
04/03/2024
13 min read

Delivering great user experiences with a global user base can be challenging. While serving requests quickly when you start out in a local market is straightforward, doing so for a global audience is much more difficult. Why? Even under optimal conditions, you cannot be faster than the speed of light, which brings single data center solutions to their performance limits.
In this post, we will cover how Picsart improved the performance of one of its most critical services by moving from a centralized architecture to a globally distributed service built on Cloudflare. Our serverless compute platform, Workers, distributed throughout 310+ cities around the world, and our globally distributed Workers KV storage allowed them to improve their performance significantly and drive real business impact.
Success driven by data-driven insights
Picsart is one of the world’s largest digital creation platforms and a long-standing Cloudflare partner. At its core, an advanced tech stack powers its comprehensive features, including AI-driven photo and video editing tools and community-driven content sharing. With its infrastructure spanning across multiple cloud environments and on-prem deployments, Picsart is engineered to handle billions of daily requests from its huge mobile and web user base and API integrations. For over a decade, Cloudflare has been integral to Picsart, providing support for performant content delivery and securing its digital ecosystem.
Similar to many other tech giants, Picsart approaches product development in a data-driven way. At the core of the innovation is Picsart's remote configuration and experimentation platform, which enables product managers, UX researchers, and others to segment their user base into different test groups. These test groups might get to see slightly different implementations of features or designs of the Picsart app. Users might also get early access to experimental features or see different in-app promotions. In combination with constant monitoring of relevant KPIs, this allows for informed product decisions based on user preference and business impact.
