2024-4-21 08:0:0 Author: arthurchiao.github.io(查看原文) 阅读量:9 收藏
Published at 2024-04-21 | Last Update 2024-04-21
本文翻译自 2024 年 Meta/Facebook 的一篇文章: Building Meta’s GenAI Infrastructure。
- 两个 GPU 集群,每个集群
2.4w H100,分别用RoCE/InfiniBand网络; - LLaMA3 就是在这两个集群上训练出来的;
- 预计到 2024 年底,Meta AI 基础设施建设将拥有
35w 张 H100GPU,总算力相当于约60w 张 H100。

由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
作为对未来人工智能的重要投资,Meta 打造了两个大规模 AI 集群,每个集群由 2.4w 张 GPU 组成,
本文分享其计算、网络、存储等设计细节。
Meta 很早就开始构建 AI 基础设施,但第一次对外分享是在 2022 年,介绍了我们的
Research SuperCluster
(RSC),它由 1.6w 个 A100 GPU 组成。
RSC 支撑了 Meta 第一代先进 AI 模型的开发,在训练 Llama/llama2、
计算机视觉、NLP、语音识别、图像生成甚至编码等 AI 工作中发挥了重要作用。
精确数字是每个集群
24,576张 H100 GPU。
我们的新一代 AI 集群充分吸收了 RSC 的成功和经验教训,这包括,
- 新集群致力于构建端到端的 AI 系统,特别强调研究人员和开发人员的用户体验和工作效率;
- 新集群能支持更大、更复杂的模型,为 GenAI 产品开发和 AI 研究的进步铺平了道路。
Meta 每天需要执行数以万亿计的 AI 任务,这就需要一个高度先进和灵活的基础设施。 我们自研了大部分硬件、软件和网络 fabric,使我们能进行端到端优化,确保数据中心的高效运行。
左侧:计算机柜,包括 GPU 服务器机框,置顶交换机,fabric 交换机等等;右侧:存储机柜。
2.1 计算:Grand Teton GPU 主机
两个新集群都使用了 Grand Teton, 这是 Meta 开发的开放 GPU 硬件平台,我们已经将其贡献给了开放计算项目(OCP)。
从 2015 年的 Big Sur 平台开始, 我们就一直在开放设计我们的 GPU 硬件平台。
Grand Teton 实物图如下,

- 将 CPU 机头、GPU、交换机同步系统、电源等等集成到一个机框中,以获得更好的整体性能;
- 提供了快速可扩展性和灵活性,设计简化,可以快速部署到数据中心,并易于维护和扩展。
结合 Open Rack 电源和机架架构 等其他内部创新,我们能为 Meta 当前和未来应用程序快速量身定制新集群。
2.2 网络
两个集群使用了不同的网络方案,但都是 400Gbps 接入。
2.2.1 集群一:400Gbps RoCE + 自研交换机
基于 RoCE 网络,使用的交换机包括
- 自研置顶交换机(
TOR)Wedge400 / Arista 7800 , -
自研模块化交换机 Minipack2。
- Minipack/Minipack2 在组网中能承担多种角色,例如作为 Spine 交换机,
