general rule is that one token is about four characters of text. The prompt in the table above refers to the amount of tokens that you input into the model, completion means how many tokens the model generates, and context is the maximum number of tokens a model can process in one call. So for example, if we have a document with ~5,000 words (i.e., ~6,000ish tokens), it would cost us $0.03 * 6 to feed the text to the GPT-4 endpoint and $0.06 for every 800 words or so the model returns, meaning a minimum of $0.24 for the call. While this doesn’t seem like a lot, it can add up incredibly quickly if we’re not careful.
Alternatively, we can run our own local LLMs, which guarantee our data privacy and greatly reduce cost if our current (say, laptop) hardware can handle the model we’re using. The tradeoff is that local models are not going to be as effective as commercial offerings, but the local LLM ecosystem has exploded over the past year and many local models are becoming pretty good; however, for anyone who has dived into local LLMs, you know that there are some complications.
First, the local LLM scene moves incredibly fast. The HuggingFace Open LLM Leaderboard changes pretty much daily, with new models coming out constantly. Also, we don’t know the provenance of many of these models and security concerns do exist around running untrusted model files.

We’re also obviously constrained by what hardware you’re running. Models come in different sizes, which affects a) whether or not you can even load the model on your system and b) how many tokens/second are generated. If you overshoot and use something too big, you might end up with minutes of time for the LLM to process your prompt and less than a token a second for any response it generates. Models generally come in ~1.5, 3, 7, 13, 30–35, and 60+ billion parameter classes and from our admittedly non-expert experience, top ranked 7 billion models seem to function reasonably well for RAG purposes. To make things even more efficient, many local-LLMers run quantized models (i.e., where the precision of a model’s weights are reduced to help reduce size) to reduce accuracy and increase speed.
So all of these things considered, the default model we’ve incorporated into RAGnarok is Intel/neural-chat-7b-v3–3 (license Apache 2.0), specifically TheBloke’s Q5_K_M.gguf quantized version of model. It’s a solid all around model with a decently long input context (i.e., 8192 tokens) and seems to function fairly well if it’s fed the right input text.
Note: If you want to play around with other local models and see what works well on your system, we highly recommend you check out LM Studio.
Summoning RAGnarok
That was a lot of background! Let’s put everything together and see RAGnarok in action.

