笔者主要负责美团内部操作系统安全、云原生安全、重大高危漏洞应急响应。10+年安全行业经验,熟悉多个安全领域,涉及渗透测试、Web安全、二进制安全、Iot安全、Linux/Android内核安全等,6+年的时间到至今,长期专注于Linux内核安全及开源软件安全。21岁时受邀在第一届中国互联网安全领袖峰会(CSS)演讲,知名Linux/Android内核远程漏洞CVE-2017-8890发现者。
云原生(Cloud Native)是一套技术体系和方法论。云原生(Cloud Native)由2个词组成,云(Cloud)和原生(Native)。云(Cloud)表示应用程序位于云中,而不是传统的数据中心;原生(Native)表示应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳状态运行,充分利用和发挥云平台的弹性和分布式优势。
笔者将“云原生安全”抽象成如上图所示的技术沙盘。自底向上看,底层从硬件安全(可信环境)到宿主机安全 。将容器编排技术(Kubernetes等)看作云上的“操作系统”,它负责自动化部署、扩缩容、管理应用等。在它之上由微服务、Service Mesh、容器技术(Docker等)、容器镜像(仓库)组成。它们之间相辅相成,以这些技术为基础构建云原生安全。
在美团内部镜像安全由容器镜像分析平台保障。它以规则引擎的形式运营监管容器镜像,默认规则支持对镜像中dockerfile、可疑文件、敏感权限、敏感端口、基础软件漏洞、业务软件漏洞以及CIS和NIST的最佳实践做检查,并提供风险趋势,同时它确保部分构建时安全。
运行安全管控交由HIDS负责(可以参考,分布式HIDS集群架构设计,文末链接2)。本文所讨论的范畴也属于运行安全之一,主要解决以容器逃逸为模型构建的风险(在本文中,若无特殊说明,容器指代Docker)。
近些年,数据中心的基础架构逐渐从传统的虚拟化(例如:KVM+Qemu架构)转向容器化(Kubernetes+Docker架构),但逃逸始终都是企业要在这2种架构下所需要面对的最严峻的安全问题,同时它也是容器风险中最具代表性的安全问题。笔者将以容器逃逸为切入点,从攻击者角度(容器逃逸)到防御者角度(缓解容器逃逸)去阐述容器安全实践,从而缓解容器风险。
Namespace创建一个近乎隔离的用户空间并为应用程序提供系统资源(文件系统、网络栈、进程和用户ID)。Cgroup强制限制硬件资源,如CPU、内存、设备和网络。
容器和VM不同之处在于,VM模拟硬件系统,每个VM都可以在独立环境中运行OS。管理程序模拟CPU、内存、存储、网络资源等,这些硬件可由多个VM共享多次。

容器一共有7个攻击面:Linux Kernel、Namespace/Cgroups/Aufs、Seccomp-bpf、Libs、Language VM、User Code、Container(Docker) engine。
笔者以容器逃逸为风险模型,提炼出3个攻击面:
1. Linux内核漏洞
2. 容器自身
3. 不安全部署(配置)
一、Linux内核漏洞
容器的内核与宿主内核共享,使用Namespace与Cgroups这两项技术使容器内的资源与宿主机隔离,所以Linux内核产生的漏洞能导致容器逃逸。
内核提权VS容器逃逸——通用Linux内核提权方法论
• 信息收集
收集一切对写exploit有帮助的信息。如:内核版本,需要确定攻击的内核是什么版本?这个内核版本开启了哪些加固配置?还需知道在写 shellcode 的时候会调用哪些内核函数?这时候就需要查询内核符号表,得到函数地址。还可从内核中得到一些对编写利用有帮助的地址信息、结构信息等等。
• 触发阶段
触发相关漏洞,控制RIP,劫持内核代码路径,简而言之获取在内核中任意执行代码的能力。
• 布置shellcode
在编写内核exploit代码的时候需要找到一块内存来存放我们的shellcode 。这块内存至少得满足两个条件:
第一:在触发漏洞的时候我们要劫持的代码路径,必须保证代码路径可以到达存放shellcode的内存。
第二:这块内存是可以被执行的,换句话说,存放 shellcode 的这块内存具有可执行权限。
• 执行阶段
第一:获取高于当前用户的权限,一般我们都是直接获取root 权限,毕竟它是 Linux 中最高权限,也就是执行我们的shellcode。
第二:保证内核稳定,不能因为我们需要提权而破坏原来内核的代码路径、内核结构、内核数据等等,使内核崩溃了,这样的话,即使得到 root 权限也没什么太大的意义。
简而言之,收集对编写exploit有帮助的信息,然后触发漏洞去执行特权代码,达到提权的效果。