- 第一代 Minipack:(译) 重新设计 Facebook 的数据中心网络(2019)。
- 更早一点的数据中心网络:(译) 数据中心 Fabric:Facebook 的下一代数据中心网络(2014)。
2.2.2 集群二:400Gbps InfiniBand
使用 NVIDIA Quantum2 InfiniBand fabric。
2.2.3 小结
两个方案作对比,使我们能够评估 RoCE/IB 在大规模训练中的适用性和可扩展性,
为设计和构建更大规模的集群提供了宝贵经验。
目前这两个不同组网类型的集群都能够运行大型生成式 AI 任务
(例如在 RoCE 集群上训练 Llama 3),
而没有遇到网络瓶颈。
2.3 存储
存储在 AI 训练中扮演着重要角色,然而相关的讨论确非常少。
最近的发展趋势可以看出,GenAI 任务越来越多模态,需要处理大量图像、视频和文本,因此对高性能存储的需求越来越强烈。 理想的存储方案除了提供良好的性能,还要做到低能耗。
2.3.1 数据和 checkpoints 存储:FUSE + Tectonic
我们 AI 集群的数据和 checkpoint 的存储方案:
- 上层是一个自研的 Linux 用户空间文件系统(FUSE)
- 底层是 Meta 的名为 Tectonic 的分布式存储解决方案,它针对闪存(Flash media)进行了优化。
这个解决方案使得
- 数千个 GPU 能同步保存和加载 checkpoints(对任何存储解决方案来说都是一个挑战),
- 同时还提供了
EB级存储系统所需的灵活性和高吞吐。
2.3.2 交互式调试:Parallel NFS
我们还与 Hammerspace 合作开发了一个并行网络文件系统(NFS), 它使工程师能够使用数千个 GPU 进行交互式调试, 因为代码改动能立即同步到环境中的所有节点。
Tectonic 分布式存储加上 Hammerspace,既能满足快速迭代,又不会限制规模。
2.3.3 大容量 SSD + 定制每个机柜的服务器数量
无论是 Tectonic 还是 Hammerspace 方案,都基于
YV3 Sierra Point server platform,
使用了我们在市场上能够买到的最新高容量 E1.S SSD。
除此之外,每个机架塞的服务器数量也进行了定制,以在服务器吞吐量、机架数量和能效之间取得一个平衡。
OCP 服务器就像乐高积木,使我们的存储层能够灵活扩展到未来更大 AI 集群的需求,而且不影响日常基础设施的使用和维护操作。
3.1 原则:性能和易用性缺一不可
我们构建大规模 AI 集群的一个原则是,同时最大化性能和易用性,而不是为了一个而牺牲另一个。 这是训练最佳 AI 模型的重要基础。
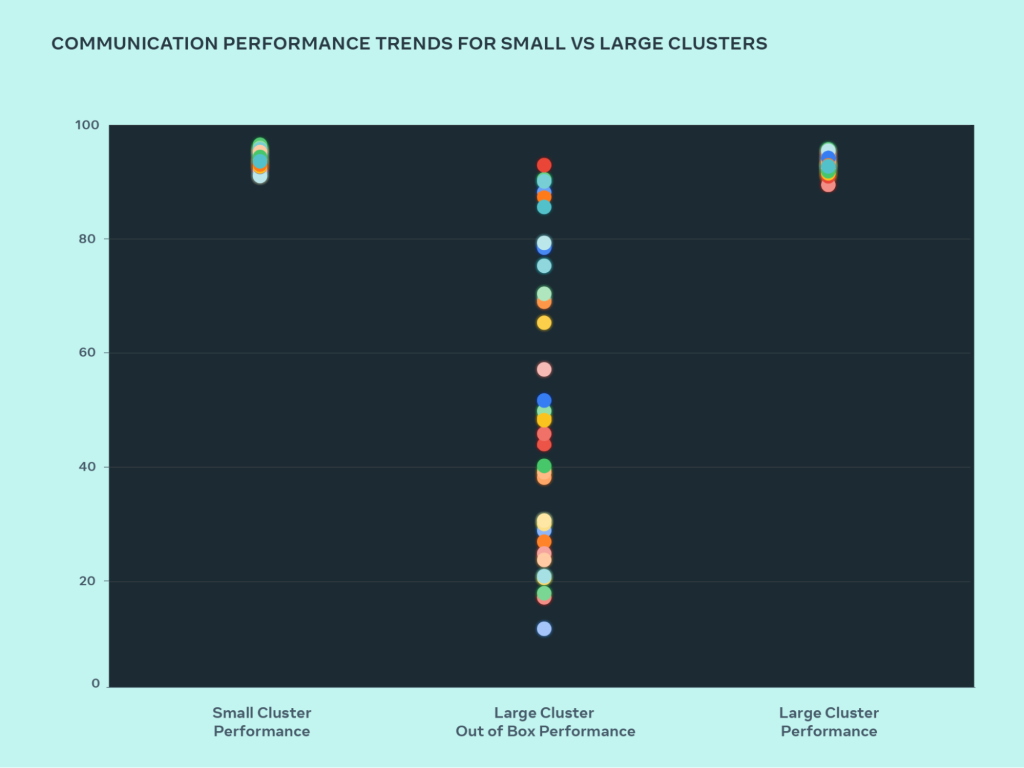
测试系统设计的扩展性的最佳方法就是先构建出一个系统,然后不断优化它,并进行实际测试(模拟器有帮助,但作用有限)。 通过这个过程,我们比较了小集群和大集群的性能,定位瓶颈在哪里。 下图显示了当大量 GPU 相互通信时(at message sizes where roofline performance is expected)的 AllGather 性能(带宽归一化到 0-100),

