一
柚子模拟器的部分机制
struct UserCallbacks {
virtual ~UserCallbacks() = default;// All reads through this callback are 4-byte aligned.
// Memory must be interpreted as little endian.
virtual std::optional<std::uint32_t> MemoryReadCode(VAddr vaddr) { return MemoryRead32(vaddr); }// Reads through these callbacks may not be aligned.
virtual std::uint8_t MemoryRead8(VAddr vaddr) = 0;
virtual std::uint16_t MemoryRead16(VAddr vaddr) = 0;
virtual std::uint32_t MemoryRead32(VAddr vaddr) = 0;
virtual std::uint64_t MemoryRead64(VAddr vaddr) = 0;
virtual Vector MemoryRead128(VAddr vaddr) = 0;// Writes through these callbacks may not be aligned.
virtual void MemoryWrite8(VAddr vaddr, std::uint8_t value) = 0;
virtual void MemoryWrite16(VAddr vaddr, std::uint16_t value) = 0;
virtual void MemoryWrite32(VAddr vaddr, std::uint32_t value) = 0;
virtual void MemoryWrite64(VAddr vaddr, std::uint64_t value) = 0;
virtual void MemoryWrite128(VAddr vaddr, Vector value) = 0;// Writes through these callbacks may not be aligned.
virtual bool MemoryWriteExclusive8(VAddr /*vaddr*/, std::uint8_t /*value*/, std::uint8_t /*expected*/) { return false; }
virtual bool MemoryWriteExclusive16(VAddr /*vaddr*/, std::uint16_t /*value*/, std::uint16_t /*expected*/) { return false; }
virtual bool MemoryWriteExclusive32(VAddr /*vaddr*/, std::uint32_t /*value*/, std::uint32_t /*expected*/) { return false; }
virtual bool MemoryWriteExclusive64(VAddr /*vaddr*/, std::uint64_t /*value*/, std::uint64_t /*expected*/) { return false; }
virtual bool MemoryWriteExclusive128(VAddr /*vaddr*/, Vector /*value*/, Vector /*expected*/) { return false; }// If this callback returns true, the JIT will assume MemoryRead* callbacks will always
// return the same value at any point in time for this vaddr. The JIT may use this information
// in optimizations.
// A conservative implementation that always returns false is safe.
virtual bool IsReadOnlyMemory(VAddr /*vaddr*/) { return false; }/// The interpreter must execute exactly num_instructions starting from PC.
virtual void InterpreterFallback(VAddr pc, size_t num_instructions) = 0;// This callback is called whenever a SVC instruction is executed.
virtual void CallSVC(std::uint32_t swi) = 0;virtual void ExceptionRaised(VAddr pc, Exception exception) = 0;
virtual void DataCacheOperationRaised(DataCacheOperation /*op*/, VAddr /*value*/) {}
virtual void InstructionCacheOperationRaised(InstructionCacheOperation /*op*/, VAddr /*value*/) {}
virtual void InstructionSynchronizationBarrierRaised() {}// Timing-related callbacks
// ticks ticks have passed
virtual void AddTicks(std::uint64_t ticks) = 0;
// How many more ticks am I allowed to execute?
virtual std::uint64_t GetTicksRemaining() = 0;
// Get value in the emulated counter-timer physical count register.
virtual std::uint64_t GetCNTPCT() = 0;
};
void MarkRegionDebug(u64 vaddr, u64 size, bool debug)
二
对jit的改造
using RunCodeFuncType = HaltReason (*)(void*, CodePtr);
)
align();
run_code = getCurr<RunCodeFuncType>();// This serves two purposes:
// 1. It saves all the registers we as a callee need to save.
// 2. It aligns the stack so that the code the JIT emits can assume
// that the stack is appropriately aligned for CALLs.
ABI_PushCalleeSaveRegistersAndAdjustStack(*this, sizeof(StackLayout));mov(r15, ABI_PARAM1);
mov(rbx, ABI_PARAM2); // save temporarily in non-volatile registerif (cb.enable_cycle_counting) {
cb.GetTicksRemaining->EmitCall(*this);
mov(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_to_run)], ABI_RETURN);
mov(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_remaining)], ABI_RETURN);
}rcp(*this);
cmp(dword[r15 + jsi.offsetof_halt_reason], 0);
jne(return_to_caller_mxcsr_already_exited, T_NEAR);SwitchMxcsrOnEntry();
jmp(rbx);
HaltReason Run() {
ASSERT(!is_executing);
PerformRequestedCacheInvalidation(static_cast<HaltReason>(Atomic::Load(&jit_state.halt_reason)));is_executing = true;
SCOPE_EXIT {
this->is_executing = false;
};// TODO: Check code alignment
const CodePtr current_code_ptr = [this] {
// RSB optimization
const u32 new_rsb_ptr = (jit_state.rsb_ptr - 1) & A64JitState::RSBPtrMask;
if (jit_state.GetUniqueHash() == jit_state.rsb_location_descriptors[new_rsb_ptr]) {
jit_state.rsb_ptr = new_rsb_ptr;
return reinterpret_cast<CodePtr>(jit_state.rsb_codeptrs[new_rsb_ptr]);
}return GetCurrentBlock();
}();const HaltReason hr = block_of_code.RunCode(&jit_state, current_code_ptr);
PerformRequestedCacheInvalidation(hr);
return hr;
}
align();
step_code = getCurr<RunCodeFuncType>();ABI_PushCalleeSaveRegistersAndAdjustStack(*this, sizeof(StackLayout));
mov(r15, ABI_PARAM1);
if (cb.enable_cycle_counting) {
mov(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_to_run)], 1);
mov(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_remaining)], 1);
}rcp(*this);
cmp(dword[r15 + jsi.offsetof_halt_reason], 0);
jne(return_to_caller_mxcsr_already_exited, T_NEAR);
lock();
or_(dword[r15 + jsi.offsetof_halt_reason], static_cast<u32>(HaltReason::Step));SwitchMxcsrOnEntry();
jmp(ABI_PARAM2);
IR::Block Translate(LocationDescriptor descriptor, MemoryReadCodeFuncType memory_read_code, TranslationOptions options) {
const bool single_step = descriptor.SingleStepping();IR::Block block{descriptor};
TranslatorVisitor visitor{block, descriptor, std::move(options)};bool should_continue = true;
