IntroductionShellcodes are machine instructions that are used as a payload in the 2024-3-29 21:53:15 Author: www.hackingarticles.in(查看原文) 阅读量:30 收藏
Introduction
Shellcodes are machine instructions that are used as a payload in the exploitation of a vulnerability. An exploit is a small code that targets a vulnerability. Shellcodes are written in assembly. We generally refer to sites like shell-storm.org to get shellcodes and attach them to our exploits. But how can we make our shellcodes?
This series of articles focuses on creating our shellcodes. In Part 1, we’d be understanding basic assembly instructions, writing our very first assembly code, and turning that into a shell code.
Table of Content
- Understanding CPU Registers
- First Assembly Program
- Assembling and Linking
- Extracting Shellcode
- Removing NULLs
- A sample shellcode execution
- Conclusion
Understanding CPU registers
“Assembly is the language of OS.” We have all read this in our computer science textbooks in high school. But how is assembly written? How is the assembly language able to control our CPU? How do we make our assembly program?
Before going into assembly, let’s understand our CPU registers. An x86-64 CPU has various 8-byte (64-bit) registers that can be used to store data, do computation, and other tasks. These registers are physical and embedded in the chip. They are lightning-fast and exponentially faster than the hard disk memory. If we can write a program only using registers, the time required to run it would virtually be instantaneous.
A CPU contains a Control Unit, Execution Unit among other things. This execution unit talks to Registers and Flags.

There are many registers on the CPU. But for this part, we only need to know about the general-purpose registers.

64-bit registers
(ref: researchgate.net)
So, in the image above we can see that there are legacy 8 registers (RAX, RBX, RCX, RDX, RDI, RSI, RBP, RSP) and then R8 to R15. These are the general-purpose registers. CPU may also have others like MMX which we’ll encounter later on.
Out of these, these 4 data registers are:
RAX – Accumulator. Used for input/output and most arithmetic operations.
RBX – Base Register. Used for stack’s index addressing
RCX – Count Register. Used for counting, like a loop counter.
RDX – Data register. Used in I/O operations along with RAX for multiply/divide involving large values.
Again, this is just the given function. We can modify and use these registers in other ways we like.
Next, 3 pointer registers are:
RIP – Instruction Pointer. Stores the offset of the next instruction to be executed.
RSP – Stack Pointer. Stores the memory address of the top of the stack.
RBP – Base Pointer. Makes the base of the stack frame for the current function. This makes it easier to access function parameters and local variables at fixed offsets from the RBP register. eg: RBP-4 would store the first integer variable defined in the program.
Finally, there are 2 Index registers:
RSI – Source Index. It is used as as source index for string operations mainly.
RDI – Destination Index. It is used as a destination index for string operations mainly.
Apart from these we have some control registers as well, known as flags. These flags hold values 0 and 1 for set and unset. Some of these are:
CF – Carry Flag. Used for carry and borrow in mathematical operations.
PF – Parity Flag. Used for errors while processing arithmeetic operations. If number of “1” bits are even then PF=0 else it is set as 1.
ZF – Zero Flag. Used to indicate the result of a previous operation. This would be used as the input of other operations like JZ,JNZ etc.
Now we are ready to write our first program in assembly.
First Assembly Program
An assembly program is written with usually 3 main sections:
- Text section – Program instructions are stored here
- Data section – Defined data is stored here
- BSS section – Undefined data is stored here.
It is also to note that there are 2 main assembly flavors in Linux 64-bit Assembly: AT&T syntax and Intel syntax.
If you have used GDB before, you’ll notice it automatically displays the assembly in AT&T syntax. This is a personal preference. Some people like seeing their assembly in this, but we would be using the Intel syntax because it seems a lot clearer.
Let’s write our first “Hello World” program.
We always start by defining our skeleton code. I’ll create a file with the extension “.asm”

We always start by defining a global directive. Since, unlike C, we don’t have a main function here to tell the compiler where a program starts from, in assembly, we use the symbol “_start” to define the start of the program. In section .text, we define the _start label to tell the assembler to start instructions from this point.
For full details about global directives, refer to this post.
Now, we have to define a message “Hello World.” Since this is a piece of data, it must come in .data section