On each app start, the client device sends a request to the remote configuration service for the latest setup tailored to the user's session. The assignment of experiments relies on factors like the operating system and previous sessions, making each request unique and uncachable. Picsart's app showcases extensive remote configuration capabilities, enabling adjustments to nearly every element. This results in a response containing a 1.5 MB configuration file for mobile clients. While the long-term solution is to reduce the file size, which has grown over time as more teams adopted the powerful service, this is not possible in the near or mid-term as it requires a major rewrite of all clients.
This setup request is blocking in the "hot path" during app start, as the results of this request will decide how the app itself looks and behaves. Hence, performance is critical. To ensure users are not waiting for too long, Picsart apps will wait for 1500ms on mobile for the request to complete – if it does not, the user will not be assigned a test group and the app will fallback to default settings.
The clock is ticking
While a 1500ms round trip time seems like a sufficiently large time budget, the data suggested otherwise. Before the improvements were implemented, a staggering 50% of devices could not complete the requests in time. How come? In these 1.5 seconds the following steps need to complete:
- The request must travel from the users’ devices to the centralized backend servers
- The server processes the request based on dozens of user attributes provided in the request and thousands of defined remote configuration variations, running experiments, and segments metadata. Using all the info, the server selects the right variation of each remote setting entry and builds the response payload.
- The response must travel from the centralized backend servers to the user devices.
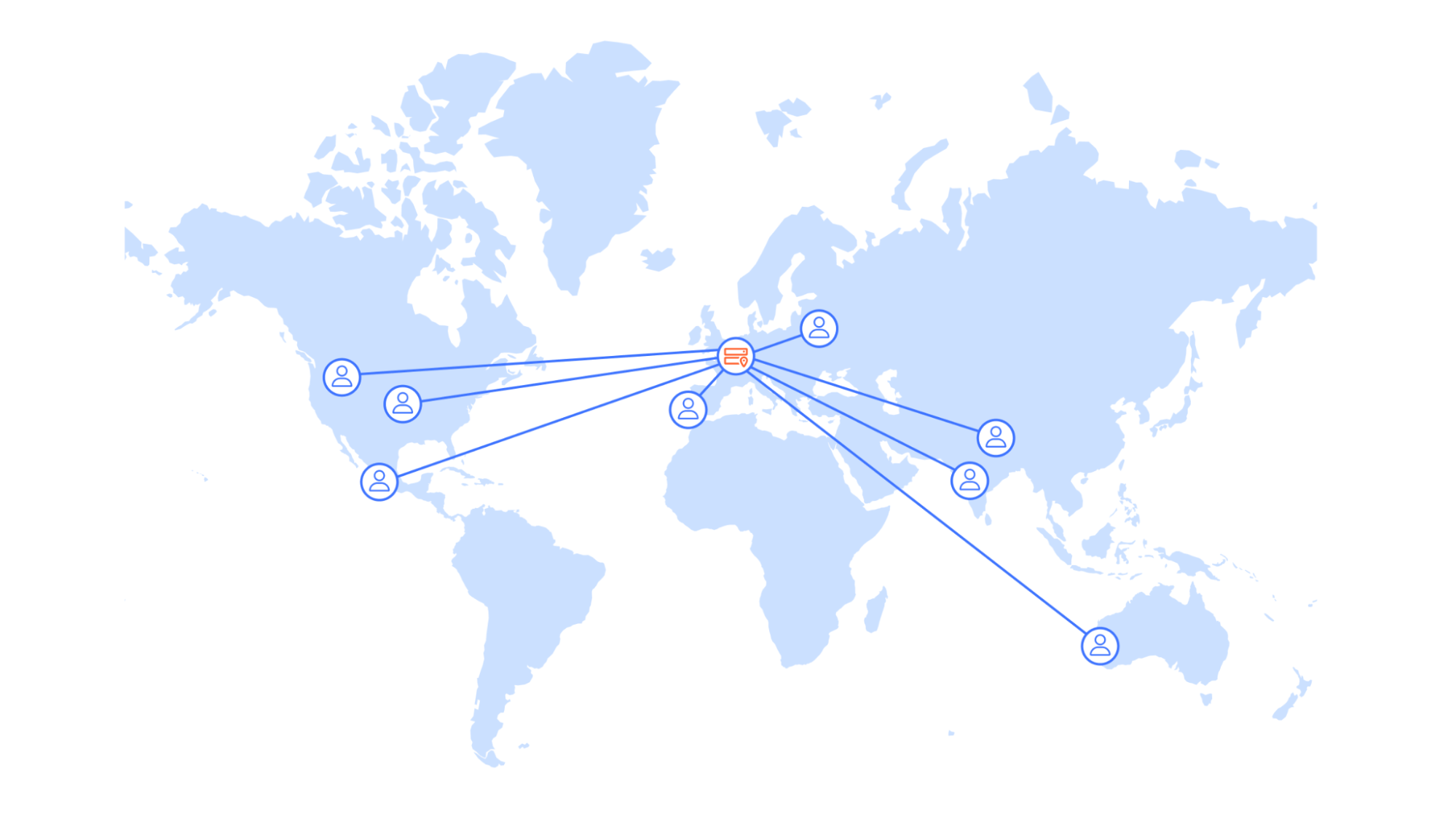