容器逃逸和内核提权只有细微的差别,需要突破namespace的限制。将高权限的namespace赋到exploit进程的task_struct中。这部分的详细技术细节不在本文讨论范围内,笔者会抽空再写一篇关于容器逃逸的技术文章,详细介绍相关技术细节。
经典的DirtyCoW
笔者以Dirty CoW漏洞来说明Linux漏洞导致的容器逃逸。漏洞虽老,奈何太过经典。写到这,笔者不禁想问:多年过去,目前国内外各大厂,Dirty Cow漏洞的存量机器修复率是多少?
在Linux内核的内存子系统处理私有只读内存映射的写时复制(Copy-on-Write,CoW)机制的方式中发现了一个竞争冲突。一个没有特权的本地用户可能会利用此漏洞获得对其他情况下只读内存映射的写访问权限,从而增加他们在系统上的特权,这就是知名的Dirty CoW漏洞。
Dirty CoW漏洞的逃逸这里的实现思路和上述的思路不太一样,采取Overwrite vDSO技术。
vDSO(Virtual Dynamic Shared Object)是内核为了减少内核与用户空间频繁切换,提高系统调用效率而设计的机制。它同时映射在内核空间以及每一个进程的虚拟内存中,包括那些以root权限运行的进程。通过调用那些不需要上下文切换(context switching)的系统调用可以加快这一步骤(定位vDSO)。vDSO在用户空间(userspace)映射为R/X,而在内核空间(kernelspace)则为R/W。这允许我们在内核空间修改它,接着在用户空间执行。又因为容器与宿主机内核共享,所以可以直接使用这项技术逃逸容器。
利用步骤如下:
1.获取vDSO地址,在新版的glibc中可以直接调用getauxval()函数获取。
2.通过vDSO地址找到clock_gettime()函数地址,检查是否可以hijack。
3.创建监听socket。
4.触发漏洞,Dirty CoW是由于内核内存管理系统实现CoW时产生的漏洞。通过条件竞争,把握好在恰当的时机,利用CoW的特性可以将文件的read-only映射为write。子进程不停的检查是否成功写入。父进程创建二个线程,ptrace_thread线程向vDSO写入shellcode。
madvise_thread线程释放vDSO映射空间,影响ptrace_thread线程CoW的过程,产生条件竞争,当条件触发就能写入成功。
5.执行shellcode,等待从宿主机返回root shell,成功后恢复vDSO原始数据。
二、容器自身
我们先简单的看一下Docker的架构图:

Docker本身由docker(docker client)和dockerd(docker daemon)组成。但从Docker 1.11开始,Docker不再是简单的通过docker dameon来启动,而是集成许多组件,包括containerd、runc等等。
Docker client是docker的客户端程序,用于将用户请求发送给dockerd。dockerd实际调用的是containerd的api接口,containerd是dockerd和runc之间的一个中间交流组件,主要负责容器运行、镜像管理等。containerd向上为dockerd提供了gRPC接口,使得dockerd屏蔽下面的结构变化,确保原有接口向下兼容;向下,通过containerd-shim与runc结合创建及运行容器。更多的相关内容,请参考文末链接4、5、6。了解清楚这些之后,我们就可以结合自身的安全经验,从这些组件相互间的通信方式、依赖关系等寻找能导致逃逸的漏洞。
下面我们以docker中的runc组件所产生的漏洞来说明因容器自身的漏洞导致的逃逸。
CVE-2019-5736:runc - container breakout vulnerability
runc在使用文件系统描述符时存在漏洞,该漏洞可导致特权容器被利用,造成容器逃逸以及访问宿主机文件系统;攻击者也可以使用恶意镜像,或修改运行中的容器内的配置来利用此漏洞。
• 攻击方式1:(该途径需要特权容器) 运行中的容器被入侵,系统文件被恶意篡改 ==> 宿主机运行 docker exec命令 在该容器中创建新进程 ==> 宿主机runc被替换为恶意程序 ==> 宿主机执行 docker run/exec 命令时触发执行恶意程序;
• 攻击方式2:(该途径无需特权容器) docker run 命令启动了被恶意修改的镜像 ==> 宿主机 runc 被替换为恶意程序 ==> 宿主机运行 docker run/exec 命令时触发执行恶意程序;
当runc在容器内执行新的程序时,攻击者可以欺骗它执行恶意程序。通过使用自定义二进制文件替换容器内的目标二进制文件来实现指回runc二进制文件。
例如,如果目标二进制文件是/bin/bash,这可以用指定解释器的可执行脚本替换#!/proc/self/exe;因此,在容器内执行/bin/bash,/proc/self/exe的目标将被执行,将目标指向runc二进制文件。
然后攻击者可以继续写入/proc/self/exe目标,尝试覆盖主机上的runc二进制文件。这里需要使用O_PATH flag打开/proc/self/exe文件描述符,然后以O_WRONLY flag 通过/proc/self/fd/<nr>重新打开二进制文件,并且用单独的一个进程不停地写入。当写入成功时,runc会退出。
三、不安全部署(配置)
在实际中,经常会遇到这种状况:不同的业务会根据自身业务需求有自己的一套配置,而这套配置并未得到有效的管控审计,使得内部环境变的复杂多样,无形之中又增加了许多风险点。譬如,最常见的:
1.特权容器或者以root权限运行容器。
2.不合理的Capability配置(权限过大的Capability)。
面对特权容器,在容器内简单的执行一下命令就可以轻松的在宿主机上留下后门。