small cluster performance (overall communication bandwidth and utilization) reaches 90%+ out of the box, but an unoptimized large cluster performance has very poor utilization, ranging from 10% to 90%. After we optimize the full system (software, network, etc.), we see large cluster performance return to the ideal 90%+ range.
3.2 大集群优化
与优化过的小型集群性能相比,我们的大集群一开始性能是比较差的。 为了解决这个问题,我们做了如下优化:
-
改进
job scheduler,使其具备网络拓扑感知能力,这带来的好处:- 延迟降低
- 转发到更上层网络(交换机)的流量减少。
-
结合 NVIDIA
NCCL,优化了网络路由策略,以实现最优的网络利用率。
以上两项优化使大集群的性能已经接近小集群。
除此之外,我们还
-
与训练框架和模型团队密切合作,不断改进基础设施。例如,
- 支持 NVIDIA H100 GPU 的新数据类型 FP8,这对训练性能大有帮助,
- 并行技术优化,
- 存储优化,
-
意识到可调试性(debuggability)是大规模训练的主要挑战之一。 在大规模情况下,定位到哪个 GPU 卡顿导致的整个训练作业变慢是非常困难的。 为此,我们正在构建 desync debug 或分布式 flight recorder 之类的工具,跟踪分布式训练的过程,以更快识别问题。
-
继续开发基础 AI 框架
PyTorch,使其能支持数万甚至数十万 GPU 进行训练。 例如,我们已经定位到进程组初始化方面的几个瓶颈,将启动时间从有时的几小时减少到几分钟。
Meta 保持对 AI 软件和硬件开放创新的承诺,我们始终相信开源硬件和软件是帮助行业解决大规模问题的有用工具。 我们将
- 继续作为 OCP 的创始成员支持开放硬件创新,例如已经将 Grand Teton 和 Open Rack 等设计贡献给 OCP 社区。
- 作为
PyTorch的最大和主要贡献者,继续推动这一 AI 软件框架的开发和普及。 -
继续致力于 AI 研究社区的开放创新。
- 我们发起了开放创新 AI 研究社区, 旨在深化我们对如何负责任地开发和共享 AI 技术(尤其是大模型)的理解。
- 我们还推出了 AI Alliance,这是一个由 AI 行业领先组织组成的小组,专注于在开放社区内加速负责任的 AI 创新。
我们的 AI 工作建立在开放科学和协力合作的哲学之上。
本文介绍的两个 AI 训练集群是我们未来 AI 路线图的一部分。
预计到 2024 年底,Meta AI 基础设施建设将拥有 35w 张 H100 GPU,总算力相当于约 60w 张 H100。
当前有效的方法可能不足以满足明天的需求,这也是为什么我们一直在各个方面不断评估和改进我们的基础设施, 包括物理硬件层、虚拟层、软件层以及更上面的业务层等等。 我们的目标是创建灵活可靠的系统,以支持日新月异的新模型和研究。
![]()
![]()
如有侵权请联系:admin#unsafe.sh