Meta 前两天发布了开源领域最新最强的 Llama 3 大语言模型。
此次公开的 Llama 3 包括了 8B 和 70B 两种参数规模,共有 8B, 8B-instruct, 70B, 70B-instruct 四个版本。其中 8B 和 70B 是预训练模型,而带 instruct 后缀的模型是经过指令微调,可以进行对话任务。另外还有一个 400B 版本的 Llama 3 还在训练中,尚未公开。
Llama 3 词汇表提升到 128K,上下文长度提升为 8K,上下文长度并不算大。
下面我们将介绍 MacOS 环境下,本地如何快速部署并体验 Llama 3。
快速体验或部署 Llama 3
Llama 3 发布后,NVIDIA 官网第一时间上线了 Llama3,可在线体验,不排队的情况下速度还是挺快的。
https://build.nvidia.com/meta/llama3-70b
HuggingFace 目前也上线了 Llama3-70B 版本
https://huggingface.co/chat/models/meta-llama/Meta-Llama-3-70B-Instruct
除了在线体验之外,我们可以使用 Ollama 将模型部署到本地,安装 Ollama 之后,执行以下命令即可运行 Llama 3:
ollama run llama3
默认运行的是 8B 的 4bit 量化版,大小为 4.7 GB。
结合 Open-WebUI 可以在 Web 页面中体验,使用 docker 快速启动 Open-WebUI:
docker run -d -p 3000:8080--add-host=host.docker.internal:host-gateway-v open-webui:/app/backend/data--name open-webui ghcr.io/open-webui/open-webui:main
ChatGPT-Next-Web 目前也支持 ollama 本地API,使用 docker 快速启动:
docker run -d -p 3001:3000 yidadaa/chatgpt-next-web访问 http://127.0.0.1:3001 ,然后在设置中勾选自定义接口,接口地址填 ollama 的 API 地址 http://127.0.0.1:11434 ,自定义模型名填写本地模型名,API Key 留空。注意不要配置登录口令,否则 Authorization Header 会导致 CORS 异常,无法使用。
手工下载和部署模型
当然,我们也可以从官网或者HuggingFace上下载原始的模型文件,手工进行部署运行。
下载模型
从 HuggingFace 下载
HuggingFace 申请页面 https://huggingface.co/meta-llama/Meta-Llama-3-8B/tree/main
从 Meta 官网下载
在官网提交申请下载模型 https://llama.meta.com/llama-downloads/ ,随后收到包含下载地址的邮件。
接下来拉取 Github 上 llama3 的项目代码:
# 下载 Github 仓库git clone https://github.com/meta-llama/llama3# 设置代理,需要用香港或者海外代理export http_proxy=127.0.0.1:8080export https_proxy=$http_proxy# 下载模型sh download.sh
随后根据命令行提示输入相应的参数,然后开始下载
Enter the URL from email:Enter the list of models to download without spaces (8B,8B-instruct,70B,70B-instruct), or press Enter for all:Downloading 8b_pre_trained正在连接 127.0.0.1:8080... 已连接。已发出 Proxy 请求,正在等待回应... 206 Partial Content长度:16060617592 (15G),剩余 16003715825 (15G) [binary/octet-stream]正在保存至: “./Meta-Llama-3-8B/consolidated.00.pth”
下载完成后,会得到如下文件:checklist.chk、consolidated.00.pth、params.json、tokenizer.model
使用 llama.cpp 适配 Apple 芯片
Macbook 上没有 NVIDIA 显卡,想要把模型文件跑起来,需要使用 llama.cpp 项目进行一些适配和转换工作。主要分为以下几个步骤:
编译安装 llama.cpp
转换模型
量化模型(可选)
运行模型
首先我们先编译安装 llama.cpp,从项目代码仓库中下载源码并编译:
https://github.com/ggerganov/llama.cpp