在美团内部已经有效的收敛了特权容器问题。
这部分业界已经给出了最佳实践,从宿主机配置、Dockerd配置、容器镜像、Dockerfile、容器运行时等方面保障安全,更多细节请参考文末链接10,同时Docker官方已经将其实现成自动化工具(见文末链接11)。
#2安全实践
为解决上述部分所阐述的容器逃逸问题,下文将重点从隔离(安全容器)与加固(安全内核)两个角度去讨论。
一、安全容器
安全容器的技术本质其实就是隔离。gVisor和Kata Container是比较具有代表性的实现方式,当然目前学术界有在探索基于Intel SGX的安全容器。
简单的说,gVisor是在用户态和内核态之间抽象出一层,封装成API,有点像user-mode kernel,以此实现隔离;Kata Container是采用轻量级虚拟机隔离,与传统的VM比较类似,但是它实现了无缝集成当前的Kubernetes加Docker架构。我们接着来看gVisor与Kata Container的异同。
Case 1: gVisor
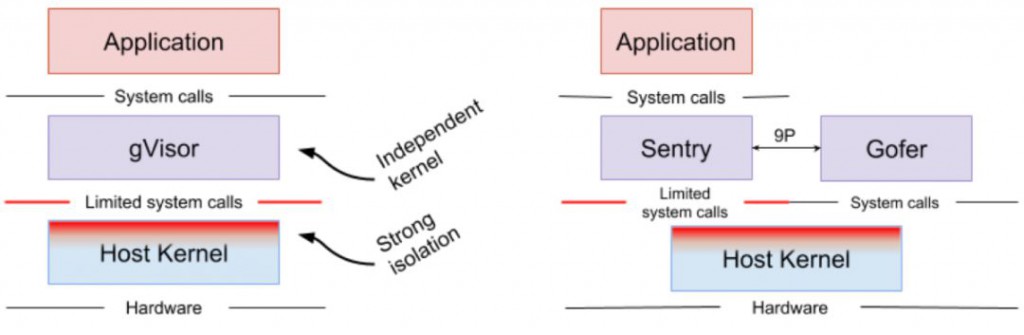
gVisor是用Golang编写的用户态内核,或者说是沙箱技术,它主要实现了大部分的system call。它运行在应用程序和内核之间,为它们提供隔离。gVisor被使用在Google云计算平台的App Engine、Cloud Functions和Cloud ML中。gVisor运行时,是由多个沙箱组成,这些沙箱进程共同覆盖了一个或多个容器。通过拦截从应用程序到主机内核的所有系统调用并使用用户空间中的Sentry处理它们,gVisor充当guest kernel的角色,且无需通过虚拟化硬件转换,可以将他看做vmm与guest kernel的集合,或是seccomp的增强版。

Case 2: Kata Container
Kata Container的Container Runtime 是用 hypervisor ,是用 hardware virtualization 实现的,如同虚拟机。所以每一个像这样的 Kata Container 的 Pod,都是一个轻量级虚拟机,它是拥有完整的 Linux 内核。所以 Kata Container 与 VM 一样能提供强隔离性,但由于它的优化和性能设计,它拥有与容器相媲美的敏捷性。

{kind=link}
{kind=link}
Kata Container在主机上有一个kata-runtime来启动和配置新容器。对于Kata VM中的每个容器,主机上都有相应的Kata Shim。Kata Shim接收来自客户端的API请求(例如:docker或kubectl),并通过VSock将请求转发给Kata VM内的代理。Kata容器进一步优化以减少VM启动时间。使用QEMU的轻量级版本NEMU,删除了约80%的设备和包。VM-Templating创建运行Kata VM实例的克隆,并与其他新创建的Kata VM共享,这样减少了启动时间和Guest VM内存消耗。Hotplug功能允许VM使用最少的资源(例如:CPU,内存,virtio块)进行引导,并在以后请求时添加其他资源。
gVisor VS Kata Container

