一. 软件组成成分分析主要背景
软件成分分析(SCA)旨在识别和管理软件项目中包含的开源组件,其中组件指的是重用的 TPL 及其对应的版本。基于 SCA 的结果,开发人员可以有效地跟踪软件项目的潜在威胁,如漏洞传播和许可证违规。
在检测目标中,目前主要包含两部分,一是源码、二是二进制文件。源码面对的主要场景为开发完成后对源码进行扫描,二进制文件为采购、引入的软件分析是否有安全危险。
二. 源码组成成分分析方法概述
基于源码的软件组成成分分析依赖于两种分析方法:一是基于构建文件的软件组成成分分析方法,二是基于代码相似度的软件组成成分分析方法。
基于构建文件的软件组成成分分析方法,一般是检测安装过程的“安装痕迹”,即各个语言的构建文件(c语言的MakeFile文件、Maven项目的pom.xml文件等)分析得到被测项目使用了哪些第三方组件,因此该类方法主要是实现各类文件的分析算法提取部署组件库的名字以及版本,不需要大量的存储空间,耗费时间短,但是分析结果的准确性非常差,一是大部分安装痕迹非常模糊,对于很多正确的组件名以及版本无法正确的判断,二是很多组件,用户会选择性安装,而不是全部安装,比如仅在开发中使用的测试组件,requirement.txt标记的“extra == dev”,而工具无法判断用户是否真正安装这类组件,因此关联出大量漏洞、许可威胁,产生告警疲劳,使得修复人员对于威胁疲于奔命。
基于代码相似度的组成成分分析方法需要两部分,一是相似度比对方法,二是各个组件版本代码特征库。对项目内代码与组建的特征库特征进行比较,若是相似度达到一定阈值,则认为使用了该组件。由于商业原因,笔者无法接触到各个SCA厂商的数据库,不能确定其所用的算法和特征抽取方法。但大部分组件的特征抽取采用了基于目录以及摘要的默克尔树变体的方法[1]进行生成,在大规模组件库的背景下,能够进行快速计算、缩小存储空间。
图一 基于目录以及摘要的默克尔树变体的代码相似度识别方法
基于构建文件、代码相似度的软件组成成分分析方法适用领域各有不同,针对于Java、Python等语言具有完备的构建过程以及开发管理仓库,大部分人的开发行为、流程应用到统一的构建过程,适用于基于构建文件的成分分析方法,对于组件分布广泛的 C/C++ 生态系统,开发人员往往手动导入组件,因此适用于基于代码相似度的组成成分分析方法。
基于构建文件、代码相似度的软件组成成分分析方法优缺点不同,基于构建文件的成分分析方法速度快、效率高、占用空间小、准性差、高度依赖于分析算法,基于代码相似度的软件组成成分分析算法即使只是抽取了代码的摘要,面对海量组件的情况下仍然占用空间大,因需要对海量组件进行匹配,分析速度慢,但是准确率高,高度依赖于摘要抽取算法,例如oauthlib组件为了修复CVE-2022-36087漏洞,仅仅修改了IPv6addres正则表达式中的10个字符升级成了新的版本,摘要抽取算法必须对目录、文件结构、变量等数据抽取的精准才能对组件的各个版本非常敏感。
三. 二进制组成成分分析方法背景
二进制软件在代码形成二进制文件的过程中会损失大量的特征,以C++为例,在编译过程中GCC提供了O₀-O₃四种优化模式供开发者选择,随着优化级别的提升,代码损失的信息越多。
由一份相同的代码形成的二进制文件各不相,编译器不同,不同的编译器可能会实现不同的优化策略,导致生成的二进制文件大小、执行速度或者其他性能指标有差异;编译时会为了安全、知识产权进行代码混淆,使用不同的代码混淆技术会导致生成的二进制文件结构和内容不同,例如,变量名混淆、控制流混淆、字符串加密等技术可以使得二进制完全不同;处理器架构也会影响最终的二进制文件,不同的处理器架构有不同的指令集和硬件特性,因此同一份源代码在不同架构的处理器上编译成的机器码会不同,例如,x86架构和ARM架构的处理器使用不同的指令集,因此生成的二进制文件在这两种架构上可能是不兼容的,需要分别编译,生成的文件也会天差地别。编译器、代码混淆技术和处理器架构等因素会对生成的二进制文件产生影响,使得即使是相同的源代码,在不同条件下编译得到的结果也是不同的。
因此,由上所述,在编译过程中会损失大量信息,并且由于编译过程的区别,导致编译的二进制文件各不相同,导致基于源码的组成成分分析方法完全不适用于二进制文件。
在二进制软件成分分析中一般分析是使用反汇编工具将二进制代码反汇编成汇编代码进行代码相似性检测。有时候会进一步使用IDA把汇编代码转换为伪代码形式。但是一般还是使用汇编代码进行分析,对汇编代码进行相似性检测,由于上述提到二进制文件不同,因此反汇编结果也不同,对于汇编代码相似性检测的难度类似于于克隆代码第四种类型的相似性检测程度。
四. 二进制组成成分分析方法概述
二进制组成成分分析,是在二进制文件中识别可能存在的代码复制、代码克隆、或者其他类型的代码重用情况,从而帮助发现潜在的安全风险或者违反知识产权的行为。二进制代码相似度(BCSD,Binary Code Similarity Detection),是二进制相似性分析的核心方法,用于检测两个或多个二进制代码文件之间的相似性,以此区分是否进行了组件复用。