This is how variables are declared:
<variable>: <data type> <value>
The name of the variable is “message”. It is defined as a sequence of bytes (db=define bytes) and ends with an end line (0xa is the hex value for “\n”).
For full details about data types in assembly, refer to this post.
Now that we have declared a message, we need instructions to print it.
It is important to know that assembly also uses the underlying system calls in an OS. In Linux OS, there are currently 456 system calls which are defined in /usr/include/x86-64-linux-gnu/unistd_64.h
You can also find an online searchable table here: https://filippo.io/linux-syscall-table/
The syscall used to print a message is “write.” It uses these arguments:

So, these syscalls essentially also use different registers to process and perform a task. Upon knowing more about what syscall requires in these registers we’d be able to perform any syscall. To perform write, we need these values in these registers:
rax -> 1
rdi -> 1 (stdout in Linux is defined by fd=1)
rsi -> Message to display
rdx -> length of the message (which is 12 including end line)
But how do we input these values in these registers? For this, in Assembly, there are many instructions. The most common instruction is “mov.” This moves values from:
- Between registers
- Memory to Registers and Registers to Memory
- Immediate data to registers
- Immediate data to memory
So, we will just move these values into dedicated registers and our code becomes like this:

However, manually calculating the length of messages may not be feasible. So, we’ll use a little trick. We’ll define a new variable for length and use “equ” which means equals proceeded by “$” which denotes the current offset and subtract our message’s beginning offset from this to find the length of the message.
We would further need to use the instruction “syscall” to also call the “write” syscall we just defined. Without using the “syscall” operation, write won’t be performed with register values.

Finally, we also need to exit from the program. sys_exit syscall in Linux performs this operation.

So, rax-> 60
And rdi-> any value we want for the error code. Let’s give this 0 for now.

Assembling and Linking
Now this code is ready to run. We always need to do these steps to run an assembly code:
- Assemble using nasm
- Link with necessary libraries using ld
An assembler produces object files as output. We then link it with necessary libraries that contain the definition of certain instructions and create an executable. We will use “nasm” to do the assembling and “ld” to link.
Since it is a 64-bit elf that we want, the command would become:
nasm -f elf64 1.asm -o 1.o ld 1.o -o 1 ./1

As we see, we have now generated an executable file that is printing “hello world.” Perfect. We can now proceed to create our shellcode using this binary.
Extracting shellcode
We created our assembly code and made an executable out of it that prints something. Let’s say a poor exploit (not a good one, haha) wants to exploit something with the payload to print “Hello World”. How would one do this?
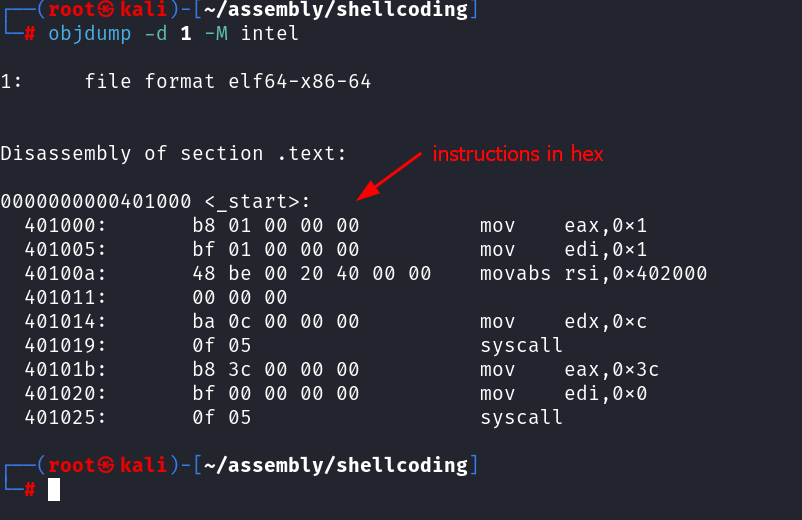
For this, we need to extract the instruction bytes from our executable. We can use objdump to do this
Upon seeing the binary with objdump, we can see our assembly code and the instructions in hex written alongside it. We are providing -M intel because we want the output in Intel assembly format.
objdump -d 1 -M intel

