2024-4-17 00:12:20 Author: securityboulevard.com(查看原文) 阅读量:18 收藏
Generative AI tools like ChatGPT have worked to solve the issue of real-time data since their inception. One attempt involved using plugins to access newer information that was not included in the training data.
Now, AI tools have access to retrieval-augmented generation (RAG), a technique that can gather facts from external sources in order to improve the accuracy of the model’s responses. This helps ensure large language models (LLMs) stay up-to-date, even without fully updating the training data.
Why do AI applications use RAG with their LLMs?
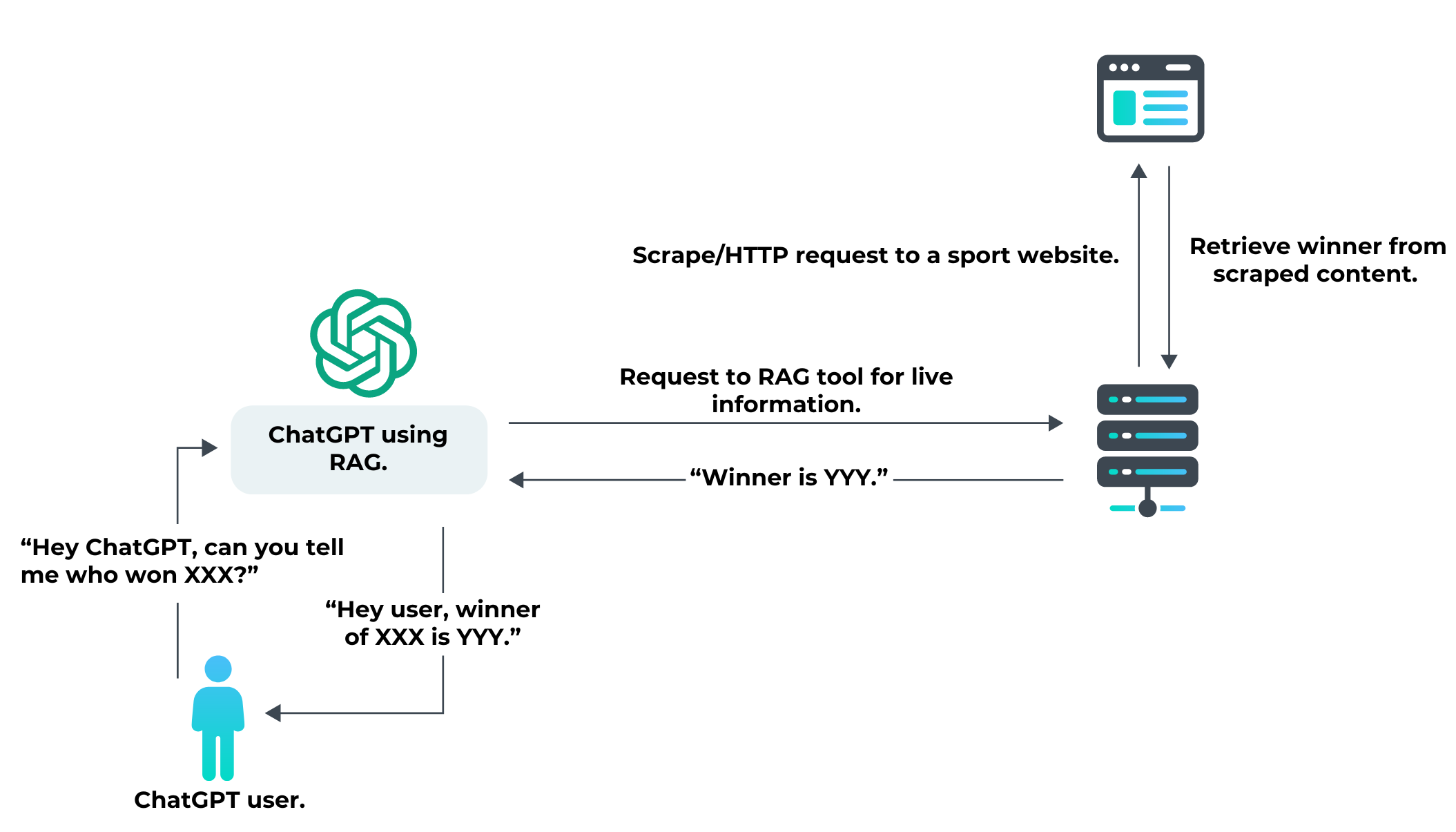
Not all information can be embedded and learned by LLMs during their training phase. For example, it’s not possible for an LLM to know the future price of a stock or the result of a baseball game. Thus, if you interact with a LLM through an application like ChatGPT and ask a question about a fact that occurred after the training and that can’t be predicted, the LLM may interact with a live data source—e.g. a website or an API—to answer with fresh information.

Thus, as a user interacting with the LLM, you get access to all the content the LLM learned from, but you also benefit from fresh content. LLMs can automatically interact with this external content, parse and ingest the data, and make it available to you through a more human-readable form.
Can my website be targeted by RAG?
Yes, any website or public API can be targeted by an LLM using RAG to gather information.
If your application is considered to be a good source of information on a certain topic (sports, finance, e-commerce, restaurants, news, etc.), then AI tools may start making RAG requests to obtain live information and leverage it in the output of their LLM.
What is the potential impact for my business if my website is targeted by LLM RAG?
As we discussed in a previous blog post about ChatGPT plugins, AI apps that leverage LLM may engender a potential decrease in human traffic to your website, as their users would interact with the LLM and not your website directly. Depending on your business model, this could result in diminished sales or fewer ads seen and clicked, which could hamper your revenue.
Your content may also be mixed with invalid content that has been hallucinated by the LLM, which could hamper your reputation.
However, depending on your content, and whether or not the AI application provides clear citations and links to your content, this could be a potential opportunity to allow users to interact with your content through a different channel.
How can I block LLM RAG requests on my websites and APIs?
In the case of AI applications that declare their presence in their user-agent, you can block requests from those user-agents as listed in the substrings. For example, in the case of ChatGPT plugins performing RAG, you could block the user-agents that contain the substring ChatGPT linked to user-agents that look like this: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot.
However, not all AI applications using RAG declare their identity in their user-agent. In this situation, you will need to apply advanced bot detection techniques to identify that the request is coming from a bot. Moreover, since RAG may require a single request to obtain the information, it’s important to use a bot protection service that can—without impacting UX—detect and protect web traffic in real time, and detect bots from the first request.
Conclusion
DataDome is a robust bot and online fraud detection solution that works at the edge, reviewing requests in real time to identify malicious traffic from the first request. Our industry-leading 0.01% false positive rate and invisible challenges safeguard the user experience while keeping bad bots out.
Try DataDome for free or book a demo today to see how we could protect your business from unauthorized bot traffic.
如有侵权请联系:admin#unsafe.sh