目前针对于软件供应链的二进制相似性检测方法尚不成熟,但是针对于二进制相似性检测方法历史由来已久,接下来分别介绍基于SMT、基于CFG的同构程度、基于I/O相似性、基于深度学习的二进制相似性检测方法。
图二 二进制文件相似性通用模型架构
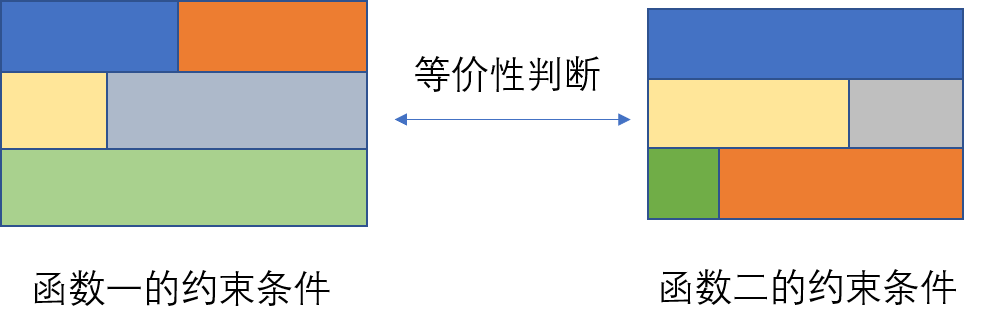
基于SMT的二进制相似性检测方法,将代码语义转换为约束条件,通过约束求解器来判断代码的相似性。SMT求解器是用于解决SMT问题的理论工具,它们能够自动分析给定的逻辑公式,并判断其是否可满足。在软件工程、硬件验证、形式化方法等领域,SMT求解器被广泛应用于模型检测、程序分析、自动推理等任务中。David Y等人[2]提出了一种基于SMT的统计方法,用于衡量二进制中两个过程之间的相似性。他们的相似性概念使得即使在使用不同编译器编译或被修改后,也能找到相似的代码。主要思想是利用组合相似性:将代码分解为较小的可比较片段,定义片段之间的语义相似性,并使用统计推理将片段相似性提升到过程之间的相似性。他们在一个名为Esh的工具中实现了这种方法,并应用于跨编译器和版本查找各种著名漏洞,包括Heartbleed、Shellshock和Venom等。他们展示了Esh产生了高准确性的结果,几乎没有误报的情况,足以说明该检测方法的准确度。
图三 基于SMT的越是条件等价判断方法
基于CFG的二进制相似性检测方法,Karamitas C等人实现了一种基于CFG的二进制相似性检测方法,用于研究两个程序之间的语法和语义差异。对于大型程序,二进制相似性检测可以通过函数匹配来实现,而函数匹配则被简化为比较程序的CFGs(控制流图)和/或CGs(调用图)之间的图同构问题。Karamitas C等人[3]提出了一组从二进制的CG和CFG中精心选择的特征,这些特征可以被BinDiff算法变体使用,首先通过扫描唯一的完美匹配来构建一组初始的精确匹配,从而最小化误报,其次通过例如最近邻策略来传播近似匹配信息。此外,Karamitas C等人还研究了将马尔可夫聚类技术应用于函数CFGs的好处。在Linux内核(Intel64)、OpenSSH服务器(Intel64)和Firefox的xul.dll(IA-32)的各个版本上进行了一系列实验来评估提出的函数特征,并将其原型系统与当前最先进的二进制相似性检测软件Diaphora(基于上文描述的SMT)进行了比较。
图四 基于控制流图的二进制相似度比对方法
基于I/O行为的二进制相似性检测方法,Jannik Pewny等人[4]提出了一种基于I/O行为的二进制漏洞搜索方法,旨在识别已知漏洞的漏洞签名,并利用这些签名在部署在不同CPU架构(例如x86与MIPS)上的二进制文件中查找漏洞。针对不同CPU架构的多样性,该方法面临着诸多挑战,例如CPU模型之间指令集体系结构的不可比性。为了解决这一问题,该方法首先将二进制代码转换为中间表示形式,生成带有输入和输出变量的赋值公式。然后,对基本块进行具体输入的采样,观察其I/O行为以把握其语义。最后,利用I/O行为找到行为与漏洞签名相似的代码部分,有效地揭示包含漏洞的代码部分。最终设计并实现了一个用于在可执行文件中跨架构查找漏洞的工具原型。该原型目前支持三种指令集架构(x86、ARM和MIPS),并可以在任何这些架构的漏洞二进制代码中发现漏洞。他们展示了无论底层软件指令集如何,都能够发现Heartbleed漏洞。
基于人工智能的二进制相似性检测方法。基于人工智能的检测方法主要包含两种解决方式,代码嵌入和图嵌入。代码嵌入(Code embeddings),许多研究人员尝试采用现有的自然语言处理(NLP)技术,通过将汇编代码视为文本来解决二进制函数相似性问题。这些解决方案处理标记流(例如指令、助记符、操作数、标准化指令)并输出每个代码块一个嵌入、每个指令一个嵌入或两者都输出,OrderMatters[5]、Trex[6]等模型均用的此类方法。图嵌入(Graph embeddings),其他研究建立在计算图嵌入的机器学习方法的基础上,这些非常适合捕获基于函数控制流图的特征,这些特征本质上是跨架构的。这些嵌入可以通过自定义算法或更复杂的机器学习技术生成,Xiaojun Xu、Zeping Yu, Rui Cao等人[7][8][9]的研究均是基于图嵌入方法。
图五 基于人工智能的二进制相似性识别框架
五. 总结
目前的二进制检测方法中,基于SMT的检测方法在实际操作中,约束求解中的理论证明仍然存在很多问题和挑战,同时该方法计算复杂度很高,代价很大。I/O操作和全局/堆内存访问中遇到的值在编译器很难优化这些行为,可以利用这个特征进行相似性比对任务,效果较好。基于人工智能的二进制相似性比对算法近几年突飞猛进,虽然分为代码嵌入和图嵌入两个流派,但是在检测粒度(基本块、指令)、跨架构、跨优化等级、识别函数语义都有了非常大的进步。
传统二进制相似性方法与软件供应链二进制组成成分中的相似性检测方法仍有区别。软件供应链中二进制软件成分分析的两大特点,一是组件库量级大,组件种类多、组件内版本数量大、差异小;二是组件在二进制相互包含、相互依赖,检测结果多样化。针对SMT的二进制相似性方法完全不适用于软件供应链领域,复杂度、代价很大,无法面对检测目标众多的软件供应链领域;基于I/O的行为的二进制相似性检测方法,无法区分一个组件中的多个版本,例如oauthlib组件修改了IPv6addres正则表达式中的10个字符升级成了新的版本;基于人工智能的检测方法,数据集过大,无法区分二进制内部组件之间的依赖关系。