We all know computers only know binary. However, displaying binary on screen is not feasible. So, computer scientists used hex instructions. This gets translated into the CPU and the computer acts.
Removing NULLs
We need to extract these bytes and use them in our C code! Simple? BUT WAIT!
Another fundamental we know is that null bytes can sometimes terminate an action. So we must remove these null bytes from our shellcode to prevent any mishappening. To exactly know which instructions won’t generate null bytes comes with practice. But certain tricks can be used in simple programs to achieve this.
For example, using “xor rax,rax” would assign rax=0 since xoring anything with itself gives 0.

So, we can do “xor rax,rax” and then “add rax,1” to make RAX as 1.
In our code, you’ll observe every mov instruction creates 0s. So, if we have to assign a value of “1”, we can xor to make it 0 and then “add” 1. “Add” instruction simply adds the value given to the register mentioned.
Following this trick we can re-write our code like this:

Let’s see if we still have 0s or not.

We can still observe some 0s in movabs and mov instructions. We can use some tricks to reduce these 0s further.

This would still produce 0s near mov rsi, message. We can reduce this by using “lea.” “lea” command loads an address into the memory. This is also known as the “memory referencing.” We’ll see the details in a future article on rel and memory referencing.

We can still see 2 null bytes there but for now, this is workable. We can use the “jmp call pop” technique to remove this as well. Let’s talk about that in further articles.

This binary also works. Let’s extract these bytes and make it a shellcode. We can copy these manually too (tiring!) but let’s use a command line fu for this:
objdump -d ./PROGRAM | grep -Po '\s\K[a-f0-9]{2}(?=\s)' | sed 's/^/\\x/g' | perl -pe 's/\r?\n//' | sed 's/$/\n/'

Shellcode: \x48\x31\xc0\x48\x83\xc0\x01\x48\x31\xff\x48\x83\xc7\x01\x48\x8d\x35\xeb\x0f\x00\x00\x48\x31\xd2\x48\x83\xc2\x0c\x0f\x05\x48\x31\xc0\x48\x83\xc0\x3c\x48\x31\xff\x0f\x05
Sample shellcode execution
The shellcode we just created can not be executed in C programs because “Hello World” was being fetched as static data. For this, we will utilize another technique called JMP, CALL, and POP. This we will cover in the next article. For this part, let’s focus on executing a ready-made shellcode.
On sites like shell-storm.org, you would observe that the assembly of a program is given, and then the related shellcode as well. For example, here we see that an assembly program is written to execute “execve(/bin/sh)” which spawns up a new shell using the Linux system call “execve”

The shellcode observed is: \x31\xc0\x48\xbb\xd1\x9d\x96\x91\xd0\x8c\x97\xff\x48\xf7\xdb\x53\x54\x5f\x99\x52\x57\x54\x5e\xb0\x3b\x0f\x05
To execute this shellcode, we need to write a small C program. Here is a skeleton:
#include <stdio.h>
#include <string.h>
char code[] = "<shellcode>";
int main()
{
printf("len:%zu bytes\n", strlen(code));
(*(void(*)()) code)();
return 0;
}
So, the code becomes like so and we have to compile it with no modern compiler protections command. Also, note that we are using Ubuntu 14 to test our shellcode since even after no protections, modern systems may still block the execution of such shellcodes (due to memory permissions or ASLR issues) which we will tackle in future articles.

Now, we can run this binary and observe how it spawns a new shell!

Conclusion
In the article, we saw how we can write out our assembly programs using registers and Linux syscalls, make an executable, and then extract the instruction bytes using objdump. These instruction bytes can then be used as a payload in exploits. That is why it is called a shellcode. We created our shellcode which prints “Hello World” but we didn’t execute it in the C program. The reason was that “Hello World” was static data in the program that couldn’t be properly loaded in registers using the assembly we created. For this, we have to use a technique called JMP, CALL, POP and utilize stack for it. We shall see this in the next article. Thanks for reading this part of the series.
Author: Harshit Rajpal is an InfoSec researcher and left and right-brain thinker. Contact here
如有侵权请联系:admin#unsafe.sh