最近因为一些事情研究复现了几个Linux kernel的洞,感觉自己对内核的对象分配这块的了解并不深入,于是打算出一个系列对于内核对象分配释放机制和调试方法等进行研究,基本属于跟着大佬们学习,多多指教。
前置知识
自旋锁- spin locks
static DEFINE_SPINLOCK(xxx_lock); unsigned long flags;
spin_lock_irqsave(&xxx_lock, flags);
... critical section here ..
spin_unlock_irqrestore(&xxx_lock, flags);
在内核中,上面的代码片段使用了最基本的自旋锁,它会禁用本地中断,而且它是全局锁,因此会保证被锁保护的区域只存在一个线程。自旋锁在无论在单核CPU或者多核CPU下都可以很好的工作。除了上述类型的使用方式,内核中还存在对于共享内存等的读写自旋锁,它允许多个内存读操作同时进行,但是如果是写操作那么就必须进行内存锁定。
rwlock_t xxx_lock = __RW_LOCK_UNLOCKED(xxx_lock); unsigned long flags;
read_lock_irqsave(&xxx_lock, flags);
.. critical section that only reads the info ...
read_unlock_irqrestore(&xxx_lock, flags);
write_lock_irqsave(&xxx_lock, flags);
.. read and write exclusive access to the info ...
write_unlock_irqrestore(&xxx_lock, flags);
对于一些复杂数据结构链表的访问就可能用到上述操作。
虽然自旋锁非常安全,但是因为它需要关闭中断操作因此它的性能开销是非常巨大的,不过也存在更轻量化版本的spin lock:
spin_lock(&lock);
...
spin_unlock(&lock);这种类型的spin lock同样保证对于保护区域的单独访问,不过这种一般用于没用中断操作调用的情况,比如被保护区域只被进程上下文操作,一旦出现下面的情况:
spin_lock(&lock);
...
<- interrupt comes in:
spin_lock(&lock);就会造成死锁,这种情况下一个中断处理程序想要访问一个被保护的数据区域就会造成死锁。如果是多个CPU,中断发生在另一个CPU,这样是可以的。这种情况不能发生在相同的CPU上,因为数据已经被锁定。CPU运行的程序为中断处理程序,因此数据无法被访问,锁也无法被释放。
内核堆分配策略
Linux 提供了多种用于内存分配的 API。你可以使用 kmalloc 或 kmem_cache_alloc 等系列函数分配小块内存,使用 vmalloc 及其衍生函数分配大的虚拟连续内存区域,或者直接从页面分配器请求页面使用 alloc_pages。还可以使用更专门的分配器,例如 cma_alloc 或 zs_malloc。同时Linux kernel提供GFP标志符来控制内核堆分配行为,如下:
kzalloc(<size>, GFP_KERNEL);下面简单列举内核中GFP标识的使用,这有助于理解Linux kenrel堆的使用策略。
• GFP_KERNEL,这个是最常用的,许多内核数据和内核相关结构体所需的内存都需要用这个标识。但是该标识也依赖GFP_RECLAIM标识,因此在内存压力下可能触发内存回收,所以调用上下文必须允许休眠,这样内核在面临内存压力的时候可以进行内存回收,让相关调用进入休眠状态,从而更有效的控制内存使用。
• GFP_NOWAIT,该标识需要在内核的原子性上下文中使用,该标识可以防止内存回收以及I/O和文件系统的影响,但是在内存压力下可能会分配失败。此时可以使用GFP_NOWARN来进行合理的错误处理。下面是一个例子:
#include <linux/slab.h>void* my_custom_allocation(size_t size) {
void* ptr = kmalloc(size, GFP_KERNEL | GFP_NOWARN);
if (!ptr)
pr_info("Memory allocation failed, but no warning is printed.\n");
else
pr_info("Memory allocation succeeded.\n");
return ptr;
}
void my_custom_free(void* ptr) {
kfree(ptr);
}
// 示例用法
int my_module_init(void) {
void* allocated_memory = my_custom_allocation(1024);
// 使用分配的内存...