do {
const u64 pc = visitor.ir.current_location->PC();if (const auto instruction = memory_read_code(pc)) {
if (auto decoder = Decode<TranslatorVisitor>(*instruction)) {
should_continue = decoder->get().call(visitor, *instruction);
} else {
should_continue = visitor.InterpretThisInstruction();
}
} else {
should_continue = visitor.RaiseException(Exception::NoExecuteFault);
}visitor.ir.current_location = visitor.ir.current_location->AdvancePC(4);
block.CycleCount()++;
} while (should_continue && !single_step);if (single_step && should_continue) {
visitor.ir.SetTerm(IR::Term::LinkBlock{*visitor.ir.current_location});
}ASSERT_MSG(block.HasTerminal(), "Terminal has not been set");
block.SetEndLocation(*visitor.ir.current_location);
return block;
}
HaltReason Step() {
ASSERT(!is_executing);
PerformRequestedCacheInvalidation(static_cast<HaltReason>(Atomic::Load(&jit_state.halt_reason)));is_executing = true;
SCOPE_EXIT {
this->is_executing = false;
};const HaltReason hr = block_of_code.StepCode(&jit_state, GetCurrentSingleStep());
PerformRequestedCacheInvalidation(hr);
return hr;
}
align();
return_from_run_code[0] = getCurr<const void*>();cmp(dword[r15 + jsi.offsetof_halt_reason], 0);
jne(return_to_caller);
if (cb.enable_cycle_counting) {
cmp(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_remaining)], 0);
jng(return_to_caller);
}
cb.LookupBlock->EmitCall(*this);
jmp(ABI_RETURN);
void A64EmitX64::EmitTerminalImpl(IR::Term::LinkBlock terminal, IR::LocationDescriptor, bool is_single_step) {
if (!conf.HasOptimization(OptimizationFlag::BlockLinking) || is_single_step) {
code.mov(rax, A64::LocationDescriptor{terminal.next}.PC());
code.mov(qword[r15 + offsetof(A64JitState, pc)], rax);
code.ReturnFromRunCode();
return;
}if (conf.enable_cycle_counting) {
code.cmp(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_remaining)], 0);patch_information[terminal.next].jg.push_back(code.getCurr());
if (const auto next_bb = GetBasicBlock(terminal.next)) {
EmitPatchJg(terminal.next, next_bb->entrypoint);
} else {
EmitPatchJg(terminal.next);
}
} else {
code.cmp(dword[r15 + offsetof(A64JitState, halt_reason)], 0);patch_information[terminal.next].jz.push_back(code.getCurr());
if (const auto next_bb = GetBasicBlock(terminal.next)) {
EmitPatchJz(terminal.next, next_bb->entrypoint);
} else {
EmitPatchJz(terminal.next);
}
}code.mov(rax, A64::LocationDescriptor{terminal.next}.PC());
code.mov(qword[r15 + offsetof(A64JitState, pc)], rax);
code.ForceReturnFromRunCode();
}void A64EmitX64::EmitTerminalImpl(IR::Term::LinkBlockFast terminal, IR::LocationDescriptor, bool is_single_step) {
if (!conf.HasOptimization(OptimizationFlag::BlockLinking) || is_single_step) {
code.mov(rax, A64::LocationDescriptor{terminal.next}.PC());
code.mov(qword[r15 + offsetof(A64JitState, pc)], rax);
code.ReturnFromRunCode();
return;
}patch_information[terminal.next].jmp.push_back(code.getCurr());
if (auto next_bb = GetBasicBlock(terminal.next)) {
EmitPatchJmp(terminal.next, next_bb->entrypoint);
} else {
EmitPatchJmp(terminal.next);
}
}void A64EmitX64::EmitTerminalImpl(IR::Term::PopRSBHint, IR::LocationDescriptor, bool is_single_step) {
if (!conf.HasOptimization(OptimizationFlag::ReturnStackBuffer) || is_single_step) {
code.ReturnFromRunCode();
return;
}code.jmp(terminal_handler_pop_rsb_hint);
}void A64EmitX64::EmitTerminalImpl(IR::Term::FastDispatchHint, IR::LocationDescriptor, bool is_single_step) {
if (!conf.HasOptimization(OptimizationFlag::FastDispatch) || is_single_step) {
code.ReturnFromRunCode();
return;
}code.jmp(terminal_handler_fast_dispatch_hint);
}
align();
return_from_run_code[MXCSR_ALREADY_EXITED] = getCurr<const void*>();cmp(dword[r15 + jsi.offsetof_halt_reason], 0);
jne(return_to_caller_mxcsr_already_exited);
if (cb.enable_cycle_counting) {
cmp(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_remaining)], 0);
jng(return_to_caller_mxcsr_already_exited);
}
SwitchMxcsrOnEntry();
cb.LookupBlock->EmitCall(*this);
jmp(ABI_RETURN);
align();
return_from_run_code[FORCE_RETURN] = getCurr<const void*>();
L(return_to_caller);SwitchMxcsrOnExit();
// fallthroughreturn_from_run_code[MXCSR_ALREADY_EXITED | FORCE_RETURN] = getCurr<const void*>();
L(return_to_caller_mxcsr_already_exited);if (cb.enable_cycle_counting) {
cb.AddTicks->EmitCall(*this, [this](RegList param) {
mov(param[0], qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_to_run)]);
sub(param[0], qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_remaining)]);
});
}xor_(eax, eax);
lock();
xchg(dword[r15 + jsi.offsetof_halt_reason], eax);ABI_PopCalleeSaveRegistersAndAdjustStack(*this, sizeof(StackLayout));
ret();
void BlockOfCode::SwitchMxcsrOnEntry() {
stmxcsr(dword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, save_host_MXCSR)]);
ldmxcsr(dword[r15 + jsi.offsetof_guest_MXCSR]);
}void BlockOfCode::SwitchMxcsrOnExit() {
stmxcsr(dword[r15 + jsi.offsetof_guest_MXCSR]);
ldmxcsr(dword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, save_host_MXCSR)]);
}
static std::function<void(BlockOfCode&)> GenRCP(const A64::UserConfig& conf) {
return [conf](BlockOfCode& code) {
if (conf.page_table) {
code.mov(code.r14, mcl::bit_cast<u64>(conf.page_table));
}
if (conf.fastmem_pointer) {
code.mov(code.r13, *conf.fastmem_pointer);
}
};
}
cb.LookupBlock->EmitCall(*this);
// Start emitting.