Looking at the data, it was clear to the Picsart team that their backend service was already well-optimized, taking only 30 milliseconds, a tiny fraction of the available time budget, to process each of the billions of monthly requests. The bulk of the request time came from network latency. Especially with mobile devices, last mile performance can be very volatile, eating away a significant amount of the available time budget. Not only that, but the data was clear: users closer to the origin server had a much higher chance of making the round trip in time versus users out of region. It quickly became obvious that Picsart, fueled by its global success, had outgrown a single-region setup.
To the drawing board
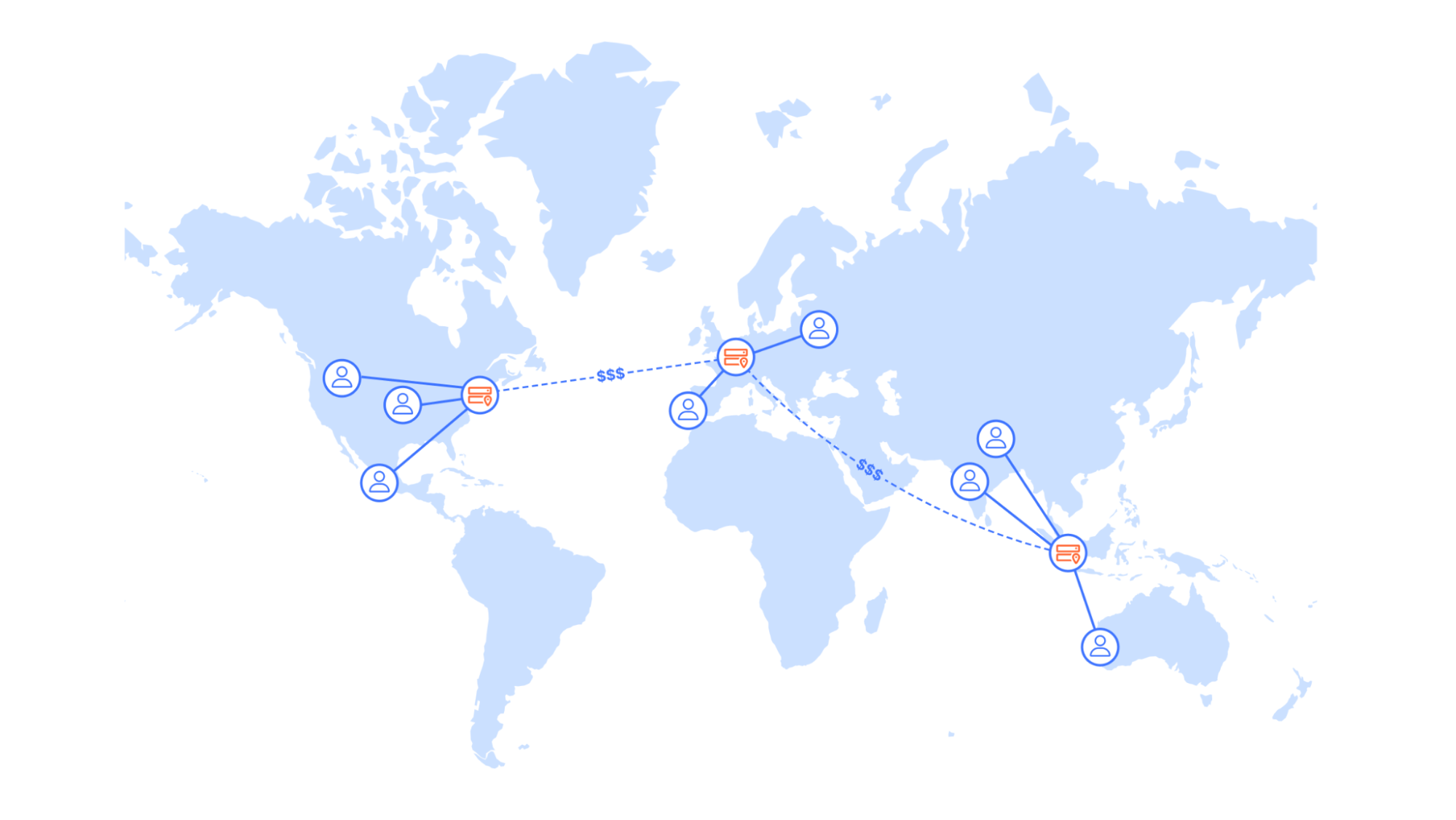
A solution that comes to mind would be to replicate the existing cloud infrastructure in multiple regions and use global load balancing to minimize the distance a request needs to travel. However, this introduces significant overhead and cost. On the infrastructure side, it is not only the additional compute instances and database clusters that incur cost, but also cross-region data transfer to keep data in sync. Moreover, technical teams would need to operate and monitor infrastructure in multiple regions, which can add a lot to the complexity and cognitive load, leading to decreased development velocity and productivity loss.
Picsart instead looked to Cloudflare – we already had a long-lasting relationship for Application Performance and Security, and they aimed to use our Developer Platform to tackle the problem.
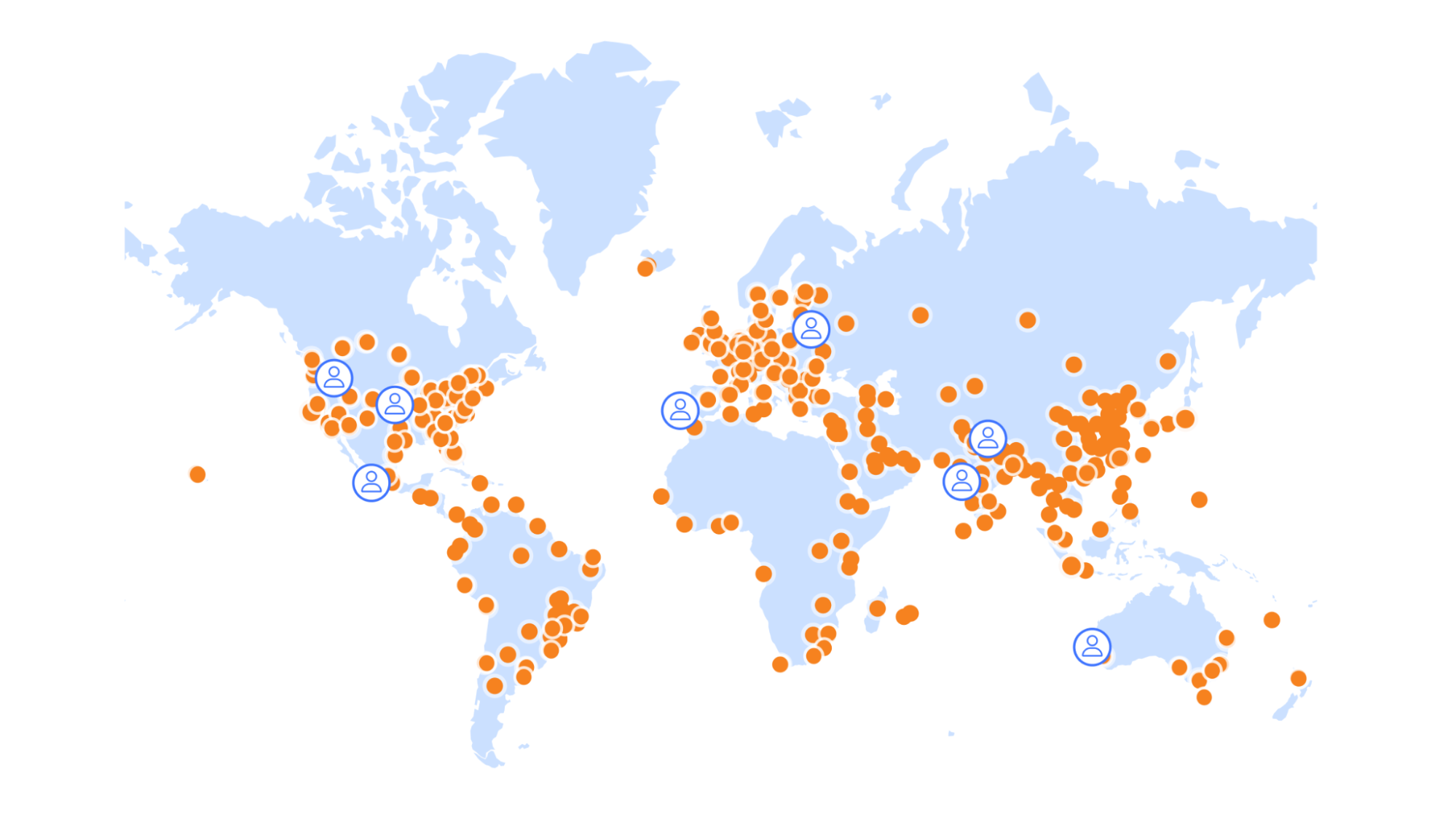
Workers and Workers KV seemed like the ideal solution. Both compute and data are globally distributed in 310+ locations around the world, resulting in a shorter distance between end users and the experimentation service. Not only that, but Cloudflare's global-by-default approach allows for deployment with minimal overhead, and in contrast to other considered solutions, no additional fees to distribute the data around the globe.
No race without a clock
The objective for the refactor of the experimentation service was to increase the share of devices that successfully receive experimentation configuration within the set time budget.