my_custom_free(allocated_memory);
return 0;
}
• 当你觉得内核预留内存充足的时候可以使用
GFP_ATOMIC进行,这种操作是非阻塞的,一旦无法分配则直接返回失败,它和GFP_NOWAIT的区别在于GFP_NOWAIT更适用于一般性的可睡眠上下文,但在分配失败时不希望等待的情况。这可以用于避免不必要的延迟。• GFP_USER,来自用户空间的分配需求则需要该标识位。
这些是开发者在开发内核模块等时需要注意的标识,同样对我们理解内核代码进行漏洞挖掘也有一定的帮助,在整体范围上我们还需要知道,对于Linux kernel 内存分配来讲主要存在三个不同的分配器,当然也有其它分配器,不过这三个较为主流:
1. Page allocator
2. Vmalloc allocator
3. Slab allocator
其中page allocator很好理解,用来进行物理页的分配,大小一般为4kb,vmalloc allocator则主要是对虚拟内存连续块进行分配管理,但是因为在内核里面很多分配请求其实所需的内存大小都不超过4kb,因此简单的使用page allocator会导致资源浪费,因此就有了slab allocator,它通过对不同类型的内核对象进行缓存来增加空间利用率,但是针对不同的环境和系统也存在不同的slab实现,因此Linux kernel一般存在三种不同的slab,分别命名为SLAB,SLUB,SLOB,其中SLUB是最广泛使用的版本。
SLUB分配器
SLUB分配器作为对象分配器,其分配大小跟内核对象大小有直接的关联,下面是它的简单布局:
其中Object content是内核对象,其它部分根据是否开启内核的各种配置来决定其是否出现,比如Kasan区域和内核Kasan配置是否开启紧密相关。SLUB存在很多slab cache,在内核里面一般由kmem_cache对象来表示,kmem_cache对象里面包含了用来管理slab cache的所有信息,其中有一个成员为cpu_slab,该成员作为一个指针指向kmem_cache_cpu结构体,kmem_cache_cpu结构体中的内容为和CPU相关的slab cache信息,对于每一个slab都有一个slab object表示,但是如果内核版本低于5.17的话,如果一个页处于一个slab中,在页对象中存在一个匿名的union来保存slab的信息,kmem_cache中的kmem_cache_node成员则表示可以用于slab分配的内存节点。同时对于free object的管理,内核和用户态glibc也存在类似的地方,在对象中存在free pointer (FP),该指针一般位于内核对象的起始位置,不过具体位置根据内核版本和不同对象之间存在差别。不过从上图可以看出有些时候内核对象只是分配出来的堆块的一部分,简单解释一下不同区域的作用。
• RED zone left padding:当内核
slub_debug开启的时候(slub_debug = Z) RED zone存在于内核对象的前面,此时kmem_cache→red_left_pad成员表示RED zone left padding的大小,因此此时实际上的内核对象内容起始地址为内核对象地址加上RED zone padding的大小作为偏移,其中free list中的指针也不再指向内核对象的起始位置,而是指向内核对象起始地址加上RED zone的大小作为偏移的新地址,也就是实际上真实内存对象地址开始的地址。• Object content:这个就是真实的内核对象了,无论何时肯定存在,大小由
kmem_cache→object_size成员指定。• READ zone:当内核slub_debug配置(slub_debug = Z)开启的时候存在该区域,不过在
kmem_cache中没有确定的成员来指定该区域的大小,一般来说REAQD zone大小为指针大小,因为一般内核对象的大小也就是kmem_cache→object_size是指针大小对齐的,那么假如kmem_cache→ object_size的大小没有指针对齐的话,内核对象的结尾地址和Metadata起始地址之间的内存空间就是RED zone。• Metadata:Metadata区域跟内核配置也有很大的关系,如上图所示的
Free Pointer,Slub allocation info,KASan allocation info都是和对应的内核debug配置相关的。• Padding:这个很好理解,就是为了地址对齐的。
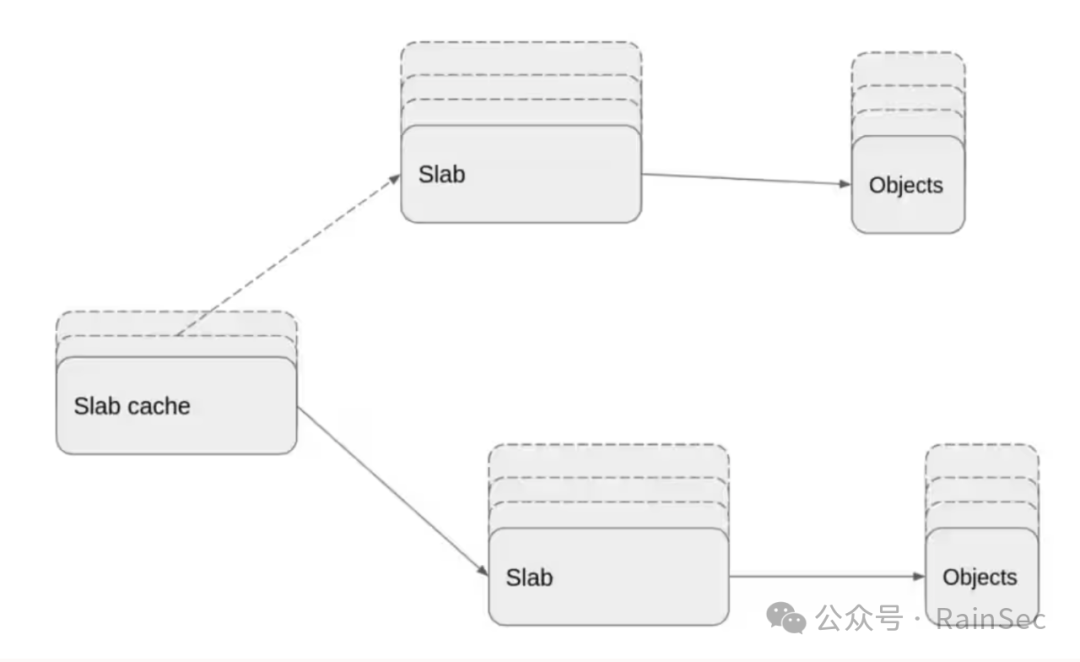
接下来聊一聊slab cache和内核对象之间的关系。slab cache中包含一个或多个slab,同时每个slab都包含一个或者多个物理页,这些页中包含指定大小的内核对象。内核对象和slab都是以链表的形式组织起来。