To get everything up and going, clone the repo and run ./launch.sh. This will set a Python virtual environment, install all of the requirements, and launch the RAGnarok interface. On the main settings page, input your Nemesis connection information. You should be able to leave the rest of the settings at their default.
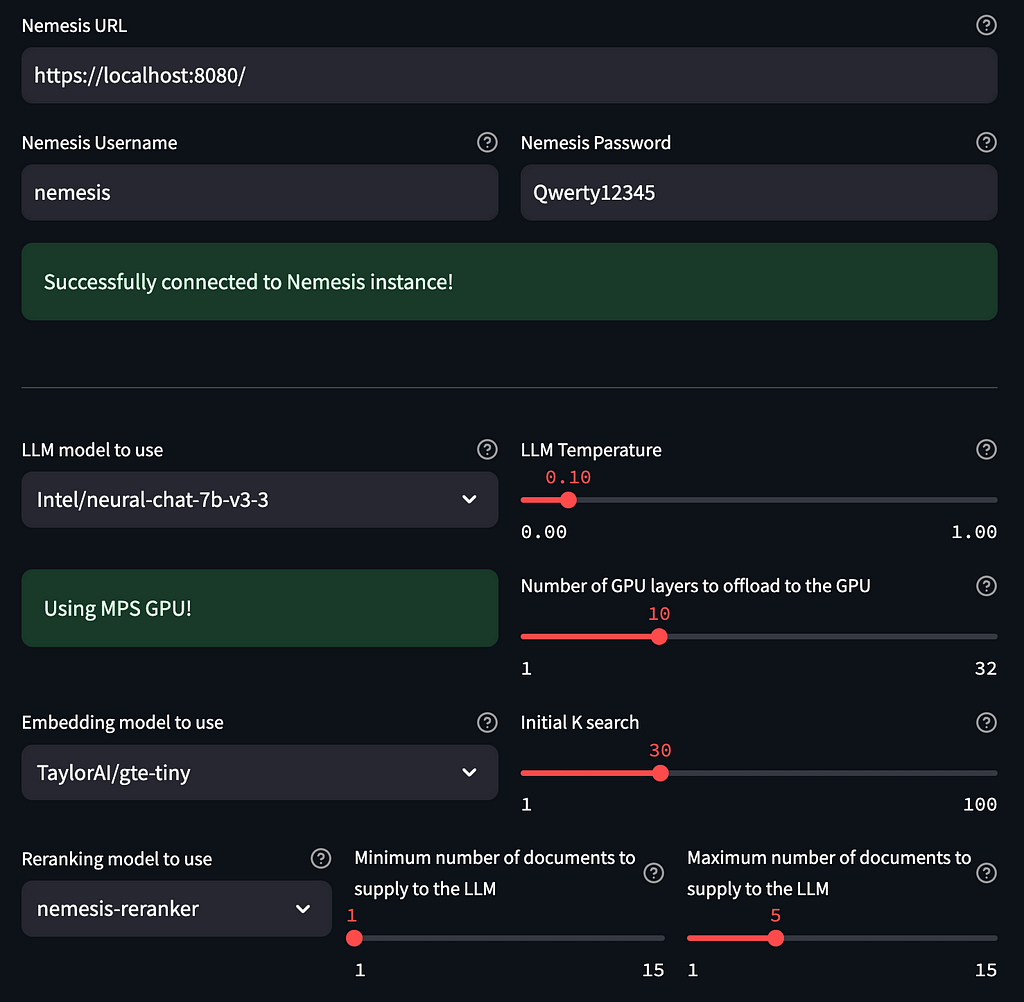
Note: RAGnarok should detect and enable GPU acceleration if you have a GPU (e.g., M1+ macbooks and Nvidia CUDA) available.
The RAGnarok Chat page is the chat interface that operates over a Nemesis instance, while the Free Chat page is a straight interface to the backend. The first time you open the RAGnarok Chat page the code will download the LLM, embedding model, and reranker, which will take some time initially.
Ingest some documents into Nemesis (in our case some public white papers and protocol specifications) and then head over to the RAGnarok Chat page. Ask a question and see what happens!
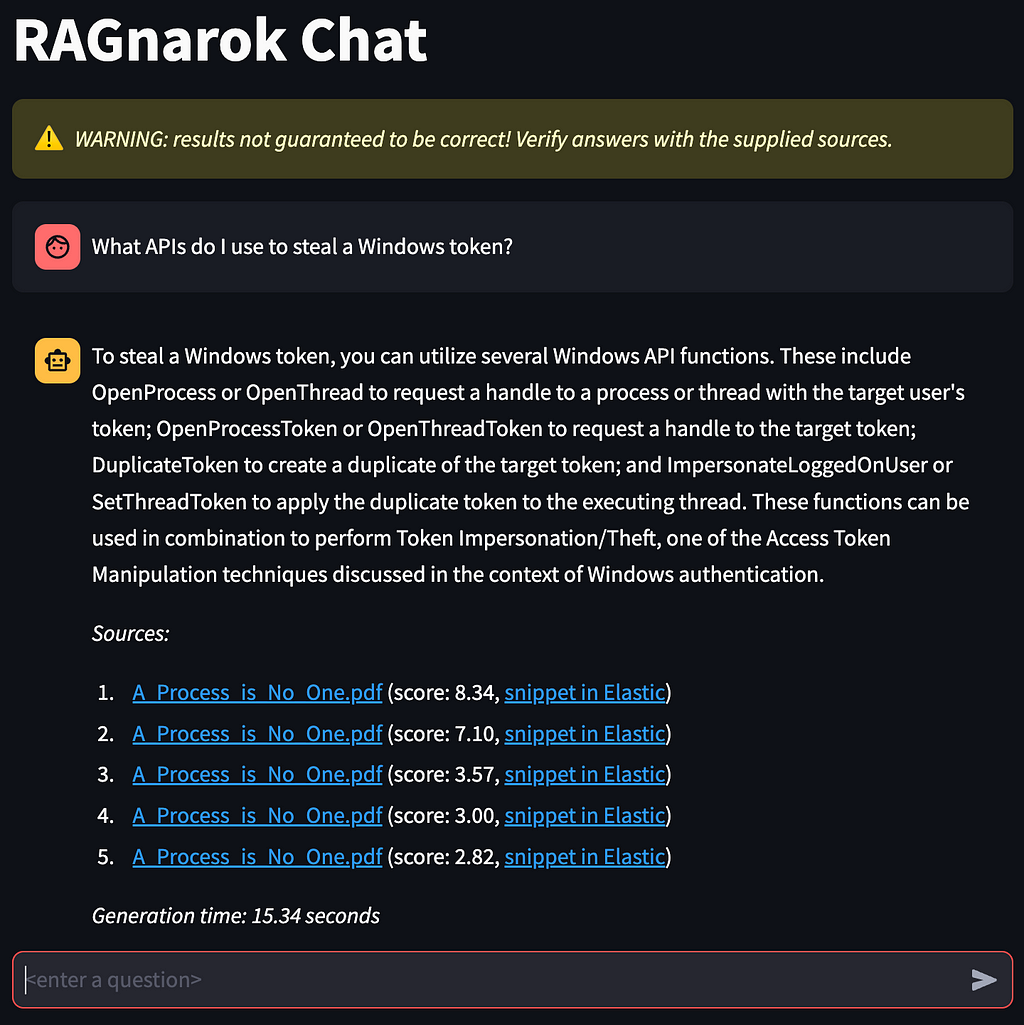
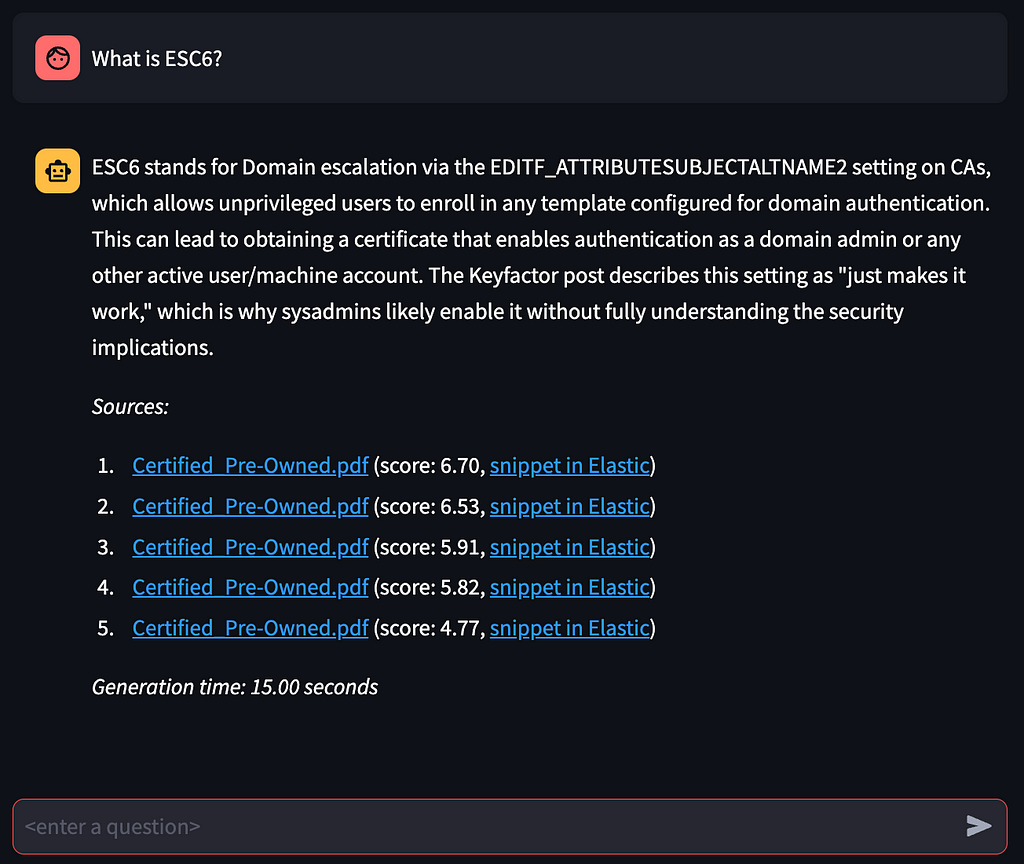
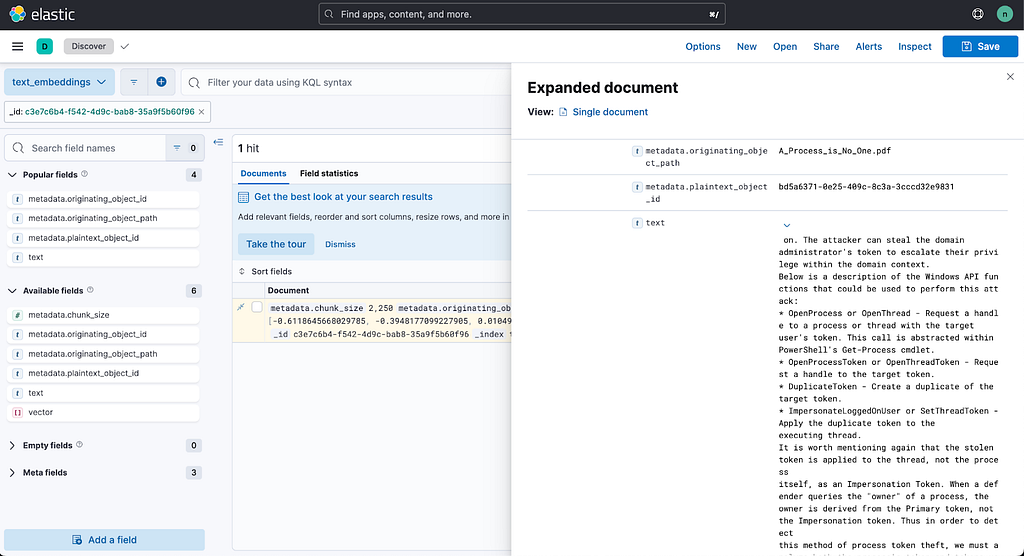
The Sources at the bottom of the answer will have one entry per snippet used in constructing the prompt for the LLM, with the originating document name hyperlinked to the document in Nemesis and similarity score for the snippet. It also has the direct link to the indexed text snippet in Elasticsearch:
Additionally, RAGnarok can utilize the Nemesis text search backend to include or exclude specific path/filename patterns in the initial hybrid text search. This means you can either focus on a particular document, or filter out specific path/document results that are polluting results:
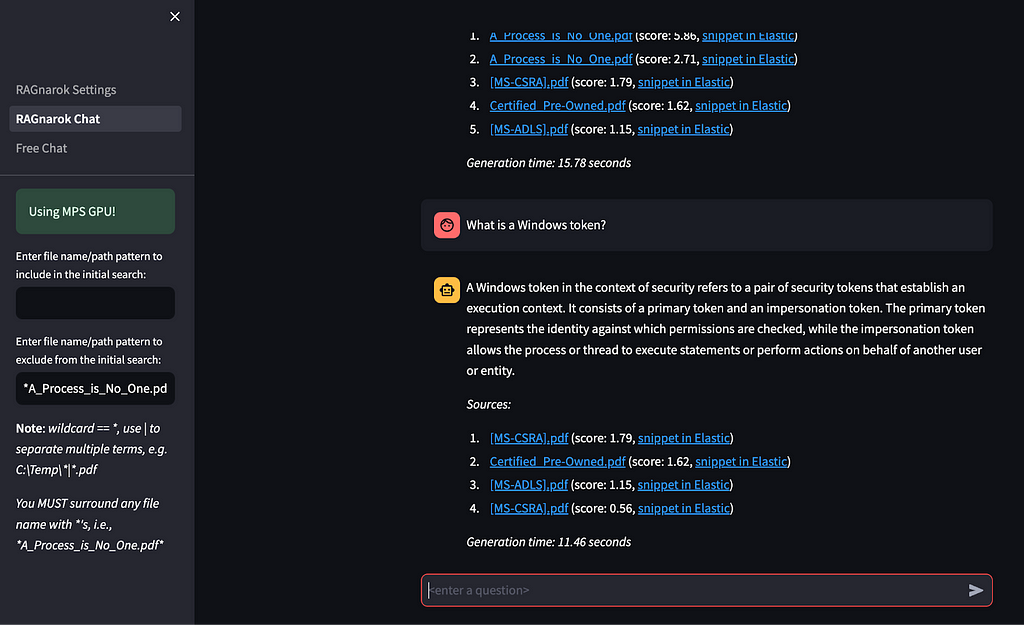
However, nothing’s perfect. If you receive an “I don’t know” type of answer, you can try rewording your question, increasing the initial k search setting or the minimum number of documents to pass to the LLM, or modifying the backend LLM used.
The biggest constraint for this system is the embedding model used in Nemesis itself. If you have the resources, you can utilize a larger model from MTEB like bge-large-en-v1.5 or bge-base-en-v1.5 to generate more effective embeddings. Additionally, we can likely perform some better cleaning of data after it’s extracted: something we’re planning on experimenting with.
If you play around with RAGnarok or Nemesis, let us know what works and what doesn’t! Come join us in the #nemesis-chat channel of the BloodHound Slack! We (the main Nemesis devs- @tifkin_, @harmj0y, and @Max Harley) are all active in that channel.
Summoning RAGnarok With Your Nemesis was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from Posts By SpecterOps Team Members - Medium authored by Will Schroeder. Read the original post at: https://posts.specterops.io/summoning-ragnarok-with-your-nemesis-7c4f0577c93b?source=rss----f05f8696e3cc---4
如有侵权请联系:admin#unsafe.sh