But how to measure success? While synthetic testing can be useful in many situations, Picsart opted to come up with another clever solution:
During development, the Picsart engineers had already added a testing endpoint to the web and mobile versions of their app that sends a duplicate request to the new endpoint, discarding the response and swallowing all potential errors. This allows them to collect timing data based on real-user metrics without impacting the app's performance and reliability.
A simplified version of this pattern for a web client could look like this:
// API endpoint URLs
const prodUrl = 'https://prod.example.com/';
const devUrl = 'https://new.example.com/';
// Function to collect metrics
const collectMetrics = (duration) => {
console.log('Request duration:', duration);
// …
};
// Function to fetch data from an endpoint and call collectMetrics
const fetchData = async (url, options) => {
const startTime = performance.now();
try {
const response = await fetch(url, options);
const endTime = performance.now();
const duration = endTime - startTime;
collectMetrics(duration);
return await response.json();
} catch (error) {
console.error('Error fetching data:', error);
}
};
// Fetching data from both endpoints
async function fetchDataFromBothEndpoints() {
try {
const result1 = await fetchData(prodUrl, { method: 'POST', ... });
console.log('Result from endpoint 1:', result1);
// Fetching data from the second endpoint without awaiting its completion
fetchData(devUrl, { method: 'POST', ... });
} catch (error) {
console.error('Error fetching data from both endpoints:', error);
}
}
fetchDataFromBothEndpoints();
Using existing data analytics tools, Picsart was able to analyze the performance of the new services from day one, starting with a dummy endpoint and a 'hello world' response. And with that a v0 was created that did not have the correct logic just yet, but simulated reading multiple values from KV and returning a response of a realistic size back to the end user.