code.align();
code.dq(pc);
code.dd(0);
code.dd(firstArmInst);
const u8* const entrypoint = code.getCurr();
void BlockOfCode::GenHaltReasonSet(Xbyak::Label& run_code_entry) {
Xbyak::Label _dummy;
GenHaltReasonSetImpl(false, run_code_entry, _dummy);
}
void BlockOfCode::GenHaltReasonSet(Xbyak::Label& run_code_entry, Xbyak::Label& ret_code_entry) {
GenHaltReasonSetImpl(true, run_code_entry, ret_code_entry);
}
void BlockOfCode::GenHaltReasonSetImpl(bool isRet, Xbyak::Label& run_code_entry, Xbyak::Label& ret_code_entry) {
Xbyak::Label normal_code, halt_reason_set;
if (halt_reason_on_run) {
if (isRet) {
push(ABI_RETURN);
push(rbx);
mov(rbx, ABI_RETURN);
}
push(rsi);
push(rdi);
push(r14);
push(r13);mov(esi, word[rbx - 4]);
mov(r14, dword[rbx - 16]);mov(r13, trace_scope_begin);
cmp(r14, r13);
jl(normal_code, T_NEAR);
mov(r13, trace_scope_end);
cmp(r14, r13);
jge(normal_code, T_NEAR);mov(edi, esi);
and_(edi, 0xfc000000);
cmp(edi, 0x94000000);//BL
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xfffffc1f);
cmp(edi, 0xd63f0000);//BLR
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xfffff800);
cmp(edi, 0xd63f0800);//BLRxxx
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xff000010);
cmp(edi, 0x54000000);//B.cond
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xff000010);
cmp(edi, 0x54000010);//BC.cond
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0x7f000000);
cmp(edi, 0x35000000);//CBNZ
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0x7f000000);
cmp(edi, 0x34000000);//CBZ
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0x7f000000);
cmp(edi, 0x37000000);//TBNZ
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0x7f000000);
cmp(edi, 0x36000000);//TBZ
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xfc000000);
cmp(edi, 0x14000000);//B
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xfffffc1f);
cmp(edi, 0xd61f0000);//BR
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xfffff800);
cmp(edi, 0xd61f0800);//BRxxx
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xfffffc1f);
cmp(edi, 0xd65f0000);//RET
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xfffffbff);
cmp(edi, 0xd65f0bff);//RETAA, RETAB
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xffc0001f);
cmp(edi, 0x5500001f);//RETAASPPC, RETABSPPC
jz(halt_reason_set, T_NEAR);mov(edi, esi);
and_(edi, 0xfffffbe0);
cmp(edi, 0xd65f0be0);//RETAASPPC, RETABSPPC
jz(halt_reason_set, T_NEAR);L(normal_code);
pop(r13);
pop(r14);
pop(rdi);
pop(rsi);
if (isRet) {
pop(rbx);
pop(ABI_RETURN);
}
jmp(run_code_entry, T_NEAR);L(halt_reason_set);
pop(r13);
pop(r14);
pop(rdi);
pop(rsi);
lock();
or_(dword[r15 + jsi.offsetof_halt_reason], halt_reason_on_run);if (isRet) {
pop(rbx);
pop(ABI_RETURN);
jmp(ret_code_entry, T_NEAR);
}
}
}
align();
run_code = getCurr<RunCodeFuncType>();// This serves two purposes:
// 1. It saves all the registers we as a callee need to save.
// 2. It aligns the stack so that the code the JIT emits can assume
// that the stack is appropriately aligned for CALLs.
ABI_PushCalleeSaveRegistersAndAdjustStack(*this, sizeof(StackLayout));mov(r15, ABI_PARAM1);
mov(rbx, ABI_PARAM2); // save temporarily in non-volatile registerif (cb.enable_cycle_counting) {
cb.GetTicksRemaining->EmitCall(*this);
mov(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_to_run)], ABI_RETURN);
mov(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_remaining)], ABI_RETURN);
}rcp(*this);
cmp(dword[r15 + jsi.offsetof_halt_reason], 0);
jne(return_to_caller_mxcsr_already_exited, T_NEAR);GenHaltReasonSet(run_code_entry);
L(run_code_entry);
SwitchMxcsrOnEntry();
jmp(rbx);
align();
return_from_run_code[0] = getCurr<const void*>();cmp(dword[r15 + jsi.offsetof_halt_reason], 0);
jne(return_to_caller, T_NEAR);
if (cb.enable_cycle_counting) {
cmp(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_remaining)], 0);
jng(return_to_caller, T_NEAR);
}
cb.LookupBlock->EmitCall(*this);Xbyak::Label next_code_entry0;
GenHaltReasonSet(next_code_entry0, return_to_caller);
L(next_code_entry0);
jmp(ABI_RETURN);
align();
return_from_run_code[MXCSR_ALREADY_EXITED] = getCurr<const void*>();cmp(dword[r15 + jsi.offsetof_halt_reason], 0);
jne(return_to_caller_mxcsr_already_exited, T_NEAR);
if (cb.enable_cycle_counting) {
cmp(qword[rsp + ABI_SHADOW_SPACE + offsetof(StackLayout, cycles_remaining)], 0);
jng(return_to_caller_mxcsr_already_exited, T_NEAR);
}
SwitchMxcsrOnEntry();
cb.LookupBlock->EmitCall(*this);Xbyak::Label next_code_entry1;
GenHaltReasonSet(next_code_entry1, return_to_caller_mxcsr_already_exited);
L(next_code_entry1);
jmp(ABI_RETURN);
三
内存数据修改工具
help
help xxx
a、cmd("命令"); 执行字符串描述的命令。同时终止目前正在运行的脚本。
b、qcmd("命令");
排除执行字符串描述的命令。命令在当前正在运行的脚本执行完后执行。
c、wait(毫秒数);
等待指定时间后继续执行后面的脚本代码。
d、loop(循环次数){...};
指定循环次数的循环语句,可以用来重复执行多次某个命令或函数。迭代的当前次数(从0开始计)使用$$来访问。多层嵌套循环的迭代器变量$$会被重写,所以有嵌套循环时在循环入口需要自己定义一个变量暂存迭代器变量的值。
e、looplist(list){...};
遍历列表的循环,迭代的当前元素使用$$来访问。多层嵌套循环的迭代器变量$$会被重写,所以有嵌套循环时在循环入口需要自己定义一个变量暂存迭代器变量的值。
f、foreach(v1,v2,v3,...){...};
指定列表元素的循环,迭代的当前元素使用$$来访问。多层嵌套循环的迭代器变量$$会被重写,所以有嵌套循环时在循环入口需要自己定义一个变量暂存迭代器变量的值。
g、if(条件){...}elseif(条件)/elif(条件){...}else{...};
条件判断语句,elseif/elif/else都是可选的部分。
qcmd("help sniffing");qcmd("savelist temp.txt");
a、findmem([val1,val2,...])
搜索一次数据。搜索指定的数据列表的数值一次,搜索结果显示在信息列表窗口里。(findmemory是与此命令功能相同的函数,不过它主要用在脚本代码里,参数比较多,并且结果不会显示在ui上)
b、searchmem([val1,val2,...])