git clone https://github.com/ggerganov/llama.cppcd llama.cppmake
安装依赖并使用 convert.py 脚本进行模型转换,从 PTH 转为 GGUF 格式
# 安装相关依赖python -m pip install -r ./requirements/requirements-convert.txt# 进行转换,注意此处需要特别指定 bpe 类型python convert.py --vocab-type bpe ~/llama3/Meta-Llama-3-8B-Instruct
运行后发现,从 Meta 官网链接下载的版本无法成功转换:
FileNotFoundError: Could not find a tokenizermatching any of ['bpe']
翻了好几个 llama.cpp 项目 issue,很多人遇到同样的问题,暂时没看到公开的解决方案。于是自行分析了一下报错代码,是在 convert.py 的 VocabFactory 类中触发的异常:
知道原因就好解决了,可以从 HF 上下载对应版本的 tokenizer.json,放到模型同目录下,即可成功转换。
https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct/raw/main/tokenizer.json
Llama 3 8B-Instruct 转换后模型文件为 ggml-model-f32.gguf,大小为 32GB。
然后可以选择使用 llama.cpp 的 quantize 进行模型量化,例如:
./quantize ./ggml-model-f32.gguf ./ggml-model-Q4_K_M.gguf Q4_K_M当然如果本地资源足够,也可以不进行量化,直接进行下一步,运行模型。
运行模型
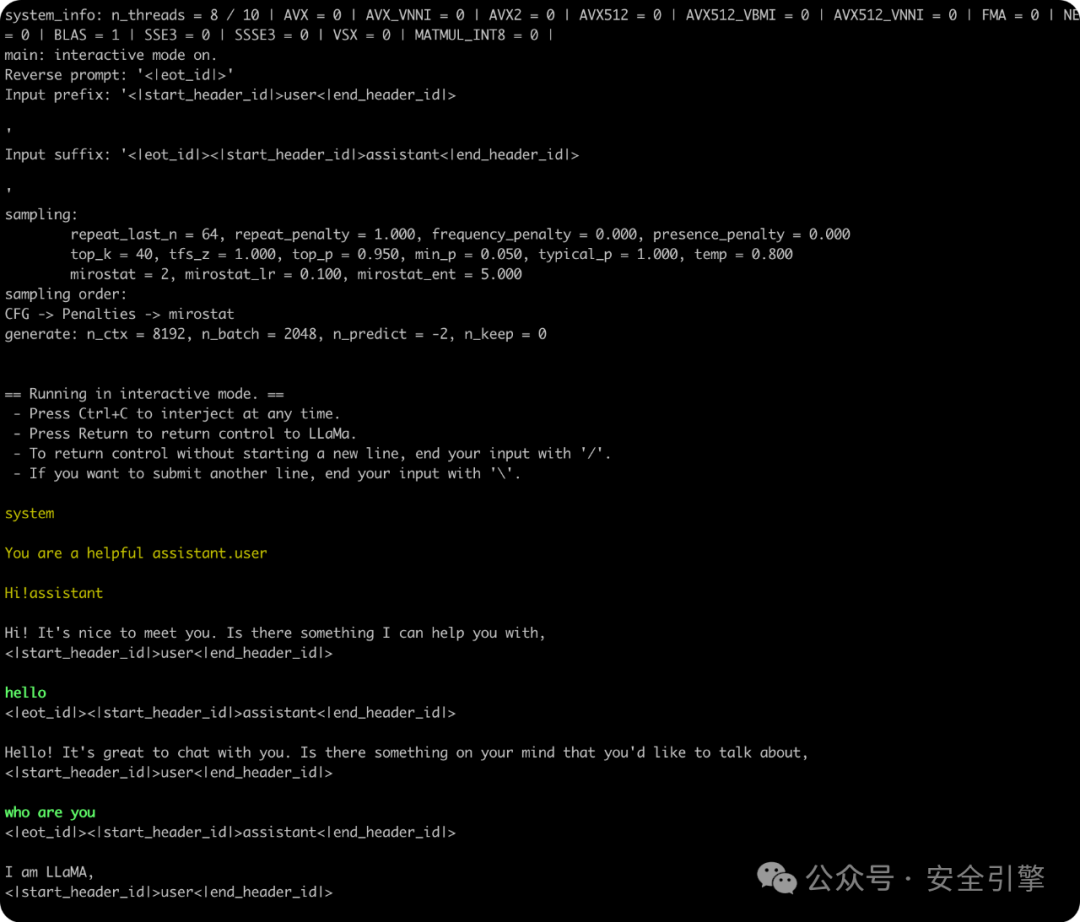
使用 llama.cpp 编译后的可执行文件,运行转换后的模型文件:
./main -m ./Meta-Llama-3-8B-Instruct/ggml-model-f32.gguf--color -e -s 0-p '<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nHi!<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n'-ngl 99 --mirostat 2 -c 8192-r '<|eot_id|>'--in-prefix '<|start_header_id|>user<|end_header_id|>\n\n'--in-suffix '<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n'-i
本地简单应用:AI 知识库
本地结合 Obsidian 笔记,可以将 Llama 3 快速应用在 AI 知识库场景。
在 Obsidian 第三方插件市场搜索并安装 Copilot,在插件设置中勾选使用 ollama 本地模型。另外启动 ollama 服务前,需要配置环境变量 OLLAMA_ORIGINS,否则 Obsidian 受 CORS 限制,无法调用本地 API 接口,会出现 “Failed to Fetch” 错误。
# 拉取 text embedding 模型ollama pull nomic-embed-text# 设置环境变量并启动 ollama 服务OLLAMA_ORIGINS=app://obsidian.md* ollama serve# MacOS 下也可以使用 launchctl 设置launchctl setenv OLLAMA_ORIGINS "app://obsidian.md*"# 如果需要设置多个 CORS Origin,可以这样配置launchctl setenv OLLAMA_ORIGINS "app://obsidian.md*,http://your-website.com:8080/"
详细配置可以参阅:
https://github.com/logancyang/obsidian-copilot/blob/master/local_copilot.md#ollama
https://github.com/ollama/ollama/blob/main/docs/faq.md#how-do-i-configure-ollama-server
注意:Obsidian 插件配置 Ollama Base URL 选项时,URL最后不需要带 / ,例如:填入 http://127.0.0.1:11434 而非 http://127.0.0.1:11434/
Command + P 打开命令面板,输入 Copilot Index,刷新 Vault for QA 的向量索引。向量库建立完成后即可体验完整功能。
如有侵权请联系:admin#unsafe.sh