同时对于slab cache而言,它存在一个per-cpu active slab,一个per-cpu partial slab list和一个per-node partial slab list,在per-cpu partial slab中的slab通过slab.next成员进行连接,在per-node partial slab lists中的slab则通过slab.slab_list成员进行连接,这一块最好还是通过源码了解一下,不然可能有点乱。至于per-cpu active slab很容易理解就是现在被用于分配内核对象的slab,当active slab的内核对象被分配完成的时候另一个slab开始分配内核对象,同时该slab转变为active slab,同时在每一个slab cache中都包含一个per-cpu freelist,freelist中包含很多active slab中的内核对象,同时在slab结构体中也存在一个freelist,因此active slab中的内核对象可能随时处于两个列表中的一个,两个列表的区别在于per-cpu freelist是一个无锁列表,从无锁列表中分配内核对象,或者释放内核对象到无锁列表都不需要进行任何的中断和抢占操作,但是不是所有的slab和内核对象操作都可以通过无锁方式来实现,比如操作slab中的freelist,或者操作slabs list。slab的freelist可以参考下图:
关于SLUB allocator中的锁一般有以下几种:
• slab_mutex:这是一个全局的mutex,主要用来保护slab cache中的list,并且在同步slab cache元数据的改变和内存热插拔的call back。
• kmem_cache_node->list_lock:这里使用spin lock来保护在各自内存节点上的partial slab和full slab,spin lock也保护partial slab的计数器counter,因此该锁是针对节点的,它存在较高的性能消耗。
• kmem_cache_cpu->lock:这里使用spin lock来保护per-cpu kmem_cache_cpu不出现在相同CPU上被中断和抢占冲突的情况。
• slab_lock(slab):这个其实是对page lock的封装,它使用spin lock来保护freelist和不被使用的内核对象以及slab的一些属性。这是必须的假如系统不能够使用类似cmpxchg的指令来操作相关属性的时候。
• object_map_lock:这是一个全局spin lock,单纯是为了调试。
通过上面的信息我们可以意识到,一个slab存在三种不同的状态:
1. empty
2. full
3. partial
对于empty slab来说,其可以被回收,底层的page则会被返回给page allocator,对于任何partial list上面的slab要么是部分空的要么是全空的,full slab不需要特别关注,因为假如full slab上面的一个内核对象被释放了,那么可以通过该内核对象找到该slab并将该slab放在合适的slab链表上。
同时slab依赖的page数量也是不固定的,可以是一个page也可以是多个page,page的数量取决于kmem_cache.oo成员(struct kmem_cache_order_objects oo;)该成员表示一个slab存在的内核对象数量。对于包含多个page的slab,一个融合页(compound page,which group of 2 or more physically contiguous pages)会被分配给它,在5.17之前版本的内核page结构体中存在slab_cache和freelist成员,融合页被slab_cache管理,并且在融合页中只有head page的freelist成员是有用的,对于尾部的页来说slab_cache和freelist成员不被用来识别slab_cache或者slab中的第一个free object,从5.17内核版本开始,slab_cache和freelist或者其它slab相关的成员被移动到单独的slab结构体中。不过无论slab存在于slab内核对象还是page内存对象,其freelist成员都指向该slab上第一个free的内核对象。
如何分配一个内核对象
对此基本上对slab有了一个大概的了解,那么一个内核对象到底如何从一个slab中被分配出来呢?首先,内核对象一定是从active slab上分配的,并且该过程不需要使用锁或者关闭中断,在freelist(kmem_cache.cpu_slab->freelist)上面的第一个内核对象会被分配出去,然后跟它在链表上处于相邻位置的内核对象会成为该链表的第一个内核对象,假如无锁链表(kmem_cache.cpu_slab->freelist)中的内核对象被分配完,那么该链表会变成一个空链表NULL,此时如果当前CPU架构不支持cmpxchg指令或者此时slub_debug功能开启,这种无锁的快速分配方式会被禁用,此时存在一些其它的性能较差的分配方式但是不同的方式存在不同的性能消耗,下面对这些分配方式进行介绍。