搜索多次数据。搜索指定的数据列表的数值多次,搜索结果显示在信息列表窗口里。(searchmemory是与此命令功能相同的函数,不过它主要用在脚本代码里,参数比较多,并且结果不会显示在ui上)
为了实现搜索,还有许多参数由别的命令来指定(也有一个默认值)
c、clearmemscope
清空搜索范围,清空后的搜索范围是整个游戏的地址空间。这是个特别大的地址范围,所以一般不要在清空范围后搜索,可能会卡很久。
d、setmemscope main
指定搜索范围为模块名或build_id对应的模块的地址范围,有一些常用的名称,main是主模块名。然后heap、alias、stack、kernel map、code、alias code、addr space是对整个进程而言的section。
我们可能比较常用的是main、heap与alias三个。启动游戏时默认的搜索范围是main模块的地址范围。
e、setmemscopebegin 0x80004000
指定搜索范围的开始地址。
f、setmemscopeend 0x87000000
指定搜索范围的结束地址。
g、setmemstep 4
指定内存搜索的步长,也就在一个地址查找后,下一个地址增长多少,默认为4字节。
h、setmemsize 4
指定内存搜索的值的大小,我们在搜索命令时会指定一系列要搜索的目标值,这个命令给定这些数值的内存尺寸,默认为4字节。
i、setmemrange 256
指定内存范围(不是搜索的范围),这个参数的涵义是我们搜索的所有目标值的地址范围,只有所有的数值都找到,并且这些值的地址范围在这个参数内,才认为是搜索到了一次结果。
j、setmemcount 10
指定searchmem命令搜索到的结果的最大数量。因为有时候满足条件的地址可能有多个,全用searchmem时可以避免只搜索到一个并不是我们想要的结果。
k、showmem(0x21593f0000, 200[, 1|2|4|8])
显示内存数据,参数分别是起始地址、要显示的内存块的size、单个内存数据的size(可选,默认为4)。内存数据会显示在ui上。一般用来观察搜索结果区域里除目标数据外的其它数据。
l、echo(readmemory(0x21593f0000, 4))
这是2个函数组合成的一个语句,用来显示单个内存数据,2个参数分别是地址与数据尺寸,只能是1、2、4、8之一。
m、writememory(0x21593f0000, 127[, 1|2|4|8])
修改内存数据,参数分别是内存地址、要写入的数据,数据尺寸(可选,只能是1、2、4、8之一,默认为4)。
n、dumpmemory(0x21593f0000, 0x400000, "file.dat");
dump指定内存块到文件。参数分别是内存起始地址,内存块size,保存的文件。
这个函数与ui的操作是一样的,因为是命令,所以可以批量处理添加多个内存范围或地址。
b、addsniffingfromsearch(find_vals)
这个函数与内存搜索命令相似,它也使用内存搜索的其它参数,不过它将搜索到的结果内存(是一个与setmemrange指定的大小相同的区域)添加到监听内存列表。
3、内存调试日志
a、addtracecstring addr
添加读取c字符串的日志,参数addr是字符串的开始地址
b、addtracepointer 参数addr
添加获取指针的日志,参数addr是指针的值
c、addtraceread addr
添加读内存的日志,参数addr是读取的内存地址
d、addtracewrite addr
添加写内存的日志,参数addr是写入的内存地址
e、removetracecstring addr
去掉读指定地址addr c字符串的后续日志
f、removetracepointer addr
去掉获取指针addr的后续日志
g、removetraceread addr
去掉读内存addr的后续日志
h、removetracewrite addr
去掉写内存addr的后续日志
i、settraceswi swi
指定记录指定系统服务的信息,swi是系统服务号,如果是0x7fffffff则记录所有系统服务的信息(这个命令暂时没想到用处,所以只支持指定一个或全部)。
j、cleartracebuffer
清空trace buffer,之前各种日志都记录在这个buffer里
k、savetracebuffer file
保存trace buffer到文件
四
内存指令修改工具
a、addlogb
添加无条件跳转 B/BR/BRxxx 指令到记录指令条件中。
b、addlogbc
添加条件跳转 B.cond/BC.cond/CBNZ/CBZ/TBNZ/TBZ 指令到记录指令条件中。
c、addlogbl
添加过程调用 BL/BLR/BLRxxx 指令到记录指令条件中。
d、addlogret
添加返回 RET/RETxxx 指令到记录指令条件中。
e、clearloginsts
清空指令条件,不设指令条件时,所有分支指令都被记录,包括不是分支指令的基本块入口指令也会记录。
addloginst(mask, value)
下面是指令日志与比对的命令:
a、startpccount or startpccount ix
开始pc记录,ix用于在特定处理器上开启。
b、stoppccount or stoppccount ix
停止pc记录,ix用于停止特定处理器的记录。
c、storepccount
暂存当前的pc记录,作为上一次的pc记录,并清空当前pc记录。
d、keeppccount, keep last and current pc count info
将上一次pc记录与当前pc记录合并为当前pc记录结果,并清空当前pc记录。
e、keepnewpccount
将当前pc记录相对于上一次的pc记录的新pc记录作为当前pc记录结果,并清空当前pc记录。
f、keepsamepccount
将当前pc记录与上一次的pc记录相同的pc记录作为当前pc记录结果,并清空当前pc记录。
g、usepccountarray 0_or_1
设置是否使用预先分配的数组来记录pc,默认开启(本来是为了速度更快的,好像并不明显)
h、clearpccount
清空当前pc记录信息。
i、savepccount file
将pc记录结果存到文件。
j、setmaxpccount num
设置保存到文件的pc记录的条件,这个条件的意思是pc记录里的pc执行到的次数小于等于此值时,这个pc记录就保存到文件,默认为10
a、setstarttracebp addr
添加一个指令断点,当执行触发此断点时,启动单步执行trace,并记录调用栈等环境信息,单步执行的次数受maxstepcount的限制。
这个断点触发后即删除。
b、setstoptracebp addr
添加一个指令断点,当执行触发此断点时,停止单步执行trace。
这个断点触发后即删除。
c、starttrace or starttrace ix
立即开始单步执行trace,参数ix可以指明只对特定处理器开启。单步执行的次数受maxstepcount限制
d、stoptrace or stoptrace ix
停止单步执行trace,参数ix指明只对特定处理器停止。
e、cleartrace
清空设置的trace与断点。
f、settracescope section_key
通过模块名或build_id来设置trace的地址范围
g、settracescopebegin addr
设置trace范围的起始地址
h、settracescopeend addr
设置trace范围的结束地址
i、setmaxstepcount count
设置单步trace的最大步数
j、cleartracebuffer
清空trace buffer,之前各种日志都记录在这个buffer里
k、savetracebuffer file
保存trace buffer到文件
a、showmem(0x21593f0000, 200[, 1|2|4|8])
显示内存数据,参数分别是起始地址、要显示的内存块的size、单个内存数据的size(可选,默认为4)。内存数据会显示在ui上。一般用来观察搜索结果区域里除目标数据外的其它数据。
b、echo(readmemory(0x21593f0000, 4))
这是2个函数组合成的一个语句,用来显示单个内存数据,2个参数分别是地址与数据尺寸,只能是1、2、4、8之一。
c、writememory(0x21593f0000, 127[, 1|2|4|8])
修改内存数据,参数分别是内存地址、要写入的数据,数据尺寸(可选,只能是1、2、4、8之一,默认为4)。
d、dumpmemory(0x21593f0000, 0x400000, "file.dat");
dump指定内存块到文件。参数分别是内存起始地址,内存块size,保存的文件。
五
可编译到金手指的脚本
};
}
elif/elseif()
}
else
};
};
a、dmnt_file语句
[dmnt_file]:dmnt_file(name,module[,file_dir[,build_id]]){...}; statement
b、dmnt_if语句
[dmnt_if]:dmnt_if(exp){...}; or dmnt_if(exp){...}elseif/elif(exp){...}else{...}; or dmnt_if(exp)func(...); statement
c、dmnt_loop语句
[dmnt_loop]:dmnt_loop(reg,ct){...}; statement
[dmnt_add]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
[dmnt_and]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
[dmnt_calc_offset]:dmnt_calc_offset(offset,addr,region), all type is integer
[dmnt_comment]:dmnt_comment(str)