在二者之间笔者更愿选择gVisor,因为gVisor设计上相比与Kata Container更加“轻”量级,但gVisor的性能问题始终是一道暂时无法逾越的槛。综合二者的优劣,Kata Container目前来看会更适合企业内部。总体而言,安全容器技术还需做诸多探索,以解决不同企业内部基础架构上面临的挑战。
二、安全内核
众所周知,Android由于不同厂商都维护着自己的Android版本,又因为Android 内核态代码来自于Linux kernel upstrem,当一个漏洞产生在upstrem内核,安全补丁推送到Google,再从Google下发到各大厂商,最终到终端用户。Android 生态的碎片化,补丁周期非常之长,使得终端用户的安全,在这过程中始终处于“空窗期”。把目光重新聚焦在Linux上,它也同样存在类似的问题。
1.内核面临的问题

• 内核补丁
当一个安全漏洞被披露,通常是由漏洞发现者通过Redhat、OpenSuse、Debian等社区反馈或直接提交至上游相关子系统maintainer。在企业内部面临多个不同内核大版本、内核定制化,针对不同版本从上游代码backport相关补丁及制作相关热补丁,定制内核还需对补丁进行二次开发,再升级生产环境内核或hotfix内核。不仅修复周期过长,而且推进修复过程人员沟通也存在成本,拉长了漏洞危险期。在危险期间对于漏洞是毫无防护能力的。
• 内核版本碎片化
内核版本碎片化在任意具备一定规模的公司都是无法避免的问题。随着技术日新月异,不断迭代,基础架构上的技术栈需要较新版本的内核功能去支持,久而久之产生内核版本碎片化。碎片化问题的存在,使得在安全补丁的推送方面,遭遇了很大的挑战。本身补丁还需要做针对性的适配,包括不同版本的内核,并进行测试验证,碎片化使得维护成本也十分高昂。最重要的是,由于维护工作量大,必然拉长了测试补丁的时间线。也就是说,暴露在攻击者面前的危险期变得更长,被攻击的可能性大大增加。
• 内核版本定制化
同样,因不同公司的基础架构不同、需求不同,导致的定制化内核问题。对于定制化内核,无法简单的通过从上游内核合并补丁,还需对补丁做一些本地化来适配定制化内核。这又拉长了危险期。
#3解决之道
我们使用安全特性去针对某一类漏洞或是针对某一类利用方式做防御与检测。比如SLAB_FREELIST_HARDENED,针对double free类型漏洞做实时检测,且防御overwrite freelist链表,性能损耗仅0.07%(参考upstrem内核源码,commit id: 2482ddec)。
当完成所有全部安全特性,漏洞在被反馈之前和漏洞补丁被及时推送至生产环境前,无需关心漏洞的细节,就能防御。当然,安全补丁该打还是得打的,这里我们主要解决在安全补丁最终落在生产环境过程中“空窗期”对于漏洞与利用毫无防御能力的问题,同时也可以对0day有一定的检测及防御能力。
实施策略
1. 已经合并进Linux主线版本的安全特性,如果公司的内核支持该特性,选择开启配置,对开启前后内核做性能测试,分析安全特性原理,行业数据,给出real world攻击案例(自己写exploit去证明),将报告结论反馈给内核团队,内核团队再做评估,结合安全团队与内核团队双方意见,最终评估落地。
2. 已经合并进Linux主线版本但未被合并进Redhat的安全特性,可选择从Linux内核主线版本中移植,这点上代码质量上得到了保障,同时社区也做了性能测试,将其合并到公司的内核再做复测。
3. 未被合并进Linux内核主线版本,从Grsecurity/PaX中做移植,在Grsecurity/PaX的诸多安全特性中,评估选择,选取代码改动少的,收益高的安全特性优先移植,比如改动较少的内核代码又能有效解决某一类的漏洞,再打个比方,dirty cow的全量修复可能需要花费1-2年,加了某个安全特性,即使未修复也能防御。
#4内核后话
最后,分享一下笔者眼中较为理想中的状况。当然,我们得根据实际情况“因地制宜”,在不同阶段做出不同的取舍与选择。
将内核团队看成社区,我们向他们提交代码,如同Linux内核社区有RFC(Request for Comment)、patch review等,无争议后合并进公司内核。
先挑选实用的安全特性且代码量少的,去移植,去实现,并落地。代码量少意味着,对内核代码改动少,出问题的可能性越小,稳定性越高,性能损耗越低。
一年完成几个安全特性,不需要多,1~2个即可,对于内核态的加固,慎重慎重再慎重,譬如国外G家公司数据中心的内核发版前大概需要6~7个月时间做性能、稳定性测试。
需要做到加固某个安全特性后,使用0day或Nday去验证防御效果,且基于该内核跑业务是稳定,性能损耗在可接受范围之内或者可控。每个安全特性需要技术评审。为保障代码质量的问题,找实际的高吞吐以及高并发低延迟的服务器小范围灰度测试,无争议后,推送给内核团队。
最后,还可以通过将安全特性的代码直接提交给Linux内核社区,如果代码有不足的地方也可以和社区协同解决,合并进Linux内核主线代码,从而侧面推动落地。
如有侵权请联系:admin#unsafe.sh