假如per-cpu freelist,也就是无锁freelist不包含free的内核对象,但是active slab中的freelist存在free的内核对象,那么就会从slab的freelist上面分配一个内核对象给请求者,同时该freelist的其它free内核对象会被传递给无锁freelist,然后slab的freelist会被置NULL,这个传递的过程会关闭中断并请求kmem_cache_cpu.lock锁,因此它有一定的性能开销,但是这已经算是除了从无锁freelist上直接分配的方式外最快的方式了。不过这种情况下必须关闭内核的抢占配置CONFIG_PREEMPT_RT,因为kmem_cache_cpu.lock是一个spin lock并且保留启用抢占,显示的禁用抢占可以提升稳定性。在前文中提到per-cpu freelist和active slab freelist可以指向同一个free的内核对象,因为当一个slab转变为active slab的时候它的slab freelist中的内核对象会被转发到per-cpu freelist,然后slab freelist就会变为NULL,此时内核对象的分配会从per-cpu freelist上进行,最终这些内核对象还是会被free掉,假如这些内核对象在free的时候是被分配时使用的CPU free掉,那么就会进入per-cpu freelist,那么如果是被其它CPU free掉,那么这些内核对象就会进入到slab freelist,因此有时会出现slab freelist存在内核对象但是per-cpu freelist为空的情况。
还有一种情况是active slab中不存在可用的内核对象,但是per-cpu partial slab list存在一些slab,它们有可用的内核对象,这种情况下,per-cpu partial slab list中的第一个slab会成为active slab,它的freelist被转移到per-cpu freelist,然后给需求方提供内核对象,这个过程依然需要关闭中断/抢占并请求kmem_cache_cpu.lock,同时相比于上一种方式还存在额外的性能开销:将per-cpu partial slab list的第二个slab(假如有的话)放在链表的头部,以及对active slab的切换处理。
那么假如per-cpu slab无论是active还是partial都不存在可用的内核对象,那么就会尝试从per-node partial slab list中分配slab,首先我们要了解slab是如何添加到per-node partial slab list链表中的。当一个full slab变成empty slab或者partial slab的时候,该slab就会被放到per-cpu partial slab list,那么假如per-cpu partial slab list功能不被支持或者它已经存放了最大数量的内核对象,那么该slab 就会被放到per-node partial slab list。因此在per-cpu slab无论是active还是partial都不存在可用的内核对象的时候,slub分配器会从local node partial slab list获取slab,但是如果如果在该节点上无法找到合适的slab,之后就会从per-node partial slab list上面的其它节点中获取slab,对一个node partial slab list进行遍历需要请求kmem_cache_node.list_lock,并且因为这是一个central lock,因此这种分配方式存在比上一种更高的性能消耗。在遍历中找到合适的slab并将其freelist的第一个内核对象分配出去,紧接着slab中剩下的内核对象会成为per-cpu active slab的一部分。在开启per-cpu partial slab list的情况下,slub分配器会继续操作,将per-node partial slab list中的slab移动到per-cpu partial slab list直到per-node partial slab list为空或者per-cpu partial slab list中的slab数量已经达到最大值,该最大值依赖于内核对象的大小,假如内核对象大小>=PAGE_SIZE,这个数量为6,对于内核对象大小小于256,这个数量为120。
假如出现所有的slab都变成full slab,对于新的slab的分配则需要使用page allocator,这个新分配的slab会成为CPU当前的active slab,这种方式是性能消耗最严重的因为它需要从buddy allocator中获取新的物理页。
如何释放一个内核对象
通过对内核对象分配的了解可以知道,要释放的内核对象的主要来源为:
• per-cpu active slab