[dmnt_debug]:dmnt_debug(mem_width,log_id,opd_type,val1[,val2]), all type is integer
[dmnt_eq]:dmnt_xxx(mem_width,mem_region,offset,val), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_ge]:dmnt_xxx(mem_width,mem_region,offset,val), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_gt]:dmnt_xxx(mem_width,mem_region,offset,val), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_key]:dmnt_key(key) key:A|B|X|Y|LS|RS|L|R|ZL|ZR|Plus|Minus|Left|Up|Right|Down|LSL|LSU|LSR|LSD|RSL|RSU|RSR|RSD|SL|SR
[dmnt_keypress]:dmnt_keypress(key1,key2,...); all type is integer, key can get by dmnt_key(const)
[dmnt_le]:dmnt_xxx(mem_width,mem_region,offset,val), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_legacy_add]:dmnt_legacy_xxx(mem_width,reg,val), all type is integer, xxx:add|sub|mul|lshift|rshift
[dmnt_legacy_lshift]:dmnt_legacy_xxx(mem_width,reg,val), all type is integer, xxx:add|sub|mul|lshift|rshift
[dmnt_legacy_mul]:dmnt_legacy_xxx(mem_width,reg,val), all type is integer, xxx:add|sub|mul|lshift|rshift
[dmnt_legacy_rshift]:dmnt_legacy_xxx(mem_width,reg,val), all type is integer, xxx:add|sub|mul|lshift|rshift
[dmnt_legacy_sub]:dmnt_legacy_xxx(mem_width,reg,val), all type is integer, xxx:add|sub|mul|lshift|rshift
[dmnt_load_m2r]:dmnt_load_m2r(mem_width[,mem_region],reg,offset), all type is integer
[dmnt_load_v2r]:dmnt_load_v2r(reg,val), all type is integer
[dmnt_lshift]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
[dmnt_lt]:dmnt_xxx(mem_width,mem_region,offset,val), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_mov]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
[dmnt_mul]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
[dmnt_ne]:dmnt_xxx(mem_width,mem_region,offset,val), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_not]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
[dmnt_offset]:dmnt_offset(name) name:no_offset|offset_reg|offset_fixed|region_and_base|region_and_relative|region_and_relative_and_offset
[dmnt_operand]:dmnt_operand(name) name:mem_and_relative|mem_and_offset|reg_and_relative|reg_and_offset|static_value|register_value|reg_other|restore_register|save_register|clear_saved_value|clear_register
[dmnt_or]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
[dmnt_pause]:dmnt_pause()
[dmnt_read_mem]:dmnt_read_mem(val,addr[,val_size]), all type is integer
[dmnt_reg_eq]:dmnt_reg_xxx(mem_width,src_reg,opd_type,val1[,val2]), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_reg_ge]:dmnt_reg_xxx(mem_width,src_reg,opd_type,val1[,val2]), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_reg_gt]:dmnt_reg_xxx(mem_width,src_reg,opd_type,val1[,val2]), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_reg_le]:dmnt_reg_xxx(mem_width,src_reg,opd_type,val1[,val2]), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_reg_lt]:dmnt_reg_xxx(mem_width,src_reg,opd_type,val1[,val2]), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_reg_ne]:dmnt_reg_xxx(mem_width,src_reg,opd_type,val1[,val2]), all type is integer, xxx:gt|ge|lt|le|eq|ne
[dmnt_reg_rw]:dmnt_reg_rw(static_reg_index,reg), all type is integer, static_reg_index: 0x00 to 0x7F for reading or 0x80 to 0xFF for writing
[dmnt_reg_sr]:dmnt_reg_sr(dest_reg,src_reg,opd_type), all type is integer
[dmnt_reg_sr_mask]:dmnt_reg_sr_mask(opd_type,mask), all type is integer
[dmnt_region]:dmnt_region(mem_region) mem_region:main|heap|alias|aslr
[dmnt_resume]:dmnt_resume()
[dmnt_rshift]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
[dmnt_store_r2m]:dmnt_store_r2m(mem_width,src_reg,mem_reg,reg_inc_1or0,[offset_type,offset_or_reg_or_region[,offset]]), all type is integer
[dmnt_store_v2a]:dmnt_store_v2a(mem_width,mem_region,reg,offset,val), all type is integer
[dmnt_store_v2m]:dmnt_store_v2m(mem_width,mem_reg,reg_inc_1or0,val[,offset_reg]), all type is integer
[dmnt_sub]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
[dmnt_xor]:dmnt_xxx(mem_width,result_reg,lhs_reg,rhs[,rhs_is_val_1or0]), all type is integer, xxx:add|sub|mul|lshift|rshift|and|or|not|xor|mov
dmnt_file("经验物品", "main"){
@region = dmnt_region(main);@base = 0x0000000080004000;
@addr1 = 0x00000000802EF908;
@addr2 = 0x00000000802E8370;
@addr3 = 0x00000000802E8374;
@addr4 = 0x000000008042A02C;
@addr5 = 0x000000008042A038;@wval1 = 0x12BFEC14;
@wval2 = 0x1E2C1000;
@wval3 = 0x52800808;
@wval4 = 0x52A88C2A;
@wval5 = 0x1E212800;@v1 = dmnt_read_mem(@wval1, @addr1);
@v2 = dmnt_read_mem(@wval2, @addr2);
@v3 = dmnt_read_mem(@wval3, @addr3);