目前,软件供应链中对软件组成成分的分析方法仍然局限于分析和识别二进制文件安装后释放的动态链接库等文件的名称和哈希值等简单特征。因此,在面对软件供应链领域时,我们仍然需要寻找一种新的二进制相似性分析方法。或许,大型语言模型将成为最终的解决方案。
参考文献
[1]. Libscout:Reliable Third-Party Library Detection in Android and its Security Applications CCS ’16, October 24–28, 2016, Vienna, Austria
[2]. David Y, Partush N, Yahav E. Statistical similarity of binaries[J]. Acm sigplan notices, 2016, 51(6): 266-280.
[3]. Karamitas C, Kehagias A. Efficient features for function matching between binary executables[C]//2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2018: 335-345.
[4]. Pewny J, Garmany B, Gawlik R, et al. Cross-architecture bug search in binary executables[C]//2015 IEEE Symposium on Security and Privacy. IEEE, 2015: 709-724.
[5]. Yu Z, Cao R, Tang Q, et al. Order matters: Semantic-aware neural networks for binary code similarity detection[C]//Proceedings of the AAAI conference on artificial intelligence. 2020, 34(01): 1145-1152.
[6]. Pei K, Xuan Z, Yang J, et al. Trex: Learning execution semantics from micro-traces for binary similarity[J]. arXiv preprint arXiv:2012.08680, 2020.
[7]. Xu X, Liu C, Feng Q, et al. Neural network-based graph embedding for cross-platform binary code similarity detection[C]//Proceedings of the 2017 ACM SIGSAC conference on computer and communications security. 2017: 363-376.
[8]. Yu Z, Zheng W, Wang J, et al. Codecmr: Cross-modal retrieval for function-level binary source code matching[J]. Advances in Neural Information Processing Systems, 2020, 33: 3872-3883.
[9]. Yu Z, Cao R, Tang Q, et al. Order matters: Semantic-aware neural networks for binary code similarity detection[C]//Proceedings of the AAAI conference on artificial intelligence. 2020, 34(01): 1145-1152.
内容编辑:创新研究院 王永吉
责任编辑:创新研究院 陈佛忠
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
关于我们
绿盟科技研究通讯由绿盟科技创新研究院负责运营,绿盟科技创新研究院是绿盟科技的前沿技术研究部门,包括星云实验室、天枢实验室和孵化中心。团队成员由来自清华、北大、哈工大、中科院、北邮等多所重点院校的博士和硕士组成。
绿盟科技创新研究院作为“中关村科技园区海淀园博士后工作站分站”的重要培养单位之一,与清华大学进行博士后联合培养,科研成果已涵盖各类国家课题项目、国家专利、国家标准、高水平学术论文、出版专业书籍等。
我们持续探索信息安全领域的前沿学术方向,从实践出发,结合公司资源和先进技术,实现概念级的原型系统,进而交付产品线孵化产品并创造巨大的经济价值。
长按上方二维码,即可关注我
如有侵权请联系:admin#unsafe.sh