The need for a do-over
In the initial phase, outcomes fell short of expectations. Surprisingly, requests were slower despite the service's proximity to end users. What caused this setback? Subsequent investigation unveiled multiple culprits and design patterns in need for optimization.
Data segmentation
The previous, stateful solution operated on a single massive "blob" of data exceeding 100MB in value. Loading this into memory incurred a few seconds of initial startup time, but once the VM completed the task, request handling was fast, benefiting from the readily available data in memory.
However, this approach doesn't seamlessly transition to the serverless realm. Unlike long-running VMs, Worker isolates have short lifespans. Repeatedly parsing large JSON objects led to prolonged compute durations. Simply parsing four KV entries of 25MB each (KV maximum value size is 25MB) on each request was not a feasible option.
The Picsart team went back to solution design and embarked on a journey to optimize their system's execution time, resulting in a series of impactful improvements.
The fundamental insight that guided the solution was the unnecessary overhead that was involved in loading and parsing data irrelevant to the user's specific context. The 100MB configuration file contained configurations for all platforms and locations worldwide – a setup that was far from efficient in a globally distributed, serverless compute environment. For instance, when processing requests from users in the United States, there was no need to fetch configurations targeted for users in other countries, or for different platforms.
To address this inefficiency, the Picsart team stored the configuration of each platform and country in separate KV records. This targeted strategy meant that for a request originating from a US user on an Android device, our system would only fetch and parse the KV record specific to Android users in the US, thereby excluding all irrelevant data. This resulted in approximately 600 KV records, each with a maximum size of 10MB. While this leads to data duplication on the KV storage side, it decreases the amount of data that needs to be parsed upon request. As Cloudflare operates in over 120 countries around the world, only a subset of records were needed in each location. Hence, the increase in cardinality had minimal impact on KV cache performance, as demonstrated by more than 99.5% of KV reads being served from local cache.
| Key | Size |
| settings_part1.json | 25MB |
| settings_part2.json | 25MB |
| … | …. |
| Key | Size |
| com.picsart.studio_apple_us.json | 6.1MB |
| com.picsart.studio_apple_de.json | 6.1MB |
| com.picsart.studio_android_us.json | 5.9MB |
| … | … |
This approach was a significant move for Picsart as they transitioned from a regional cloud setup to Cloudflare's globally distributed connectivity cloud. By serving data from close proximity to end user locations, they were able to combat the high network latency from their previous setup. This strategy radically transformed the data-handling process. which unlocked two major benefits:
- Performance Gains: By ensuring that only the relevant subset of data is fetched and parsed based on the user's platform and geographical location, wall time and compute resources required for these operations could be significantly reduced.
- Scalability and Flexibility: the granular segmentation of data enables effortless scaling of the service for new features or regional content. Adding support for new applications now only requires inserting new, standalone KV records in contrast to the previous solution where this would require increasing the size of the single record.
Immutable updates
Now that changes to the configuration were segmented by app, country, and platform, this also allowed for individual updates of the configuration in KV. KV storage showcases its best performance when records are updated infrequently but read very often. This pattern leverages KV's fundamental design to cache values at edge locations upon reads, ensuring that subsequent queries for the same record are swiftly served by local caches rather than requiring a trip back to KV's centralized data centers. This architecture is fundamental for minimizing latency and maximizing the speed of data retrieval across a globally distributed platform.
A crucial requirement for Picsart’s experimentation system was the ability to propagate updates of remote configuration values immediately. Updating existing records would require very short cache TTLs and even the minimum KV cache TTL of 60 seconds was considered unacceptable for the dynamic nature of the feature flagging. Moreover, setting short TTLs also impacts the cache hit ratio and the overall KV performance, specifically in regions with low traffic.
To reconcile the need for both rapid updates and efficient caching, Picsart adopted an innovative approach: making KV records immutable. Instead of modifying existing records, they opted to create new records with each configuration change. By appending the content hash to the KV key and writing new records after each update, Picsart ensured that each record was unique and immutable. This allowed them to leverage higher cache TTLs, as these records would never be updated.
| Key | Size |
| com.picsart.studio_apple_us.json | 60s |
| … | …. |
| Key | Size |
| com.picsart.studio_apple_us_b58b59.json | 86400s |
| com.picsart.studio_apple_us_273678.json | 86400s |
| - | … |
There was a catch, though. The service must now keep track of the correct KV keys to use. The Picsart team addressed this challenge by storing references to the latest KV keys in the environment variables of the Worker.