@v4 = dmnt_read_mem(@wval4, @addr4);
@v5 = dmnt_read_mem(@wval5, @addr5);@offset1 = dmnt_calc_offset(@addr1 - @base, @addr1, @region);
@offset2 = dmnt_calc_offset(@addr2 - @base, @addr2, @region);
@offset3 = dmnt_calc_offset(@addr3 - @base, @addr3, @region);
@offset4 = dmnt_calc_offset(@addr4 - @base, @addr4, @region);
@offset5 = dmnt_calc_offset(@addr5 - @base, @addr5, @region);dmnt_load_v2r(0,0);
dmnt_if(dmnt_ne(4,@region,@offset1,@v1)){
dmnt_store_v2a(4,@region,0,@offset1,@v1);
};
dmnt_if(dmnt_ne(4,@region,@offset2,@v2)){
dmnt_store_v2a(4,@region,0,@offset2,@v2);
};
dmnt_if(dmnt_ne(4,@region,@offset3,@v3)){
dmnt_store_v2a(4,@region,0,@offset3,@v3);
};
dmnt_if(dmnt_ne(4,@region,@offset4,@v4)){
dmnt_store_v2a(4,@region,0,@offset4,@v4);
};
dmnt_if(dmnt_ne(4,@region,@offset5,@v5)){
dmnt_store_v2a(4,@region,0,@offset5,@v5);
};
};
{ 经验物品 7E06539B5874B9C4 [0100A0C01BED8000] }
40000000 00000000 00000000
14060000 002EB908 12BFEC14
04000000 002EB908 12BFEC14
20000000
14060000 002E4370 1E2C1000
04000000 002E4370 1E2C1000
20000000
14060000 002E4374 52800808
04000000 002E4374 52800808
20000000
14060000 0042602C 52A88C2A
04000000 0042602C 52A88C2A
20000000
14060000 00426038 1E212800
04000000 00426038 1E212800
20000000
[title_id]/我们想用的金手指功能名称/cheats/[build_id].txt
六
switch游戏修改实例
command: setmemscope heap
command: setmemrange 256
command: searchmem([123,95,109,181,154,120,6,187,70,36,109,26,15,126,46]);
===search result===
addr: 21593f7cc4 hex_val: 5f dec_val: 95
addr: 21593f7cf0 hex_val: f dec_val: 15
addr: 21593f7cd8 hex_val: 6 dec_val: 6
addr: 21593f7ce0 hex_val: 46 dec_val: 70
addr: 21593f7cf8 hex_val: 2e dec_val: 46
addr: 21593f7cd0 hex_val: 9a dec_val: 154
addr: 21593f7cec hex_val: 1a dec_val: 26
addr: 21593f7ce4 hex_val: 24 dec_val: 36
addr: 21593f7cd4 hex_val: 78 dec_val: 120
addr: 21593f7ce8 hex_val: 6d dec_val: 109
addr: 21593f7cdc hex_val: bb dec_val: 187
addr: 21593f7cc0 hex_val: 7b dec_val: 123
addr: 21593f7cf4 hex_val: 7e dec_val: 126
addr: 21593f7ccc hex_val: b5 dec_val: 181
===area memory===
addr: 21593f7cc0 hex_val: 7b dec_val: 123
addr: 21593f7cc4 hex_val: 5f dec_val: 95
addr: 21593f7cc8 hex_val: 6d dec_val: 109
addr: 21593f7ccc hex_val: b5 dec_val: 181
addr: 21593f7cd0 hex_val: 9a dec_val: 154
addr: 21593f7cd4 hex_val: 78 dec_val: 120
addr: 21593f7cd8 hex_val: 6 dec_val: 6
addr: 21593f7cdc hex_val: bb dec_val: 187
addr: 21593f7ce0 hex_val: 46 dec_val: 70
addr: 21593f7ce4 hex_val: 24 dec_val: 36
addr: 21593f7ce8 hex_val: 6d dec_val: 109
addr: 21593f7cec hex_val: 1a dec_val: 26
addr: 21593f7cf0 hex_val: f dec_val: 15
===search result===
addr: 21593f84d8 hex_val: 46 dec_val: 70
addr: 21593f84d0 hex_val: 6 dec_val: 6
addr: 21593f84e8 hex_val: f dec_val: 15
addr: 21593f84c8 hex_val: 9a dec_val: 154
addr: 21593f84e4 hex_val: 1a dec_val: 26
addr: 21593f84e0 hex_val: 6d dec_val: 109
addr: 21593f84d4 hex_val: bb dec_val: 187
addr: 21593f84b8 hex_val: 7b dec_val: 123
addr: 21593f84bc hex_val: 5f dec_val: 95
addr: 21593f84c4 hex_val: b5 dec_val: 181
addr: 21593f84cc hex_val: 78 dec_val: 120
addr: 21593f84dc hex_val: 24 dec_val: 36
addr: 21593f84ec hex_val: 7e dec_val: 126
addr: 21593f84f0 hex_val: 2e dec_val: 46
===area memory===
addr: 21593f84b8 hex_val: 7b dec_val: 123
addr: 21593f84bc hex_val: 5f dec_val: 95
addr: 21593f84c0 hex_val: 6d dec_val: 109
addr: 21593f84c4 hex_val: b5 dec_val: 181
addr: 21593f84c8 hex_val: 9a dec_val: 154
addr: 21593f84cc hex_val: 78 dec_val: 120
addr: 21593f84d0 hex_val: 6 dec_val: 6
addr: 21593f84d4 hex_val: bb dec_val: 187
addr: 21593f84d8 hex_val: 46 dec_val: 70
addr: 21593f84dc hex_val: 24 dec_val: 36
addr: 21593f84e0 hex_val: 6d dec_val: 109
addr: 21593f84e4 hex_val: 1a dec_val: 26
addr: 21593f84e8 hex_val: f dec_val: 15
command: savelist list.txt
loop(140){writememory(0x21593f7cc0+$$*4,386);};loop(140){writememory(0x21593f84b8+$$*4,386);}
loop(22){writememory(0x21593fa310+$$*4,386);};loop(22){writememory(0x21593fa400+$$*4,386);}
writememory(0x21593f51d0,999);writememory(0x21593f51d8,999);
writememory(0x21593d090c,999999);writememory(0x21593d0910,999999);
writememory(0x21593f6694,999);writememory(0x21593f69b4,999);writememory(0x21593f669c,999);writememory(0x21593f69bc,999);writememory(0x21593f66a0,999);writememory(0x21593f69c0,999999);writememory(0x21593f66ac,999);writememory(0x21593f69cc,999);writememory(0x21593f66b8,999);writememory(0x21593f69d8,999);writememory(0x21593f66bc,999);writememory(0x21593f69dc,999);writememory(0x21593f66c4,999);writememory(0x21593f69e4,999999);writememory(0x21593f66d4,999);writememory(0x21593f69f4,999);