• per-cpu partial slab list
• per-node partial slab list
• Full slab
在释放内核对象的过程中,内核触发的操作也和内核的配置紧密相关,假如内核开启了GENERIC KASAN,那么被释放的内核对象并不会转变为可用的状态而是放在了一个隔离列表里面,这样的话,其实slab的状态并没有因为释放内核对象而发生明显的改变,比如,一个full slab在释放一个内核对象之后并不会转变成一个partial slab,同时假如只存在一个内核对象的partial slab在释放的时候该slab也不会转变为empty slab,需要做的只是更新内核对象对应的shadow bytes,并将其放入隔离列表里面,只有当隔离列表里面的内核对象被处理的时候才会考虑slab状态改变的影响。
那么假如不开启GENERIC KASAN内核配置的话,一个内核对象被释放的时候会被插入到freelist的头部,对于per-cpu active slab而言存在两个freelist,一个是kmem_cache_cpu->freelist无锁freelist,一个是slab结构体中的常规freelist,因此假如被释放的内核对象是属于active slab,并且释放该内核对象的CPU也属于该active slab,那么该内核对象就会被放入无锁freelist,那么假如被释放的内核对象属于active slab,但是释放该内核对象的CPU不属于该active slab,那么该内核对象就会被放入slab对应的常规freelist,这些操作在CPU支持cmpxchng指令并且没有开启slab debug的时候都可以无锁进行。假如被释放的内核对象属于full slab,那么释放内核对象之后该full slab也会转变为partial slab,该slab也会被放入到per-cpu partial slab list或者per-node partial slab list,这个新的partial slab被放入per-cpu partial slab list,而且不需要进行其它操作,那么整个操作只需要触发kmem_cache_cpu.lock,但是如果这个新的partial slab在放入per-cpu partial slab list的过程中发现per-cpu partial slab list已经满了,并且这些slab都没有被锁定等操作,那么这些slab会被移动到per-node partial slab list,因为移动到per-node partial slab list的过程中需要请求kmem_cache_node.list_lock锁,这会增加性能开销。
假如被释放的内核对象不属于active slab而是partial slab,那么假如该slab在释放内核对象之后仍然属于partial slab,那么不会出现额外操作,slab依然保存在partial slab list上,这种情况在per-cpu partial slab list和per-node partial slab list中都适用,但是如果在释放内核对象之后该slab转变为empty slab,那么接下来的操作就取决于slab cache’s min_partial,假如partial slab list中的slab数量在这个限制之内,那么该empty slab依然会存在于这个链表上,但是如果超出该限制,那么该empty slab会被释放并从partial slab list中释放,这个处理方式同时适用于per-cpu partial slab list和per-node partial slab list。
上图对应了内核对象释放过程中的几个过程,其中红色代表对于per-node partial slab list的操作,相关操作需要请求kmem_cache_node.list_lock,橙色代表对于per-cpu partial slab list的操作,相关操作需要请求kmem_cache_cpu.lock,红色和橙色都代表的速度较慢,性能消耗较大的内核对象释放方式,其中kmem_cache_node.list_lock的性能损耗要高于kmem_cache_cpu.lock。同时,释放一个内核对象和释放多个内核对象在插入freelist上存在区别,假如释放一个内核对象,那么只需要将该内核对象放到对应的freelist的头部,如果是释放多个内核对象,一个detached freelist会被创建并将其组合到对应freelist的头部。
本文简单介绍了内核对象的申请和释放原理,后续文章将结合实际代码进行调试分析。
参考链接
https://blogs.oracle.com/linux/post/linux-slub-allocator-internals-and-debugging-1
https://docs.kernel.org/locking/spinlocks.html
如有侵权请联系:admin#unsafe.sh