Each configuration change triggers a new KV pair to be written and the services' environment variables to be updated. As global Workers deployments take mere seconds, changes to the experimentation and configuration data are near-instantaneously globally available.
JSON serialization & alternatives
Following the previous improvements, the Picsart team made another significant discovery: only a small fraction of configuration data is needed to assign the experiments, while the remaining majority of the data comprises JSON values for the remote configuration payloads. While the service must deliver the latter in the response, the data is not required during the initial processing phase.
The initial implementation used KV's get() method to retrieve the configuration data with the parameter type=json, which converts the KV value to an object. This process is very compute-intensive compared to using the get() method with parameter type= text, which simply returns the value as a string. In the context of Picsart's data, the bulk of the CPU cycles were wasted on serializing JSON data that is not needed to perform the required business logic.
What if the data structure and code could be changed in such a way that only the data needed to assign experiments was parsed as JSON, while the configuration values were treated as text? Picsart went ahead with a new approach: splitting the KV records into two, creating a small 300KB record for the metadata, which can be quickly parsed to an object, and a 9.7MB record of configuration values. The extracted configuration values are delimited by newline characters. The respective line number is used as reference in the metadata entry, so that the respective configuration value for an experiment can be merged back into the payload response later.
{
|
|
|
|
|
// com.picsart.studio_apple_am_metadata
|
// com.picsart.studio_apple_am_values
|
|
|
|
After calculating the experiments and selecting the correct variants based solely on the small metadata entry, the service constructs a JSON string for the response containing placeholders for the actual values that reference the corresponding line numbers in the separate text file. To finalize the response, the server replaces the placeholders with the corresponding serialized JSON strings from the text file. This approach circumvents the need for parsing and re-serializing large JSON objects and helps to avoid a significant computational overhead.
Note that the process of parsing the metadata JSON and determining the correct experiments as well as the loading of the large file with configuration values are executed in parallel, saving additional milliseconds.
By minimizing the size of the JSON data that needed to be parsed and leveraging a more efficient method for constructing the final response, the Picsart team managed to not only reduce the response times but also optimize the compute resource usage. This approach reflects a broader principle applicable across the tech industry: that efficiency, particularly in serverless architectures, can often be dramatically improved by rethinking data structure and utilization.
Getting a head start
The changes on the server-side, moving from a single region setup to Cloudflare’s global architecture, paid off massively. Median response times globally dropped by more than 1 second, which was already a huge improvement for the team. However, in looking at the new data, two more paths for client-side optimizations were found.
As the web and mobile app would call the service at startup, most of the time no active connections to the servers were alive and establishing that connection at request time costs valuable milliseconds.
For the web version, setting a pre-connect header on initial page load showed a positive impact. For the mobile app version, the Picsart team took it a step further. Investigation showed that before the connection could be established, three modules had to complete initialization: the error tracker, the HTTP client, and the SDK. Reordering of the modules to initialize the HTTP client first allowed for connection establishment in parallel to the initialization of the SDK and error tracker, again saving time. This resulted in another 200ms improvement for end users.
Setting a new personal best
The day had come and it was time for the phased rollout, web first and the mobile apps second. With suspense, the team looked at the dashboards, and were pleasantly surprised. The rollout was successful and billions of requests were handled with ease.
The result? The Picsart apps are loading faster than ever for millions of users worldwide, while the share of successfully delivered experiments increased from 50% to 85%. Median response time dropped from 1500 ms to 280 ms. The response time dropped to 70 ms on the web since the response size is smaller compared to mobile. This translates to a real business impact for Picsart as they can now deliver more personalized and data-driven experiences to even more of their users.
A bright future ahead
Picsart is already thinking of the next generation of experimentation. To integrate with Cloudflare even further, the plan is to use Durable Objects to store hundreds of millions of user data records in a decentralized fashion, enabling even more powerful experiments without impacting performance. This is possible thanks to Durable Objects' underlying architecture that stores the user data in-region, close to the respective end user device.
Beyond that, Picsart’s experimentation team is also planning to onboard external B2B customers to their experimentation platform as Cloudflare's developer platform provides them with the scale and global network to handle more traffic and data with ease.
Get started yourself
If you’re also working on or with an application that would benefit from Cloudflare’s speed and scale, check out our developer documentation and tutorials, and join our developer Discord to get community support and inspiration.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.