loop(10){writememory(0x21593f62d0+$$*4,900);};loop(10){writememory(0x21593f64b0+$$*4,900);}
writememory(0x874aac68,1000000);
===[Sniffing]===
history count:0 []
rollback count:0 []
result count:4326
0 vaddr:817732fc type:2 val:64 old val:0 size:4
1 vaddr:81774e9c type:2 val:64 old val:0 size:4
2 vaddr:817eb8d0 type:2 val:64 old val:0 size:4
3 vaddr:817eb8d8 type:2 val:64 old val:0 size:4
4 vaddr:817eda70 type:2 val:64 old val:0 size:4
5 vaddr:817ee34c type:2 val:64 old val:0 size:4
6 vaddr:817efdc8 type:2 val:64 old val:0 size:4
7 vaddr:817f2db4 type:2 val:64 old val:0 size:4
8 vaddr:817f3bfc type:2 val:64 old val:0 size:4
9 vaddr:817f4258 type:2 val:64 old val:0 size:4
===[KeepChanged]===
history count:1 [0:4326]
rollback count:0 []
result count:71
0 vaddr:854ce558 type:2 val:326c0064 old val:64 size:4
1 vaddr:85737198 type:2 val:0 old val:64 size:4
2 vaddr:861a9bec type:2 val:bb8 old val:64 size:4
3 vaddr:861a9bf0 type:2 val:ffffffff old val:64 size:4
4 vaddr:861f8a64 type:2 val:0 old val:64 size:4
5 vaddr:861fd834 type:2 val:0 old val:64 size:4
6 vaddr:8623e624 type:2 val:1f4 old val:64 size:4
7 vaddr:8623e628 type:2 val:1f4 old val:64 size:4
8 vaddr:8623e664 type:2 val:1f4 old val:64 size:4
9 vaddr:86242b88 type:2 val:0 old val:64 size:4
===[KeepChanged]===
history count:2 [0:4326,1:71]
rollback count:0 []
result count:46
0 vaddr:861a9bec type:2 val:0 old val:bb8 size:4
1 vaddr:861a9bf0 type:2 val:0 old val:ffffffff size:4
2 vaddr:8623e624 type:2 val:0 old val:1f4 size:4
3 vaddr:8623e628 type:2 val:0 old val:1f4 size:4
4 vaddr:8623e664 type:2 val:64 old val:1f4 size:4
5 vaddr:86242b88 type:2 val:1f old val:0 size:4
6 vaddr:86292b98 type:2 val:0 old val:14 size:4
7 vaddr:863254a4 type:2 val:0 old val:1b001b size:4
8 vaddr:8634d82c type:2 val:3f800000 old val:514 size:4
9 vaddr:8634d830 type:2 val:0 old val:ffffffff size:4
===[KeepChanged]===
history count:3 [0:4326,1:71,2:46]
rollback count:0 []
result count:40
0 vaddr:8623e624 type:2 val:1b001b old val:0 size:4
1 vaddr:8623e664 type:2 val:0 old val:64 size:4
2 vaddr:86242b88 type:2 val:0 old val:1f size:4
3 vaddr:863254a4 type:2 val:1b001b old val:0 size:4
4 vaddr:874aac68 type:2 val:46 old val:5c size:4
5 vaddr:88c667b8 type:2 val:65 old val:8d size:4
6 vaddr:88c667d8 type:2 val:65 old val:8d size:4
7 vaddr:88c667f8 type:2 val:65 old val:8d size:4
8 vaddr:88c66818 type:2 val:65 old val:8d size:4
9 vaddr:88c66838 type:2 val:65 old val:6b size:4
===[KeepChanged]===
history count:4 [0:4326,1:71,2:46,3:40]
rollback count:0 []
result count:37
0 vaddr:8623e624 type:2 val:ba83126f old val:1b001b size:4
1 vaddr:8623e664 type:2 val:ff0909 old val:0 size:4
2 vaddr:874aac68 type:2 val:8 old val:46 size:4
3 vaddr:88c667b8 type:2 val:8d old val:65 size:4
4 vaddr:88c667d8 type:2 val:8d old val:65 size:4
5 vaddr:88c667f8 type:2 val:8d old val:65 size:4
6 vaddr:88c66818 type:2 val:8d old val:65 size:4
7 vaddr:88c66838 type:2 val:6b old val:65 size:4
8 vaddr:88c66858 type:2 val:6b old val:65 size:4
9 vaddr:88c66878 type:2 val:6b old val:65 size:4
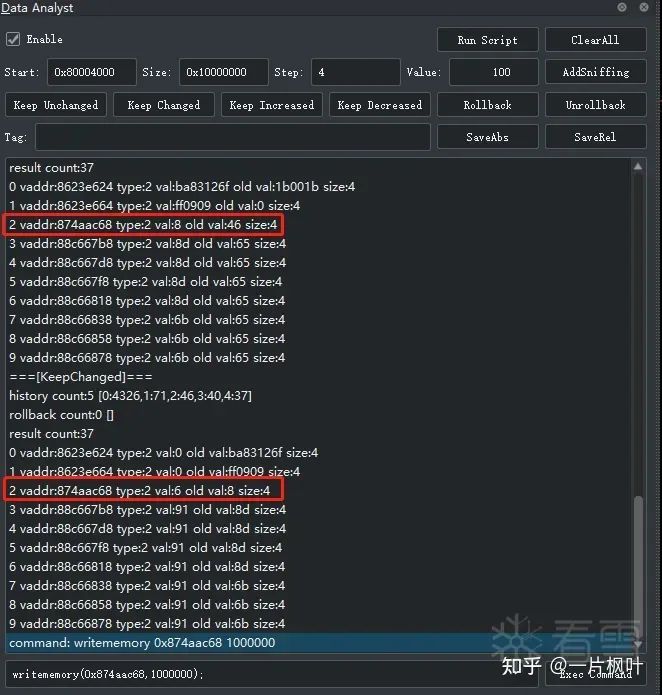
===[KeepChanged]===
history count:5 [0:4326,1:71,2:46,3:40,4:37]
rollback count:0 []
result count:37
0 vaddr:8623e624 type:2 val:0 old val:ba83126f size:4
1 vaddr:8623e664 type:2 val:0 old val:ff0909 size:4
2 vaddr:874aac68 type:2 val:6 old val:8 size:4
3 vaddr:88c667b8 type:2 val:91 old val:8d size:4
4 vaddr:88c667d8 type:2 val:91 old val:8d size:4
5 vaddr:88c667f8 type:2 val:91 old val:8d size:4
6 vaddr:88c66818 type:2 val:91 old val:8d size:4
7 vaddr:88c66838 type:2 val:91 old val:6b size:4
8 vaddr:88c66858 type:2 val:91 old val:6b size:4
9 vaddr:88c66878 type:2 val:91 old val:6b size:4
command: writememory 0x874aac68 1000000
archive.org/download/nx2elf2nso/nx2elf2nso.zip
先勾上这个:
clearpccount
startpccount
storepccount
keepnewpccount
savepccount l.txt
stoppccount
clearpccount
add_bpt(0x80040da8)
add_bpt(0x80040f40)
add_bpt(0x8017bfb0)
add_bpt(0x8017bfe8)
add_bpt(0x8017ca14)
add_bpt(0x80278028)
add_bpt(0x80278040)
add_bpt(0x80278224)
add_bpt(0x80278248)
add_bpt(0x8027824c)
add_bpt(0x802782f0)
"""
summary: programmatically drive a debugging sessiondescription:
Start a debugging session, step through the first five
instructions. Each instruction is disassembled after
execution.
"""import ida_dbg
import ida_ida
import ida_linesclass MyDbgHook(ida_dbg.DBG_Hooks):
""" Own debug hook class that implementd the callback functions """def __init__(self):
ida_dbg.DBG_Hooks.__init__(self) # important
self.steps = 0def log(self, msg):
print(">>> %s" % msg)def dbg_process_start(self, pid, tid, ea, name, base, size):
self.log("Process started, pid=%d tid=%d name=%s" % (pid, tid, name))def dbg_process_exit(self, pid, tid, ea, code):
self.log("Process exited pid=%d tid=%d ea=0x%x code=%d" % (pid, tid, ea, code))def dbg_library_unload(self, pid, tid, ea, info):
self.log("Library unloaded: pid=%d tid=%d ea=0x%x info=%s" % (pid, tid, ea, info))def dbg_process_attach(self, pid, tid, ea, name, base, size):
self.log("Process attach pid=%d tid=%d ea=0x%x name=%s base=%x size=%x" % (pid, tid, ea, name, base, size))def dbg_process_detach(self, pid, tid, ea):
self.log("Process detached, pid=%d tid=%d ea=0x%x" % (pid, tid, ea))def dbg_library_load(self, pid, tid, ea, name, base, size):
self.log("Library loaded: pid=%d tid=%d name=%s base=%x" % (pid, tid, name, base))def dbg_bpt(self, tid, ea):
self.log("Break point at 0x%x pid=%d" % (ea, tid))
# return values:
# -1 - to display a breakpoint warning dialog
# if the process is suspended.
# 0 - to never display a breakpoint warning dialog.
# 1 - to always display a breakpoint warning dialog.
del_bpt(ea)
ida_dbg.continue_process()
return 0def dbg_suspend_process(self):
self.log("Process suspended")def dbg_exception(self, pid, tid, ea, exc_code, exc_can_cont, exc_ea, exc_info):
self.log("Exception: pid=%d tid=%d ea=0x%x exc_code=0x%x can_continue=%d exc_ea=0x%x exc_info=%s" % (
pid, tid, ea, exc_code & ida_idaapi.BADADDR, exc_can_cont, exc_ea, exc_info))
# return values:
# -1 - to display an exception warning dialog
# if the process is suspended.
# 0 - to never display an exception warning dialog.
# 1 - to always display an exception warning dialog.
return 0def dbg_trace(self, tid, ea):
self.log("Trace tid=%d ea=0x%x" % (tid, ea))
# return values:
# 1 - do not log this trace event;
# 0 - log it
return 0def dbg_step_into(self):
self.log("Step into")def dbg_run_to(self, pid, tid=0, ea=0):
self.log("Runto: tid=%d, ea=%x" % (tid, ea))def dbg_step_over(self):
pc = ida_dbg.get_reg_val("PC")
disasm = ida_lines.tag_remove(
ida_lines.generate_disasm_line(
pc))
self.log("Step over: PC=0x%x, disassembly=%s" % (pc, disasm))# Remove an existing debug hook
try:
if debughook:
print("Removing previous hook ...")
debughook.unhook()
except:
pass# Install the debug hook
debughook = MyDbgHook()
debughook.hook()
debughook.unhook()
"""
summary: programmatically drive a debugging sessiondescription:
Start a debugging session, step through the first five
instructions. Each instruction is disassembled after
execution.
"""import ctypes
import ida_dbg
import ida_ida
import ida_lines
import ida_ieeeclass MyDbgHook(ida_dbg.DBG_Hooks):
""" Own debug hook class that implementd the callback functions """def __init__(self):
ida_dbg.DBG_Hooks.__init__(self) # important
self.steps = 0def log(self, msg):
print(">>> %s" % msg)def dbg_process_start(self, pid, tid, ea, name, base, size):
self.log("Process started, pid=%d tid=%d name=%s" % (pid, tid, name))def dbg_process_exit(self, pid, tid, ea, code):
self.log("Process exited pid=%d tid=%d ea=0x%x code=%d" % (pid, tid, ea, code))def dbg_library_unload(self, pid, tid, ea, info):
self.log("Library unloaded: pid=%d tid=%d ea=0x%x info=%s" % (pid, tid, ea, info))def dbg_process_attach(self, pid, tid, ea, name, base, size):
self.log("Process attach pid=%d tid=%d ea=0x%x name=%s base=%x size=%x" % (pid, tid, ea, name, base, size))def dbg_process_detach(self, pid, tid, ea):
self.log("Process detached, pid=%d tid=%d ea=0x%x" % (pid, tid, ea))def dbg_library_load(self, pid, tid, ea, name, base, size):
self.log("Library loaded: pid=%d tid=%d name=%s base=%x" % (pid, tid, name, base))def dbg_bpt(self, tid, ea):
self.log("Break point at 0x%x pid=%d" % (ea, tid))
regvals = ida_dbg.get_reg_vals(tid)
ix = 0
for regval in regvals:
f1 = 0.0
f2 = 0.0
f3 = 0.0
f4 = 0.0
num = regval.get_data_size()
if num==16:
bytes = regval.bytes()
data = bytearray(bytes)
fvals = struct.unpack("<4f", data)
f1 = fvals[0]
f2 = fvals[1]
f3 = fvals[2]
f4 = fvals[3]
self.log("reg:%d type:%d ival:%x size:%u fval:%f %f %f %f" % (ix, regval.rvtype, regval.ival, regval.get_data_size(), f1, f2, f3, f4))
ix += 1
# return values:
# -1 - to display a breakpoint warning dialog
# if the process is suspended.
# 0 - to never display a breakpoint warning dialog.
# 1 - to always display a breakpoint warning dialog.
ida_dbg.continue_process()
return 0def dbg_suspend_process(self):
self.log("Process suspended")def dbg_exception(self, pid, tid, ea, exc_code, exc_can_cont, exc_ea, exc_info):
self.log("Exception: pid=%d tid=%d ea=0x%x exc_code=0x%x can_continue=%d exc_ea=0x%x exc_info=%s" % (
pid, tid, ea, exc_code & ida_idaapi.BADADDR, exc_can_cont, exc_ea, exc_info))
# return values:
# -1 - to display an exception warning dialog
# if the process is suspended.
# 0 - to never display an exception warning dialog.
# 1 - to always display an exception warning dialog.
return 0def dbg_trace(self, tid, ea):
self.log("Trace tid=%d ea=0x%x" % (tid, ea))
# return values:
# 1 - do not log this trace event;
# 0 - log it
return 0def dbg_step_into(self):
self.log("Step into")def dbg_run_to(self, pid, tid=0, ea=0):
self.log("Runto: tid=%d, ea=%x" % (tid, ea))def dbg_step_over(self):
pc = ida_dbg.get_reg_val("PC")
disasm = ida_lines.tag_remove(
ida_lines.generate_disasm_line(
pc))
self.log("Step over: PC=0x%x, disassembly=%s" % (pc, disasm))# Remove an existing debug hook
try:
if debughook:
print("Removing previous hook ...")
debughook.unhook()
except:
pass# Install the debug hook
debughook = MyDbgHook()
debughook.hook()
看雪ID:dreaman
https://bbs.kanxue.com/user-home-34722.htm
# 往期推荐
2、Glibc-2.35下对tls_dtor_list的利用详解
球分享
球点赞
球在看
点击阅读原文查看更多
如有侵权请联系:admin#unsafe.sh